18种RAG技术综合比较
我们将从一个简单的RAG方法开始,这是我们都知道的,然后测试更高级的技术,如CRAG、融合、HyDE等!

我们将从一个简单的RAG方法开始,这是我们都知道的,然后测试更高级的技术,如CRAG、融合、HyDE等!
为了保持一切简单……
我没有使用LangChain或FAISS
而是只使用基本库来代码所有技术,采用Jupyter笔记本风格,以便保持简单易学。
所有逐步的笔记本都可在这里获得。
代码库组织如下:
├── 1_simple_rag.ipynb
├── 2_semantic_chunking.ipynb
...
├── 9_rse.ipynb
├── 10_contextual_compression.ipynb
├── 11_feedback_loop_rag.ipynb
├── 12_adaptive_rag.ipynb
...
├── 17_graph_rag.ipynb
├── 18_hierarchy_rag.ipynb
├── 19_HyDE_rag.ipynb
├── 20_crag.ipynb
└── data/
└── val.json
└── AI_information.pdf
└── attention_is_all_you_need.pdf
测试查询和LLMs
为了测试每种技术,我们需要四样东西:
- 测试查询及其真实答案。
- 将应用于RAG的PDF文档。
- 嵌入生成模型。
- 响应和验证LLM。
使用Claude 3.5 Thinking模型,我创建了一个16页以上的文档AI信息,作为RAG的参考文档,并且注意力就是你所需要的论文用于评估多模型RAG。它在我的验证数据文件夹中可用,并且经过智能策划以测试我们即将使用的各种技术。
对于响应生成和验证,我们将使用LLaMA-3.2–3B Instruct来测试一个小的LLM在RAG任务中的表现如何。
对于嵌入,我们将使用TaylorAI/gte-tiny模型。
我们的测试查询是一个复杂的查询,我们将贯穿整个文档使用,其真实答案为:
测试查询:
人工智能对大规模数据集的依赖如何成为一把双刃剑?
真实答案:
它推动了快速学习和创新,同时也存在放大固有偏见的风险,因此平衡数据量与公平性和质量至关重要。
(结论)效果最好的技术!
与其放在最后,不如写在最前面,在测试了18种不同的RAG技术后。
自适应RAG是明确的赢家,得分最高为0.86。
通过智能分类查询并为每种问题类型选择最合适的检索策略,自适应RAG的表现优于其他方法。动态切换事实性、分析性、观点性和情境性策略的能力使其能够以惊人的准确性处理多样化的信息需求。
虽然像层次索引(0.84)、融合(0.83)和CRAG(0.824)等技术也表现出色,但自适应RAG的灵活性使其在现实世界应用中更具优势。
0、导入库
让我们先克隆我的仓库,以便安装所需的依赖项并开始工作。
# 克隆仓库
git clone https://github.com/FareedKhan-dev/all-rag-techniques.git
cd all-rag-techniques
安装所需的依赖项。
# 安装所需的库
pip install -r requirements.txt
1、简单RAG
让我们从最简单的RAG开始。首先,我们将可视化它是如何工作的,然后测试和评估它。
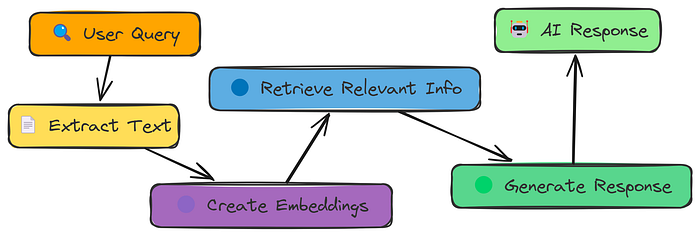
如图所示,简单RAG管道的工作方式如下:
- 从PDF中提取文本。
- 将文本分割成较小的部分。
- 将这些部分转换为数值嵌入。
- 根据查询搜索最相关的部分。
- 使用检索到的部分生成响应。
- 将响应与正确答案进行比较以评估准确性。
首先,让我们加载我们的文档,获取文本,并将其分割成可管理的部分:
# 定义PDF文件路径
pdf_path = "data/AI_information.pdf"
# 从PDF文件中提取文本,并将其分成较小的重叠片段。
extracted_text = extract_text_from_pdf(pdf_path)
text_chunks = chunk_text(extracted_text, 1000, 200)
print("文本块的数量:", len(text_chunks))
### 输出 ###
文本块的数量: 42
这段代码使用extract_text_from_pdf从我们的PDF文件中提取所有文本。然后,chunk_text将这个大块文本分割成较小的重叠部分,每个大约1000个字符。
接下来,我们需要将这些文本块转换为数值表示(嵌入):
# 为文本块创建嵌入
response = create_embeddings(text_chunks)
这里,create_embeddings接收我们的文本块列表,并使用嵌入模型为每个文本块生成一个数值嵌入。这些嵌入捕捉了文本的意义。
现在我们可以执行语义搜索,找到与我们的测试查询最相关的文本块:
# 我们的测试查询,执行语义搜索。
query = '''如何利用大规模数据集推动人工智能的发展?'''
top_chunks = semantic_search(query, text_chunks, embeddings, k=2)
然后,semantic_search将查询嵌入与文本块嵌入进行比较,返回最相似的文本块。
有了我们的相关文本块,让我们生成一个响应:
# 定义AI助手的系统提示
system_prompt = "你是一个严格基于给定上下文回答的AI助手。如果无法直接从提供的上下文中得出答案,请回答:'我没有足够的信息来回答这个问题。'"
# 基于顶级文本块创建用户提示,并生成AI响应。
user_prompt = "\n".join([f"上下文 {i + 1}:\n{chunk}\n========\n" for i, chunk in enumerate(top_chunks)])
user_prompt = f"{user_prompt}\n问题: {query}"
ai_response = generate_response(system_prompt, user_prompt)
print(ai_response.choices[0].message.content)
这段代码将检索到的文本块格式化为大型语言模型(LLM)的提示。generate_response函数将此提示发送给LLM,后者根据提供的上下文生成答案。
最后,让我们看看我们的简单RAG表现如何:
# 定义评估系统的系统提示
evaluate_system_prompt = "你是一个智能评估系统,负责评估AI助手的响应。如果AI助手的回答非常接近真实答案,则评分1;如果回答不正确或与真实答案不符,则评分0;如果回答部分符合真实答案,则评分0.5。"
# 创建评估提示并生成评估响应
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{ai_response.choices[0].message.content}\n真实响应:{data[0]['ideal_answer']}\n{evaluate_system_prompt}"
评估响应 = generate_response(evaluate_system_prompt, evaluation_prompt)
print(评估响应.choices[0].message.content)
### 输出 ###
... 因此,0.3的得分与真实响应不太接近,也不完全一致。
嗯……简单的RAG响应低于平均水平
让我们继续下一个方法。
2、语义分块
在我们的简单RAG方法中,我们只是将文本切成固定大小的部分。这相当粗糙!它可能会将一句话分成两半,或者将不相关的内容组合在一起。
语义分块的目标是更聪明一些。它不是基于固定的大小来分割文本,而是尝试根据意义来分割文本,将语义相关的句子组合在一起。
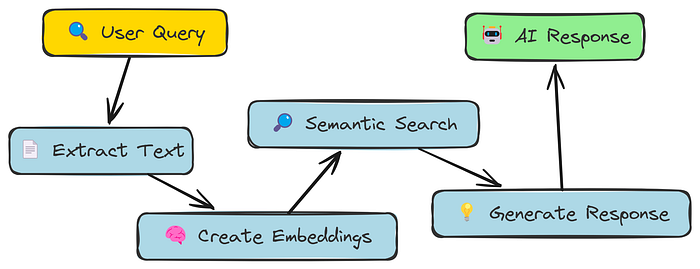
这个想法是,如果句子讨论的是相似的事情,它们应该在同一部分中。我们将使用相同的嵌入模型来判断它们之间的相似性。
# 将提取的文本拆分为句子(基本拆分)
sentences = extracted_text.split(". ")
# 为每个句子生成嵌入
embeddings = [get_embedding(sentence) for sentence in 句子]
print(f"生成了{len(embeddings)}个句子嵌入。")
### 输出 ###
233
这段代码将我们的extracted_text拆分为单独的句子。然后为每个单独的句子创建嵌入。
现在,我们将计算相邻句子之间的相似度:
# 计算相邻句子之间的相似度
similarities = [cosine_similarity(embeddings[i], embeddings[i + 1]) for i in range(len(embeddings) - 1)]
这个cosine_similarity函数(我们之前定义过的)告诉我们两个嵌入之间的相似程度。得分为1表示它们非常相似,得分为0表示它们完全不同。我们对每一对相邻句子计算这个得分。
语义分块是决定在哪里将文本分割成块的方法。我们将使用“断点”方法。这里我们使用百分位法,寻找相似度的大幅下降:
# 使用百分位法和阈值为90计算断点
breakpoints = compute_breakpoints(similarities, method="percentile", threshold=90)
compute_breakpoints函数,使用“百分位”方法,识别句子之间相似度显著下降的点。这些就是我们的块边界。
现在我们可以创建我们的语义块了:
# 使用split_into_chunks函数创建块
text_chunks = split_into_chunks(sentences, breakpoints)
print(f"语义块的数量:{len(text_chunks)}")
### 输出 ###
语义块的数量:145
split_into_chunks函数接受我们的句子列表和找到的断点,并将句子分组到块中。
接下来,我们需要为这些块创建嵌入:
# 使用create_embeddings函数创建块嵌入
chunk_embeddings = create_embeddings(text_chunks)
生成响应的时间到了:
# 根据顶级块创建用户提示
user_prompt = "\n".join([f"上下文{i + 1}:\n{chunk}\n=====================================\n" for i, chunk in enumerate(top_chunks)])
user_prompt = f"{user_prompt}\n问题:{query}"
# 生成AI响应
ai_response = generate_response(system_prompt, user_prompt)
print(ai_response.choices[0].message.content)
最后进行评估:
# 创建评估提示,结合用户查询、AI响应、真实响应和评估系统提示
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{ai_response.choices[0].message.content}\n真实响应:{data[0]['ideal_answer']}\n{evaluate_system_prompt}"
# 使用评估系统提示和评估提示生成评估响应
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
# 打印评估响应
print(evaluation_response.choices[0].message.content)
### 输出
根据评估标准,
我会给AI助手响应一个0.2的分数。
评估者给出的分数仅为0.2
虽然语义分块在理论上听起来不错,但它在这里并没有帮助我们。事实上,我们的得分比简单的固定大小分块还要低!
这表明仅仅改变分块策略并不能保证成功。我们需要在方法上更加精明。让我们在下一节尝试其他方法。
3、上下文增强检索
我们看到,尽管语义分块在原则上是一个好主意,但它实际上并没有改善我们的结果。
一个问题在于,即使是语义定义的块也可能过于集中。它们可能遗漏了周围文本的关键上下文。
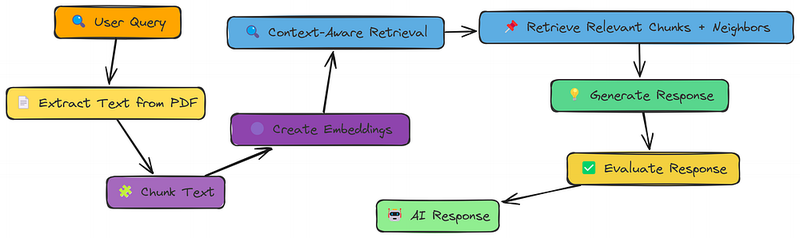
上下文增强检索解决了这个问题,通过获取最佳匹配块及其邻居。
让我们看看如何在代码中实现这一点。我们需要一个新的函数context_enriched_search来处理检索:
def context_enriched_search(query, text_chunks, embeddings, k=1, context_size=1):
"""
检索最相关的块及其邻近块。
"""
# 将查询转换为嵌入向量
query_embedding = create_embeddings(query).data[0].embedding
similarity_score = []
# 计算查询与每个文本块嵌入之间的相似度得分
for i, chunk_embedding in enumerate(embeddings):
# 计算查询嵌入与当前块嵌入之间的余弦相似度
similarity_score = cosine_similarity(np.array(query_embedding), np.array(chunk_embedding.embedding))
# 将索引和相似度得分存储为元组
similarity_scores.append((i, similarity_score))
# 按降序排序相似度得分(最高相似度优先)
similarity_scores.sort(key=lambda x: x[1], reverse=True)
# 获取最相关块的索引
top_index = similarity_scores[0][0]
# 定义上下文包含的范围
# 确保我们不会低于0或超出文本块的长度
start = max(0, top_index - context_size)
end = min(len(text_chunks), top_index + context_size + 1)
# 返回相关块及其邻近上下文块
return [text_chunks[i] for i in range(start, end)]
核心逻辑与我们之前的search类似,但不是只返回单个最佳块,我们抓取一个“窗口”中的块。上下文大小控制我们在两侧包括多少个块。
让我们在RAG管道中使用这个。我们将跳过文本提取和分块步骤,因为这些与简单RAG相同。
我们将使用固定大小的块,就像在简单RAG部分一样,并保持块_size = 1000和重叠 = 200。
现在生成响应,与之前相同:
# 根据顶级块创建用户提示
user_prompt = "\n".join([f"上下文{i + 1}:\n{chunk}\n=====================================\n" for i, chunk in enumerate(top_chunks)])
user_prmpt = f"{user_prompt}\n问题:{query}"
# 生成AI响应
ai_response = generate_response(system_prompt, user_prompt)
print(ai_response.choices[0].message.content)
最后进行评估:
# 创建评估提示并生成评估响应
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{ai_response.choices[0].message.content}\n真实响应:{data[0]['ideal_answer']}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出 ###
根据评估标准,
我会给AI助手响应一个0.6的分数。
这次我们得到了0.6的评估分数!
这是一个显著的改进,超过了简单RAG(0.5)和语义分块(0.1)!
通过包括邻近块,我们给了LLM更多的上下文来工作,它产生了一个更好的答案。
我们仍然没有完美,但我们正在朝着正确的方向前进。这显示了上下文对于检索的重要性。
4、上下文增强块标题
我们已经看到添加上下文通过包括邻近块是有帮助的。但如果块本身的内容缺少重要信息怎么办?
通常,文档有明确的结构——标题、小标题等,提供了关键上下文。上下文增强块标题(CCH)利用了这种结构。
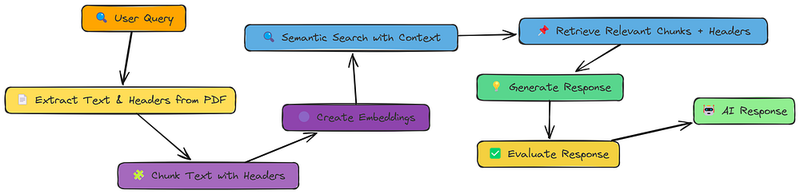
这个想法很简单:在我们甚至创建嵌入之前,我们前置一个描述性的标题到每个块中。这个标题就像一个微型摘要,给检索系统(和LLM)提供了更多可以利用的信息。
generate_chunk_header函数将分析每个文本块并生成一个简洁且有意义的标题,总结其内容。这有助于高效地组织和检索相关信息。
# 分块提取的文本,这次生成标题
text_chunks_with_headers = chunk_text_with_headers(extracted_text, 1000, 200)
# 打印样本以查看其外观
print("Sample Chunk with Header:")
print("Header:", text_chunks_with_titles[0]['header']])
print("Content:", text_chunks_with_headers[0]['text'])
### OUTPUT ###
Sample Chunk with Header:
Header: A Description about AI Impact
Content: AI has been an important part of society since ...看看现在每个块都有标题和原始文本了吗?这就是我们将使用的增强数据。
现在开始嵌入。我们将为标题和文本创建嵌入:
# Generate embeddings for each chunk (both header and text)
embeddings = []
for chunk in tqdm(text_chunks_with_headers, desc="Generating embeddings"):
text_embedding = create_embeddings(chunk["text"])
header_embedding = create_embeddings(chunk["header"])
embeddings.append({"header": chunk["header"], "text": chunk["text"], "embedding": text_embedding, "header_embedding": header_embedding})我们循环遍历块,获取标题和文本的嵌入,并将所有内容存储在一起。这为检索系统提供了两种将块与查询匹配的方法。
由于 semantic_search 已经可以使用嵌入,我们只需确保标题和文本块都正确嵌入即可。这样,当我们执行搜索时,模型可以同时考虑高级摘要(标题)和详细内容(块文本)以找到最相关的信息。
现在,让我们修改检索步骤,不仅返回匹配的块,还返回它们的标题,以获得更好的上下文并生成响应。
# Perform semantic search using the query and the new embeddings
top_chunks = semantic_search(query, embeddings, k=2)
# Create the user prompt based on the top chunks. note: no need to add header
# because the context is already created using header and chunk
user_prompt = "\n".join([f"Context {i + 1}:\n{chunk['text']}\n=====================================\n" for i, chunk in enumerate(top_chunks)])
user_prompt = f"{user_prompt}\nQuestion: {query}"
# Generate AI response
ai_response = generate_response(system_prompt, user_prompt)
print(ai_response.choices[0].message.content)
### OUTPUT ###
Evaluation Score: 0.5这次,我们的评估分数是 0.5!
通过添加这些上下文标题,我们让系统有更好的机会找到正确的信息,让 LLM 有更好的机会生成完整而准确的答案。
这显示了在数据进入检索系统之前增强数据的威力。我们没有改变核心 RAG 管道,但我们让数据本身更具信息量。
5、文档增强
我们已经了解了在块周围添加上下文(使用邻居或标题)可以如何提供帮助。现在,让我们尝试一种不同的增强方式:从文本块中生成问题。
这个想法是,这些问题可以充当替代“查询”,可能比原始文本块本身更符合用户的意图。
- 文档增强工作流程(由 Fareed Khan 创建)
- 我们在分块和嵌入创建之间添加了此步骤。我们可以简单地使用
generate_questions函数来实现这一点。它需要一个text_chunk并返回可以使用它生成的一些问题。
我们在分块和嵌入创建之间添加了这一步。我们可以简单地使用 generate_questions 函数来实现这一点。它接受一个 text_chunk 并返回一些可以使用它生成的问题。
首先让我们看看如何通过问题生成来实现文档增强:
# Process the document (extract text, create chunks, generate questions, build vector store)
text_chunks, vector_store = process_document(
pdf_path,
chunk_size=1000,
chunk_overlap=200,
questions_per_chunk=3
)
print(f"Vector store contains {len(vector_store.texts)} items")
### OUTPUT ###
Vector store contains 214 items这里, process_document 函数完成了所有工作。它接受 pdf_path、 chunk_size、 overlap 和 questions_per_chunk 并返回一个 vector_store。
现在, vector_store 不仅包含文档的嵌入,还包含生成的问题的嵌入。
现在,我们可以像以前一样使用这个 vector_store 执行语义搜索。我们在这里使用一个简单的函数来查找相似的向量。
# Perform semantic search to find relevant content
search_results = semantic_search(query, vector_store, k=5)
print("Query:", query)
print("\nSearch Results:")
# Organize results by type
chunk_results = []
question_results = []
for result in search_results:
if result["metadata"]["type"] == "chunk":
chunk_results.append(result)
else:
question_results.append(result这里的重要变化是我们如何处理搜索结果。现在我们的向量存储中有两种类型的项目:原始文本块和生成的问题。此代码将它们分开,因此我们可以看到哪种类型的内容与查询最匹配。
最后的步骤,生成上下文,然后进行评估:
# Prepare context from search results
context = prepare_context(search_results)
# Generate response
response_text = generate_response(query, context)
# Get reference answer from validation data
reference_answer = data[0]['ideal_answer']
# Evaluate the response
evaluation = evaluate_response(query, response_text, reference_answer)
print("\nEvaluation:")
print(evaluation)
### OUTPUT ###
Based on the evaluation criteria, I would assign a
score of 0.8 to the AI assistants response.我们的评估显示得分约为 0.8!
生成问题并将其添加到可搜索索引中又一次提升了我们的性能。
似乎有时问题比原始文本块更能代表信息需求。
6、查询转换
到目前为止,我们一直专注于改进 RAG 系统使用的数据。但是查询本身呢?
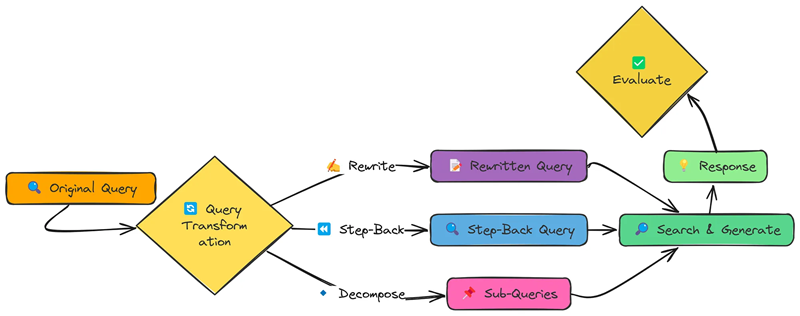
通常,用户提出问题的方式并不是搜索知识库的最佳方式。查询转换旨在解决此问题。我们将探索三种不同的方法:
- 查询重写:使查询更具体、更详细。
- 后退提示:创建更广泛、更通用的查询以检索背景上下文。
- 子查询分解:将复杂查询分解为多个更简单的子查询。
让我们看看这些转换的实际效果。我们将使用我们的标准测试查询:
# Query Rewriting
rewritten_query = rewrite_query(query)
# Step-back Prompting
step_back_query = generate_step_back_query(query)generate_step_back_query 与重写相反:它创建更广泛的查询,可能会检索有用的背景信息。
最后,子查询分解:
# Sub-query Decomposition
sub_queries = decompose_query(query, num_subqueries=4)decompose_query 将原始查询分解为几个更小、更集中的问题。其理念是,这些子查询结合起来,可能比任何单个查询更好地涵盖原始查询的意图。
现在,要了解这些转换如何影响我们的 RAG 系统,让我们使用一个结合了所有先前方法的函数:
def rag_with_query_transformation(pdf_path, query, transformation_type=None):
"""
Run complete RAG pipeline with optional query transformation.
Args:
pdf_path (str): Path to PDF document
query (str): User query
transformation_type (str): Type of transformation (None, 'rewrite', 'step_back', or 'decompose')
Returns:
Dict: Results including query, transformed query, context, and response
"""
# Process the document to create a vector store
vector_store = process_document(pdf_path)
# Apply query transformation and search
if transformation_type:
# Perform search with transformed query
results = transformed_search(query, vector_store, transformation_type)
else:
# Perform regular search without transformation
query_embedding = create_embeddings(query)
results = vector_store.similarity_search(query_embedding, k=3)
# Combine context from search results
context = "\n\n".join([f"PASSAGE {i+1}:\n{result['text']}" for i, result in enumerate(results)])
# Generate response based on the query and combined context
response = generate_response(query, context)
# Return the results including original query, transformation type, context, and response
return {
"original_query": query,
"transformation_type": transformation_type,
"context": context,
"response": response
}evaluate_transformations 函数通过不同的查询转换技术(重写、后退和分解)运行原始查询,然后比较它们的输出。
这有助于我们了解哪种方法可以检索最相关的信息以获得更好的响应。
# Run evaluation
evaluation_results = evaluate_transformations(pdf_path, query, reference_answer)
print(evaluation_results)
### OUTPUT ###
Evaluation Score: 0.5评估分数为 0.5。
这表明我们的查询转换技术并没有始终优于更简单的方法。
虽然查询转换可能很强大,但它们并不是灵丹妙药。 有时,原始查询已经是格式良好的,试图“改进”它实际上可能会使情况变得更糟。
7、重新排序器
我们尝试改进数据(使用分块策略)和查询(使用转换)。 现在,让我们关注检索过程本身。 简单的相似性搜索通常会返回相关和不相关的结果。
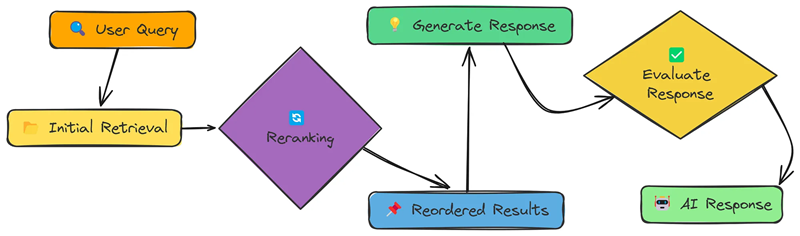
重新排序是第二遍,它重新排序最初检索到的结果,将最佳结果放在最上面。
rerank_with_llm 函数获取最初检索到的块,并使用 LLM 根据相关性对其进行重新排序。这有助于确保最有用的信息首先出现。
重新排序后,最后一个函数(我们称之为 generate_final_response)获取重新排序的块,将它们格式化为提示,然后将它们发送到 LLM 以生成最终响应。
def rag_with_reranking(query, vector_store, reranking_method="llm", top_n=3, model="meta-llama/Llama-3.2-3B-Instruct"):
"""
Complete RAG pipeline incorporating reranking.
"""
# Create query embedding
query_embedding = create_embeddings(query)
# Initial retrieval (get more than we need for reranking)
initial_results = vector_store.similarity_search(query_embedding, k=10)
# Apply reranking
if reranking_method == "llm":
reranked_results = rerank_with_llm(query, initial_results, top_n=top_n)
elif reranking_method == "keywords":
reranked_results = rerank_with_keywords(query, initial_results, top_n=top_n) # we are not using it.
else:
# No reranking, just use top results from initial retrieval
reranked_results = initial_results[:top_n]
# Combine context from reranked results
context = "\n\n===\n\n".join([result["text"] for result in reranked_results])
# Generate response based on context
response = generate_response(query, context, model)
return {
"query": query,
"reranking_method": reranking_method,
"initial_results": initial_results[:top_n],
"reranked_results": reranked_results,
"context": context,
"response": response
}它需要一个查询、一个 vector_store(我们已经创建了)和一个 reranking_method。我们使用“llm”进行基于 LLM 的重新排名。该函数执行初始检索,调用 rerank_with_llm 重新排序结果,然后生成响应。
rerank_with_keywords 在笔记本中定义,但我在这里没有使用它。
让我们运行它,看看它是否能改善我们的结果:
# Run RAG with LLM-based reranking
llm_reranked_result = rag_with_reranking(query, vector_store, reranking_method="llm")
# Evaluate.
evaluation_prompt = f"User Query: {query}\nAI Response:\n{llm_reranked_result['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### OUTPUT ###
Evaluation score is 0.7我们的评估分数现在约为 0.7!
重新排序给我们带来了明显的改进。通过使用 LLM 直接对每个检索到的文档的相关性进行评分,我们能够优先考虑用于响应生成的最佳信息。
这是一种强大的技术,可以显著提高 RAG 系统的质量。
8、RSE
我们一直专注于单个片段,但有时最好的信息分散在多个连续的片段中。相关段落提取(RSE)解决了这个问题。
与其仅仅抓取前k个片段,RSE尝试识别并提取整个相关的文本段。

让我们看看如何在现有的管道中实现这一点,我们已经在使用定义好的 RSE 函数。我们添加了一个函数调用 rag_with_rse,它接收 pdf_path 和 query 并返回响应。
我们结合多个函数调用来执行 RSE。
# 使用RSE运行RAG
rse_result = rag_with_rse(pdf_path, query)
这一行代码做了很多工作!它:
- 处理文档(提取文本、分块、创建嵌入,所有这些都由
rag_with_rse内部处理)。 - 根据与查询的相关性和位置计算“块值”。
- 使用一种聪明的算法找到最佳的连续块集合。
- 将这些块组合成上下文。
- 基于该上下文生成响应。
现在,进行评估:
# 评估
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{rse_result['response']}\n真实响应:{reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出 ###
然而,标准检索的响应包括...
0.8 是我会给AI响应的分数
我们达到了大约0.8的分数!
通过关注相关文本的连续段落,RSE为LLM提供了更连贯和完整的上下文,从而导致更准确和全面的响应。
这表明如何选择和呈现信息给LLM和选择什么信息一样重要。
9、上下文压缩
我们一直在添加越来越多的上下文,相邻的块、生成的问题、整个段落。但有时,少即是多。
LLM有有限的上下文窗口,塞满无关信息可能会损害性能。

上下文压缩是关于选择性的。我们检索到足够的上下文,但随后对其进行压缩,只保留与查询直接相关的部分。
这里的关键区别在于生成之前的**“上下文压缩”**步骤。我们并没有改变检索的内容,而是在传递给LLM之前对其进行精炼。
我们在这里使用一个函数调用 rag_with_compression,它接收 query 和其他参数并实现上下文压缩。内部使用LLM分析检索到的块并提取仅与 query 直接相关的句子或段落。
让我们看看它的实际效果:
def rag_with_compression(pdf_path, query, k=10, compression_type="selective", model="meta-llama/Llama-3.2-3B-Instruct"):
"""
具有上下文压缩的RAG(检索增强生成)管道。
参数:
pdf_path (str): PDF文档的路径。
query (str): 用户查询以进行检索。
k (int): 要检索的相关块数。默认值为10。
compression_type (str): 对检索到的块应用的压缩类型。默认值为"selective"。
model (str): 用于响应生成的语言模型。默认值为"meta-llama/Llama-3.2-3B-Instruct"。
返回:
dict: 包含查询、原始和压缩块、压缩统计信息以及最终响应的字典。
"""
print(f"\n=== RAG WITH COMPRESSION ===\n查询:{query} | 压缩:{compression_type}")
# 处理文档以提取、分块和嵌入文本
vector_store = process_document(pdf_path)
# 根据查询相似度检索前k个相关块
results = vector_store.similarity_search(create_embeddings(query), k=k)
retrieved_chunks = [r["text"] for r in results]
# 对检索到的块应用压缩
compressed = batch_compress_chunks(retrieved_chunks, query, compression_type, model)
# 过滤掉空的压缩块;如果全部为空,则回退到原始块
compressed_chunks, compression_ratios = zip([(c, r) for c, r in compressed if c.strip()] or [(chunk, 0.0) for chunk in retrieved_chunks])
# 将压缩块组合成用于响应生成的上下文
context = "\n\n---\n\n".join(compressed_chunks)
# 使用压缩上下文生成响应
response = generate_response(query, context, model)
print(f"\n=== 响应 ===\n{response}")
# 返回详细结果
return {
"query": query,
"original_chunks": retrieved_chunks,
"compressed_chunks": compressed_chunks,
"compression_ratios": compression_ratios,
"context_length_reduction": f"{sum(compression_ratios)/len(compression_ratios):.2f}%",
"response": response
}
rag_with_compression 提供了不同的压缩类型选项:
- “selective” 只保留直接相关的句子。
- “summary” 创建一个简短的摘要,重点放在查询上。
- “extraction” 只提取包含答案的句子(非常严格)。
现在,要运行压缩,我们使用以下代码:
# 使用上下文压缩运行RAG(使用'selective'模式)
compression_result = rag_with_compression(pdf_path, query, compression_type="selective")
# 评估。
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{compression_result['response']}\n真实响应:{reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出 ###
评估分数为0.75
这给了我们大约0.75的分数。
上下文压缩是一种强大的技术,因为它平衡了广度(初始检索获取大量信息)和专注(压缩去除噪声)。
通过只给LLM提供最相关的信息,我们通常能得到更简洁和准确的答案。
10、反馈循环
到目前为止,我们看到的所有技术都是“静态”的,它们不会从错误中学习。反馈循环改变了这一点。
这个想法很简单:
- 用户对 RAG 系统的响应提供反馈(例如,好/坏、相关/不相关)。
- 系统存储此反馈。
- 未来的检索将使用此反馈进行改进。
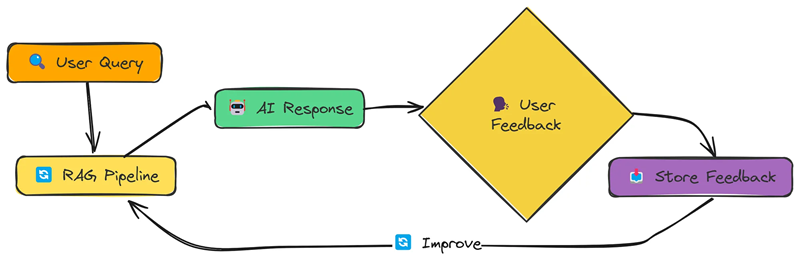
我们可以使用函数调用full_rag_workflow实现一个反馈回路。以下是该函数的定义。
def full_rag_workflow(pdf_path, query, feedback_data=None, feedback_file="feedback_data.json", fine_tune=False):
"""
执行完整的RAG工作流,并集成反馈以实现持续改进。
"""
# 第一步:如果未显式提供反馈数据,则加载历史反馈以进行相关性调整
if feedback_data is None:
feedback_data = load_feedback_data(feedback_file)
print(f"从{feedback_file}加载了{len(feedback_data)}条反馈记录")
# 第二步:通过提取、分块和嵌入管道处理文档
chunks, vector_store = process_document(pdf_path)
# 第三步:通过整合高质量的历史交互来微调向量索引
# 这会从成功的问答对中生成增强的可检索内容
if fine_tune and feedback_data:
vector_store = fine_tune_index(vector_store, chunks, feedback_data)
# 第四步:执行带有反馈感知检索的核心RAG
# 注意:这依赖于在其他地方定义的`rag_with_feedback_loop`函数
result = rag_with_feedback_loop(query, vector_store, feedback_data)
# 第五步:收集用户反馈以改进未来的表现
print("\n=== 您是否愿意对这个响应提供反馈? ===")
print("评价相关性(1-5,5表示最相关):")
relevance = input()
print("评价质量(1-5,5表示最高质量):")
quality = input()
print("有任何评论吗?(可选,按Enter跳过)")
comments = input()
# 第六步:将反馈格式化为结构化数据
feedback = get_user_feedback(
query=query,
response=result["response"],
relevance=int(relevance),
quality=int(quality),
comments=comments
)
# 第七步:持久化反馈以实现系统的持续学习
store_feedback(feedback, feedback_file)
print("反馈已记录。感谢您的参与!")
return result
此full_rag_workflow函数做了以下几件事:
- 加载现有反馈: 它检查是否存在
feedback_data.json文件并加载任何先前的反馈。 - 运行RAG管道: 这一部分与之前的操作类似。
- 请求反馈: 它提示用户对响应的相关性和质量进行评分。
- 存储反馈: 它将反馈保存到
feedback_data.json文件中。
如何实际利用此反馈来改进检索的具体机制更为复杂,并且发生在像fine_tune_index、adjust_relevance_scores这样的函数内部(出于简洁性省略)。但关键思想是,好的反馈可以提升某些文档的相关性,而坏的反馈则可以降低它。
让我们运行一个简化的版本,假设我们没有现有的反馈:
# 我们没有之前的反馈,因此“fine_tune=False”
result = full_rag_workflow(pdf_path=pdf_path, query=query, fine_tune=False)
# 评估。
evaluation_prompt = f"用户查询: {query}\nAI响应:\n{result['response']}\n真实响应: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出 ###
评估分数为0.7,因为……
我们看到分数约为0.7!
这不是一个巨大的跳跃,这是预期的。反馈回路随着时间的推移改进系统,通过重复交互实现。这部分只是展示了机制。
真正的力量来自于积累反馈并用于优化检索过程。这使RAG系统能够根据接收到的查询类型进行自适应和个性化。
11、自适应RAG
我们探索了多种改进RAG的方法:更好的分块、添加上下文、转换查询、重新排名,甚至引入反馈。
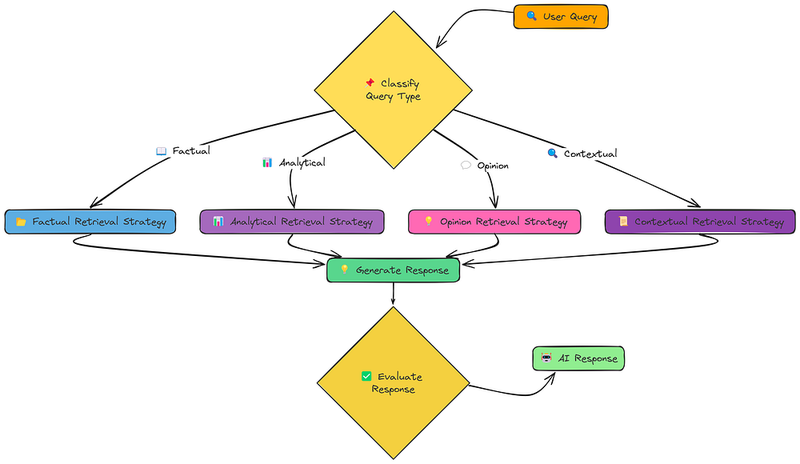
但如果最佳技术取决于所问问题的类型呢?这就是自适应RAG背后的想法。
我们在这里使用四种不同的策略:
- 事实策略: 专注于检索精确的事实和数字。
- 分析策略: 力求全面覆盖主题,探索不同方面。
- 观点策略: 尝试收集主观问题的不同观点。
- 上下文策略: 结合用户特定的上下文以定制检索。
让我们看看它是如何工作的。我们将使用一个名为rag_with_adaptive_retrieval的函数来处理整个过程:
def rag_with_adaptive_retrieval(pdf_path, query, k=4, user_context=None):
"""
带有自适应检索的完整RAG管道。
"""
print("\n=== 带有自适应检索的RAG ===")
print(f"查询: {query}")
# 处理文档以提取文本、分块并创建嵌入
chunks, vector_store = process_document(pdf_path)
# 对查询进行分类以确定其类型
query_type = classify_query(query)
print(f"查询分类为: {query_type}")
# 根据查询类型使用自适应检索策略检索文档
retrieved_docs = adaptive_retrieval(query, vector_store, k, user_context)
# 根据查询、检索到的文档和查询类型生成响应
response = generate_response(query, retrieved_docs, query_type)
# 将结果编译成字典
result = {
"query": query,
"query_type": query_type,
"retrieved_documents": retrieved_docs,
"response": response
}
print("\n=== 响应 ===")
print(response)
return result
它首先使用一个名为classify_query的函数对查询进行分类,该函数与其他辅助函数一起定义。
基于识别的类型,它选择并执行适当的专门检索策略(factual_retrieval_strategy、analytical_retrieval_strategy、opinion_retrieval_strategy或contextual_retrieval_strategy)。
最后,它使用generate_response根据检索到的文档生成响应。
该函数返回一个包含结果的字典,包括query、query type、retrieved documents和generated response。
让我们使用这个函数并对其进行评估:
# 运行自适应RAG管道
result = rag_with_adaptive_retrieval(pdf_path, query)
# 评估。
evaluation_prompt = f"用户查询: {query}\nAI响应:\n{result['response']}\n真实响应: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出 ###
评估分数为0.86
我们这次得到了大约0.856的分数。
通过根据具体查询类型调整我们的检索策略,我们可以比采用一刀切的方法获得显著更好的结果。这突显了理解用户意图并相应地调整RAG系统的重要性。
自适应RAG不是一个固定的过程,而是一个框架,它赋予我们根据查询选择最佳策略的功能。
12、自我RAG
到目前为止,我们的RAG系统大多是反应性的。它们接收查询,检索信息并生成响应。自我RAG采取了不同的方法:它是主动的和反思的。
它不仅检索和生成,还思考是否需要检索,检索什么以及如何使用检索到的信息。
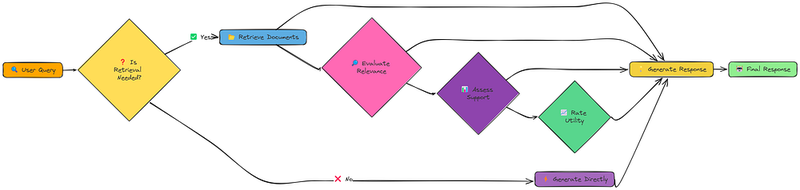
这些 “反思”步骤使自我RAG比传统的RAG更加动态和适应性强。它可以决定:
- 完全跳过检索。
- 使用不同的策略多次检索。
- 抛弃无关信息。
- 优先考虑支持充分且有用的信息。
自我RAG的核心在于其生成“反思标记”的能力。这些是模型用来推理其自身过程的特殊标记。例如,它使用不同的标记来表示retrieval_needed、relevance、support_rating和utility_ratings。
模型结合这些标记来决定何时需要检索,何时不需要,以及LLM应如何生成最终响应。
首先,决定是否需要检索:
def determine_if_retrieval_needed(query):
"""
(示例说明 - 不完全功能)
确定给定查询是否需要检索。
"""
system_prompt = """你是一个AI助手,负责确定是否需要检索来回答查询。
对于事实性问题、特定信息请求或关于事件、人物或概念的问题,回答“Yes”。
对于意见、假设情景或简单查询具有常识性的问题,回答“No”。
只回答“Yes”或“No”。“""
user_prompt = f"查询: {query}\n\n检索是否准确回答此查询的必要条件?"
```ly?"
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-3B-Instruct",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0
)
answer = response.choices[0].message.content.strip().lower()
return "yes" in answer
这个 determine_if_retrieval_needed 函数(再次简化)使用大型语言模型来判断是否需要外部信息。
- 对于一个事实性问题,比如 “法国的首都是什么?”,它可能会返回
False(LLM 很可能已经知道这个答案)。 - 对于一个创造性任务,比如 “写一首诗……”,它也可能会返回
False。 - 但对于更复杂或特定的问题,它会返回
True。
以下是相关性评估的简化示例:
def evaluate_relevance(query, context):
"""
(示意示例 - 不完全功能)
评估上下文对查询的相关性。
"""
system_prompt = """你是一名AI助手。判断文档是否与查询相关。
只回答“相关”或“不相关”。”"""
user_prompt = f"""查询:{query}
文档内容:
{context[:500]}... [截断]
这个文档是否与查询相关?只回答“相关”或“不相关”。
"""
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-3B-Instruct",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0
)
answer = response.choices[0].message.content.strip().lower()
return answer
这个 evaluate_relevance 函数(再次简化)使用大型语言模型来判断检索到的文档是否与 query 相关。
这允许 Self-RAG 在生成响应之前过滤掉无关的文档。
最后,我们可以这样调用所有这些功能:
# 我们可以调用 `self_rag` 函数进行自适应RAG,并且它会自动决定何时检索以及何时不需要。
result = self_rag(query, vector_store)
print(result["response"])
### 输出 ###
AI响应的评估得分为0.65
我们得到了一个分数为0.6左右。
这反映了以下几点:
- 自适应RAG有很大的潜力,但完整的实现是复杂的。
- 即使是“检索是否需要?”这一部分,我们也展示了,有时可能会出错。
- 我们没有展示完整的“反思”过程,所以我们不能声称更高的分数。
关键点在于,自适应RAG 是为了让RAG系统更加智能和自适应。这是朝着能让大型语言模型推理其自身知识和检索需求的方向迈进了一步。
13、知识图谱
到目前为止,我们的RAG系统将文档视为独立片段的集合。但如果信息是相互关联的呢?如果理解一个概念需要理解相关的概念呢?这就是知识图谱的作用所在。
与其将信息视为平铺的片段,知识图谱将信息组织成一个网络:
- 节点: 表示概念、实体或信息片段(就像我们的文本片段)。
- 边: 表示这些节点之间的关系。
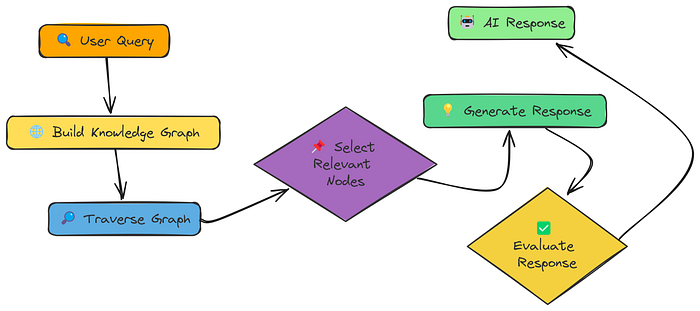
核心思想是通过遍历这个网络,不仅可以找到直接相关的信息,还可以找到提供关键上下文的间接相关的信息。
让我们看看核心步骤的简化代码是如何工作的:首先构建知识图谱:
def build_knowledge_graph(chunks):
"""
使用嵌入和概念提取从文本片段构建知识图谱。
参数:
chunks (list of dict): 包含“text”字段的文本片段列表。
返回:
tuple: (具有文本片段作为节点的图,嵌入列表)
"""
graph, texts = nx.Graph(), [c["text"] for c in chunks]
embeddings = create_embeddings(texts) # 计算嵌入
# 添加包含提取的概念和嵌入的节点
for i, (chunk, emb) in enumerate(zip(chunks, embeddings)):
graph.add_node(i, text=chunk["text"], concepts := extract_concepts(chunk["text"]), embedding=emb)
# 根据共享概念和嵌入相似度创建边
for i, j in ((i, j) for i in range(len(chunks)) for j in range(i + 1, len(chunks))):
if shared_concepts := set(graph.nodes[i]["concepts"]) & set(graph.nodes[j]["concepts"]):
sim = np.dot(embeddings[i], embeddings[j]) / (np.linalg.norm(embeddings[i]) np.linalg.norm(embeddings[j]))
weight = 0.7 * sim + 0.3 * (len(shared_concepts) / min(len(graph.nodes[i]["concepts"]), len(graph.nodes[j]["concepts"])))
if weight > 0.6:
graph.add_edge(i, j, weight=weight, similarity=sim, shared_concepts=list(shared_concepts))
print(f"图已构建:{graph.number_of_nodes()}个节点,{graph.number_of_edges()}条边")
return graph, embeddings
它接受一个 query、graph 和 embeddings,并返回相关节点列表和遍历路径。
最后,我们有 graph_rag_pipeline 使用这两个函数:
def graph_rag_pipeline(pdf_path, query, chunk_size=1000, chunk_overlap=200, top_k=3):
"""
完整的知识图谱RAG管道,从文档到答案。
"""
# 从PDF文档中提取文本
text = extract_text_from_pdf(pdf_path)
# 将提取的文本分割成重叠的片段
chunks = chunk_text(text, chunk_size, chunk_overlap)
# 从文本片段构建知识图谱
graph, embeddings = build_knowledge_graph(chunks)
# 遍历知识图谱以查找与查询相关的相关信息
relevant_chunks, traversal_path = traverse_graph(query, graph, embeddings, top_k)
# 基于查询和相关片段生成响应
response = generate_response(query, relevant_chunks)
# 返回查询、响应、相关片段、遍历路径和图谱
return {
"query": query,
"response": response,
"relevant_chunks": relevant_chunks,
"traversal_path": traversal_path,
"graph": graph
}
让我们用这个来生成响应:
# 执行知识图谱RAG管道以处理文档并回答查询
results = graph_rag_pipeline(pdf_path, query)
# 评估。
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{results['response']}\n真实响应:{reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出
0.78
我们得到了大约0.78的分数。
知识图谱RAG虽然没有超越简单方法,但它可以捕捉信息之间的 关系,而不仅仅是单独的信息片段。

这对于需要理解概念之间联系的复杂查询特别有帮助。
14、层次索引
我们已经探讨了改进RAG的各种方式:更好的分块、上下文丰富化、查询转换、重新排名,甚至基于图的检索。但有一个基本权衡:
- 小片段:适合精确匹配,但失去上下文。
- 大片段:保留上下文,但可能导致相关性较低的检索。
层次索引提供了一个解决方案:我们创建两个级别的表示:
- 概要:对文档较大部分的简洁概述。
- 详细片段:这些部分内的较小片段。
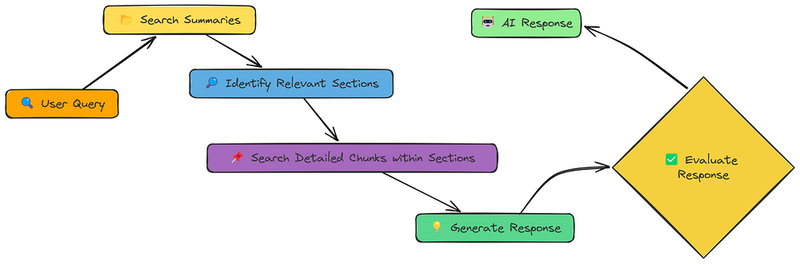
- 首先,搜索概要:这快速缩小文档的相关部分范围。
- 然后,仅在这些部分内搜索详细片段:这在保持大段上下文的同时提供了小片段的精确性。
让我们看看这个在 hierarchical_rag 函数调用中的实际效果:
def hierarchical_rag(query, pdf_path, chunk_size=1000, chunk_overlap=200,
k_summaries=3, k_chunks=5, regenerate=False):
"""
完整的层次检索增强生成(RAG)管道。
参数:
query (str): 用户查询。
pdf_path (str): PDF文档的路径。
chunk_size (int): 处理文本片段的大小。
chunk_overlap (int): 相邻片段之间的重叠。
k_summaries (int): 要检索的概要数量。
k_chunks (int): 每个概要要检索的详细片段数量。
regenerate (bool): 是否重新处理文档。
返回:
dict: 包含查询、生成的响应、检索的片段,以及摘要和详细片段的数量。
"""
# 定义缓存概要和详细向量存储的文件名
summary_store_file = f"{os.path.basename(pdf_path)}_summary_store.pkl"
detailed_store_file = f"{os.path.basename(pdf_path)}_detailed_store.pkl"
# 如果需要重新处理文档或缓存文件缺失,则处理文档
if regenerate or not os.path.exists(summary_store_file) or not os.path.exists(detailed_store_file):
print("正在处理文档并创建向量存储...")
summary_store, detailed_store = process_document_hierarchically(pdf_path, chunk_size, chunk_overlap)
# 将处理后的存储保存以供将来使用
with open(summary_store_file, 'wb') as f:
pickle.dump(summary_store, f)
with open(detailed_store_file, 'wb') as f:
pickle.dump(detailed_store, f)
else:
# 从缓存中加载现有的向量存储
print("正在加载现有的向量存储...")
with open(summary_store_file, 'rb') as f:
summary_store = pickle.load(f)
with open(detailed_store_file, 'rb') as f:
detailed_store = pickle.load(f)
# 使用分层搜索检索相关的片段
retrieved_chunks = retrieve_hierarchically(query, summary_store, detailed_store, k_summaries, k_chunks)
# 根据检索到的片段生成响应
response = generate_response(query, retrieved_chunks)
# 返回带有元数据的结果
return {
"query": query,
"response": response,
"retrieved_chunks": retrieved_chunks,
"summary_count": len(summary_store.texts),
"detailed_count": len(detailed_store.texts)
}
这个 hierarchical_rag 函数处理了两阶段检索过程:
- 首先,它在
summary_store中搜索最相关的摘要。 - 然后,它仅在顶级摘要所属的片段中搜索
detailed_store。这比搜索所有详细的片段要高效得多。
该函数还具有 regenerate 参数,用于创建新的向量存储或使用现有的存储。
让我们用它来回答我们的查询并进行评估:
# 运行分层RAG管道
result = hierarchical_rag(query, pdf_path)
我们检索并生成响应。最后,看看评估分数:
# 评估。
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{result['response']}\n真实响应:{reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出
0.84
我们的分数是0.84 😆
分层检索提供了迄今为止的最佳分数。
我们获得了搜索摘要的速度,以及搜索较小片段的精确性,同时还获得了知道每个片段属于哪个部分的额外上下文。这就是为什么它通常是性能最好的RAG策略之一。
15、HyDE
到目前为止,我们一直直接嵌入用户的查询或其转换版本。HyDE(假设文档嵌入)采取了不同的方法。它不是嵌入查询,而是嵌入一个假设的文档。
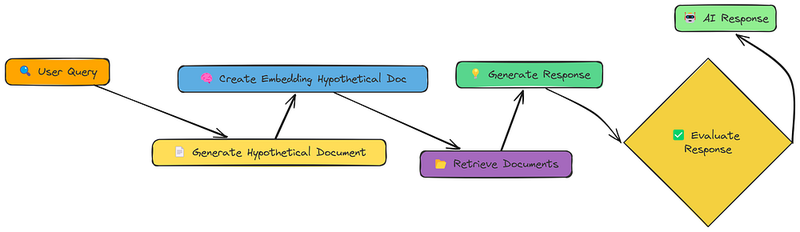
流程如下:
- 生成假设文档: 使用LLM创建一个会回答查询的文档。
- 嵌入假设文档: 创建该假设文档的嵌入,而不是原始查询的嵌入。
- 检索: 查找与假设文档嵌入相似的文档。
- 生成: 使用检索到的文档(而不是假设的文档!)来回答查询。
其想法是一个完整的文档,即使是假设的,也是一种比短查询更丰富的语义表示。这可以帮助弥合查询和文档嵌入空间之间的差距。
让我们看看它是如何工作的。首先,我们需要一个生成假设文档的函数。
我们使用 generate_hypothetical_document 来实现这一点:
def generate_hypothetical_document(query, desired_length=1000):
"""
生成一个会回答查询的假设文档。
"""
# 定义系统提示以指导模型如何生成文档
system_prompt = f"""你是一位专家文档创建者。
给定一个问题,生成一个详细文档,直接回答这个问题。
文档应大约为{desired_length}个字符长,并提供深入、详尽的答案。
写作时请假定此文档来自权威来源。包括具体细节、事实和解释。
不要提到这是假设文档——只需直接写内容即可。"""
# 定义用户提示,包含查询
user_prompt = f"问题:{query}\n\n生成一个完全回答此问题的文档:"
# 向OpenAI API发出请求以生成假设文档
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-3B-Instruct", # 指定使用的模型
messages=[
{"role": "system", "content": system_prompt}, # 系统消息以引导助手
{"role": "user", "content": user_prompt} # 用户消息包含查询
],
temperature=0.1 # 设置响应生成的温度
)
# 返回生成的文档内容
return response.choices[0].message.content
此函数接受查询并使用LLM“发明”一个回答它的文档。
现在,让我们将其整合到一个hyde_rag函数中:
def hyde_rag(query, vector_store, k=5, should_generate_response=True):
"""
使用假设文档嵌入执行RAG。
"""
print(f"\n=== 处理查询的HyDE:{query} ===\n")
# 第一步:生成回答查询的假设文档
print("生成假设文档...")
hypothetical_doc = generate_hypothetical_document(query)
print(f"生成了长度为{len(hypothetical_doc)}字符的假设文档")
# 第二步:为假设文档创建嵌入
print("为假设文档创建嵌入...")
hypothetical_embedding = create_embeddings([hypothetical_doc])[0]
# 第三步:基于假设文档检索最相似的片段
print(f"检索{k}个最相似的片段...")
retrieved_chunks = vector_store.similarity_search(hypothetical_embedding, k=k)
# 准备结果字典
results = {
"query": query,
"hypothetical_document": hypothetical_doc,
"retrieved_chunks": retrieved_chunks
}
# 第四步:如果需要,生成响应
if should_generate_response:
print("生成最终响应...")
response = generate_response(query, retrieved_chunks)
results["response"] = response
return results
hyde_rag函数现在:
- 生成假设文档。
- 为该文档(而不是查询!)创建嵌入。
- 使用该嵌入进行检索。
- 如前所述生成响应。
让我们运行它并查看生成的响应:
# 运行HyDE RAG
hyde_result = hyde_rag(query, vector_store)
# 评估。
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{hyde_result['response']}\n真实响应:{reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出
0.5
我们的评估分数约为0.5。
虽然HyDE是一个聪明的想法,但它并不总是更好。在这种情况下,假设文档可能走了一个稍微不同的方向,导致不太相关的检索。
这里的关键教训是,没有单一的“最佳”RAG技术。不同的方法对不同的查询和不同的数据表现更好。
16、融合
我们已经看到不同的检索方法有不同的优势。向量搜索擅长语义相似性,而关键词搜索则擅长找到精确匹配。如果我们能将它们结合起来呢?这就是融合RAG的想法。
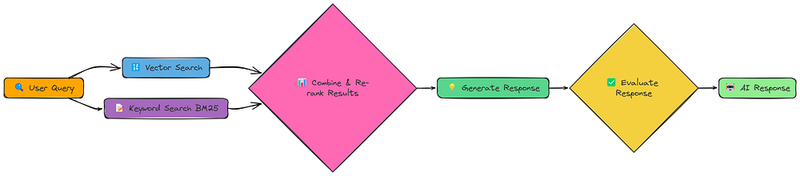
与其选择一种检索方法,融合RAG同时使用两者,然后结合和重新排名结果。这样可以捕获语义含义和精确关键词匹配。
我们实现的核心是融合_检索函数。此函数执行基于向量的检索和BM25检索,将每种方法的得分归一化,使用加权公式组合它们,并根据组合得分对文档进行排名。
以下是融合检索函数:
import numpy as np
def fusion_retrieval(query, chunks, vector_store, bm25_index, k=5, alpha=0.5):
"""通过组合基于向量和BM25的检索结果执行融合检索。"""
# 为查询生成嵌入
query_embedding = create_embeddings(query)
# 执行向量搜索并将结果存储在字典中(索引->相似度分数)
vector_results = {
r["metadata"]["index"]: r["similarity"]
for r in vector_store.similarity_search_with_scores(query_embedding, len(chunks))
}
# 执行BM25搜索并将结果存储在字典中(索引->BM25分数)
bm25_results = {
r["metadata"]["index"]: r["bm25_score"]
for r in bm25_search(bm25_index, chunks, query, len(chunks))
}
# 从向量存储中检索所有文档
all_docs = vector_store.get_all_documents()
# 使用向量和BM25分数的加权和计算每个文档的组合分数
scores = [
(i, alpha * vector_results.get(i, 0) + (1 - alpha) * bm25_results.get(i, 0))
for i in range(len(all_docs))
]
# 按照组合得分对文档进行降序排序,并保留前 k 个结果
top_docs = sorted(scores, key=lambda x: x[1], reverse=True)[:k]
# 返回包含文本、元数据和组合得分的前 k 个文档
return [
{"text": all_docs[i]["text"], "metadata": all_docs[i]["metadata"], "score": s}
for i, s in top_docs
]
它结合了两种方法的优势:
- 向量搜索: 使用我们现有的
create_embeddings和 SimpleVectorStore 进行语义相似性搜索。 - BM25 搜索: 实现了一种基于关键词的搜索,使用 BM25 算法(一种标准的信息检索技术)。
- 分数组合: 将两种方法的分数结合起来,为我们提供了一个单一的、统一的排名。
让我们运行完整的管道并生成响应:
# 首先处理文档以创建块、向量存储和 BM25 索引
chunks, vector_store, bm25_index = process_document(pdf_path)
# 使用融合检索运行 RAG
fusion_result = answer_with_fusion_rag(query, chunks, vector_store, bm25_index)
print(fusion_result["response"])
# 评估。
evaluation_prompt = f"用户查询: {query}\nAI 响应:\n{fusion_result['response']}\n真实响应: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出
AI 响应的评估得分为 0.83
最终得分为 0.83。
融合 RAG 经常给我们带来显著的提升,因为它结合了不同检索方法的优点。
这就像有两个专家一起工作,一个擅长理解查询的含义,另一个擅长找到精确匹配。
17、多模态
到目前为止,我们只处理了文本。但很多信息被锁定在图像、图表和图表中。多模态 RAG 的目标是解锁这些信息并用它来改进我们的响应。

这里的关键变化是:
- 提取文本与图像: 我们从 PDF 中提取出文本和图像。
- 生成图像标题: 我们使用具有 视觉 能力的 LLM(具体来说是 llava-hf/llava-1.5–7b-hf 模型)为每张图像生成文本描述(标题)。
- 创建嵌入(文本与标题): 我们为文本片段和图像标题创建嵌入。
- 嵌入模型: 在这个笔记本中,我们使用的是 BAAI/bge-en-icl 嵌入模型。
- LLM 模型: 用于生成响应和图像标题的模型。
这样,我们的向量存储包含了文本和视觉信息,我们可以跨这两种模式进行搜索。
这里我们定义了 process_document 函数:
def process_document(pdf_path, chunk_size=1000, chunk_overlap=200):
"""
为多模态 RAG 处理文档。
"""
# 创建用于提取图像的目录
image_dir = "extracted_images"
os.makedirs(image_dir, exist_ok=True)
# 从 PDF 中提取文本和图像
text_data, image_paths = extract_content_from_pdf(pdf_path, image_dir)
# 将提取的文本分块
chunked_text = chunk_text(text_data, chunk_size, chunk_overlap)
# 处理提取的图像以生成标题
image_data = process_images(image_paths)
# 合并所有内容项(文本块和图像标题)
all_items = chunked_text + image_data
# 提取用于嵌入的内容
contents = [item["content"] for item in all_items]
# 为所有内容创建嵌入
print("为所有内容创建嵌入...")
embeddings = create_embeddings(contents)
# 构建向量存储并将项目及其嵌入添加进去
vector_store = MultiModalVectorStore()
vector_store.add_items(all_items, embeddings)
# 准备文档信息,包括文本块和图像标题的数量
doc_info = {
"text_count": len(chunked_text),
"image_count": len(image_data),
"total_items": len(all_items),
}
# 打印添加项目的摘要
print(f"向向量存储中添加了 {len(all_items)} 个项目({len(chunked_text)} 个文本块,{len(image_data)} 个图像标题)")
# 返回向量存储和文档信息
return vector_store, doc_info
该函数处理了 图像提取和标题生成,以及 MultiModalVectorStore 的创建。
我们假设 图像标题生成 工作得相当好。(在实际场景中,您需要仔细评估您的标题质量。)
现在,让我们将它们整合在一起并进行查询:
# 处理文档以创建向量存储。我们有一个新的 PDF 文件
pdf_path = "data/attention_is_all_you_need.pdf"
vector_store, doc_info = process_document(pdf_path)
# 运行多模态 RAG 管道。这与之前非常相似!
result = query_multimodal_rag(query, vector_store)
# 评估。
evaluation_prompt = f"用户查询: {query}\nAI 响应:\n{result['response']}\n真实响应: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出
0.79
我们得到了大约 0.79 的分数。
多模态 RAG 具有很大的潜力,特别是在文档中图像包含关键信息的情况下。然而,它并没有超过我们迄今为止看到的其他技术。
18、纠正 RAG
到目前为止,我们的 RAG 系统相对被动。它们检索信息并生成响应。但如果检索到的信息不好怎么办?如果它是不相关的、不完整的,甚至是矛盾的呢?纠正 RAG(CRAG)直接解决了这个问题。
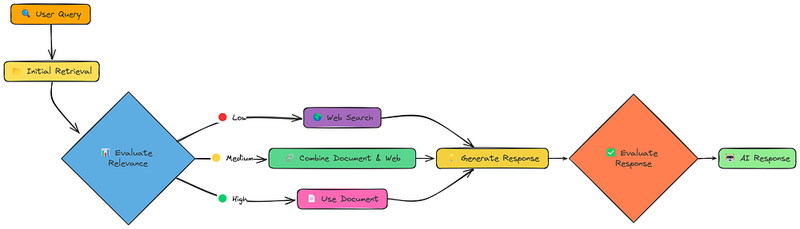
CRAG 添加了一个关键步骤:评估。在初始检索之后,它会检查检索到的文档的相关性。并且,至关重要的是,它根据评估结果采取不同的策略:
- 高相关性: 如果检索到的文档很好,则按常规流程继续。
- 低相关性: 如果检索到的文档很差,则回退到 网络搜索!
- 中等相关性: 如果文档还不错,则结合文档和网络中的信息。
这种“纠正”机制使 CRAG 比标准 RAG 更加健壮。它不仅仅是寄希望于最好的情况;它积极地检查并适应。
让我们看看它在实践中的表现。我们将使用名为 rag_with_compression 的函数来进行此操作。
# 运行 CRAG
crag_result = rag_with_compression(pdf_path, query, compression_type="selective")
这一单次函数调用做了很多事情:
- 初始检索: 按常规方式检索文档。
- 相关性评估: 对每个文档的相关性进行评分。
- 决策制定: 决定是否使用文档、进行网络搜索,还是两者结合。
- 响应生成: 使用所选知识源生成响应。
一如既往,评估:
# 评估。
evaluation_prompt = f"用户查询: {query}\nAI 响应:\n{crag_result['response']}\n真实响应: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出 ###
0.824
我们的目标分数约为 0.824。
CRAG 检测和纠正检索失败的能力使其比标准 RAG 显著更可靠。
通过在网络搜索必要时动态切换,它可以处理更广泛的查询范围,并避免陷入无关或不足的信息。
这种“自我纠正”的能力是迈向更强大和可信赖 RAG 系统的重要一步。
19、结束语
测试的 18 种 RAG 技术代表了提高检索质量的不同方法,从简单的分块策略到高级方法如自适应 RAG。
虽然简单 RAG 提供了一个基线,但更复杂的策略如分层索引(0.84)、融合(0.83)和 CRAG(0.824)通过解决检索挑战的不同方面显著超越了它。
自适应 RAG 作为顶级表现者(0.86),通过根据查询类型智能选择检索策略证明了上下文感知、灵活的系统在满足多样化信息需求方面提供了最佳结果。
原文链接:Testing 18 RAG Techniques to Find the Best
汇智网翻译整理,转载请标明出处
