DeepSeek-R1的3个关键思想
大多数新的 AI 模型感觉都像是小步。DeepSeek R1 则不同。这是近期第一个让你停下来思考的模型,这可能很重要。
来自中国的新型大型语言模型 DeepSeek R1 的发布在 AI 研究界引起了轰动。这不仅仅是又一次渐进式改进。DeepSeek 代表着一次重大飞跃。大多数新的 AI 模型感觉都像是小步。DeepSeek R1 则不同。这是近期第一个让你停下来思考的模型,这可能很重要。
中国的一个团队上周日发布了它,它已经引起了轰动。它的基准接近 OpenAI 的 01 模型在推理任务(数学、编码和科学)中的基准。但有趣的不仅仅是数字。而是他们如何达到这一水平。
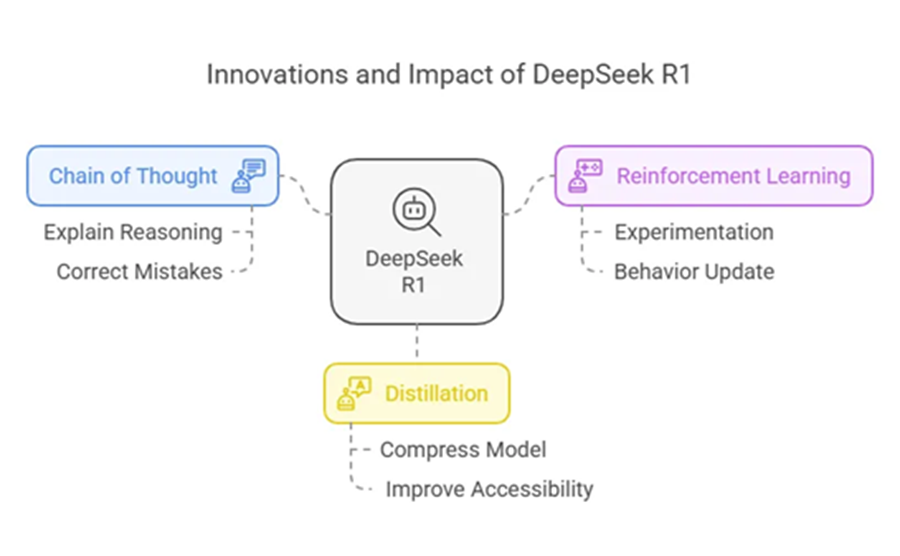
DeepSeek R1 背后有三个关键思想:
- 思维链 — 让模型自我解释。
- 强化学习 — 让它自我训练。
- 蒸馏 — 在不损失能力的情况下缩小模型。
1、思维链
如果你问大多数AI模型一个难题,它们会给你一个答案,但不会给出背后的原因。这是一个问题。如果答案是错的,你就不知道它在哪里偏离了轨道。
思维链解决了这个问题。模型不是直接给出答案,而是一步一步解释它的推理。如果它犯了错误,你可以准确地看到错误在哪里。更重要的是,模型本身可以看到错误在哪里。
这不仅仅是一个调试工具。它改变了模型的思维方式。解释的行为迫使他们放慢速度并检查自己的工作。结果是更好的答案,即使没有额外的训练。
DeepSeek 论文展示了一个数学问题的例子。该模型会遍历解决方案,意识到自己犯了错误,然后自我纠正。这是新的。大多数人工智能模型都不会这样做。他们要么做对,要么做错,然后继续前进。

2、强化学习
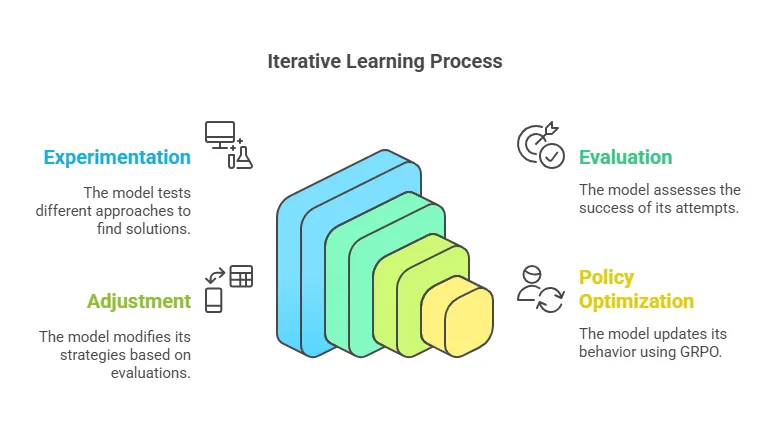
大多数人工智能训练看起来就像学校:向模型展示一个问题,给它正确的答案,然后重复。DeepSeek采用了不同的方法。它更像婴儿一样学习。
婴儿没有得到指示。他们尝试、失败、调整并再次尝试。随着时间的推移,他们会变得更好。这就是强化学习的工作原理。该模型探索回答问题的不同方式,并选择最有效的一种。
这就是机器人学习走路的方式。这就是自动驾驶汽车学习导航的方式。现在,这就是DeepSeek改进其推理的方式。
关键思想是群体相对策略优化(GRPO)。 GRPO 不会简单地将答案评为正确或错误,而是将它们与过去的尝试进行比较。如果新答案比旧答案更好,模型就会更新其行为。
这使得学习成本更低。模型不需要大量标记数据,而是通过迭代自己的错误来训练自己。这就是为什么 DeepSeek R1 会随着时间的推移而改进,而 OpenAI 的 01 模型则保持不变。经过足够的训练,它甚至可能在推理任务中达到人类水平的准确度。
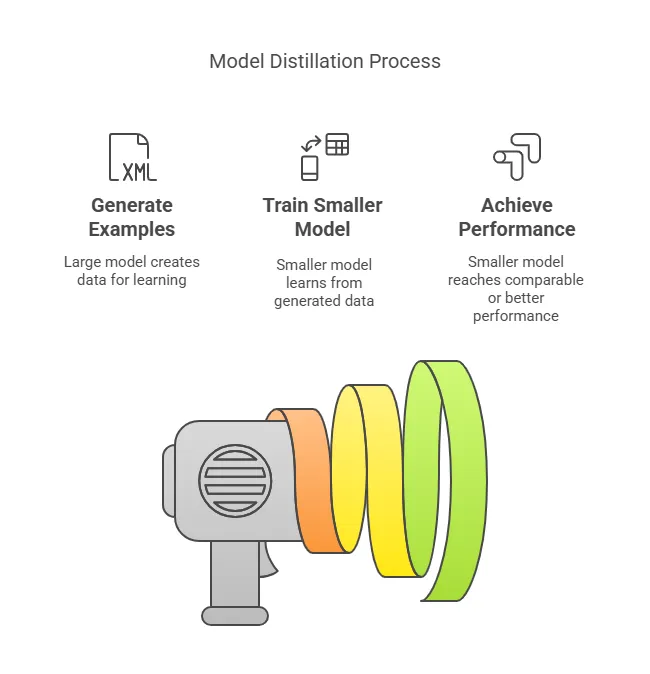
3、蒸馏
像 DeepSeek 这样的模型有一个问题:它们太大了。
完整版有 6710 亿个参数。运行它需要数千个 GPU 和只有科技巨头才能负担得起的基础设施。这对大多数人来说都不切实际。
解决方案是蒸馏——将一个巨大的模型压缩成一个较小的模型,而不会损失太多性能。可以把它想象成教一个学徒。大模型生成示例,小模型从中学习。
DeepSeek 研究人员将他们的模型蒸馏进 Llama 3 和 Qwen。令人惊讶的是较小的模型有时表现优于原始模型。这使得人工智能更容易获得。你不需要超级计算机,只需在单个 GPU 上运行强大的模型即可。
4、为什么这很重要
DeepSeek 将思维链推理、强化学习和模型蒸馏相结合,使其成为一个强大的工具。它不仅仅是原始的力量。它是关于创建准确、透明和可访问的模型。
思维链使模型的推理清晰。强化学习使其能够随着时间的推移而改进。而蒸馏确保这些功能可供更广泛的受众使用,而不仅仅是那些可以使用超级计算机的人。
如果你对人工智能感兴趣,DeepSeek 值得关注。它不仅仅是另一个渐进式的改进。这是朝着能够以以前无法实现的方式思考、学习和适应的模型迈出的一步。
最好的部分?你不需要成为一名人工智能研究人员就能看到它的潜力。DeepSeek 背后的技术已经应用于现实世界的应用中,从编码助手到科学研究工具。随着这些模型变得越来越容易获得,它们的影响只会越来越大。
DeepSeek R1 不仅对人类很重要,而且对人类也很重要。不是因为它能做什么,而是因为它如何做到。
- 思维链使人工智能更加透明。
- 强化学习使其更具自我完善性。
- 蒸馏使其更加可用。
这些不仅仅是优化。它们是人工智能模型工作方式的转变。如果 DeepSeek 不断改进,它可能会推动整个领域的发展。
如果你想看看人工智能的发展方向,这是一个不错的选择。
所以,如果你好奇,就深入研究这篇论文。或者更好的是,亲自尝试一下 DeepSeek。并不是每天都能看到突破性的行动。
原文链接:DeepSeek R1 Explained: Chain of Thought, Reinforcement Learning, and Model Distillation
汇智网翻译整理,转载请标明出处
