
3种方法打造领域大模型
领域特定大型语言模型 (domain-specific LLM) 是一种经过训练或微调的专业模型,用于执行由组织政策明确定义和指导的任务。与通用 LLM 不同,领域特定 LLM 旨在在实际应用中服务于特定目的。这些自定义模型需要对其上下文有深刻的理解,其中包括与产品、公司政策和行业特定术语相关的数据。
训练过程是基础模型和领域特定模型之间的关键区别。基础模型由机器学习团队使用自监督学习技术在未注释的数据集上进行训练。另一方面,在开发领域特定语言模型时,训练样本经过精心策划和标记,采用监督学习方法。这种方法确保模型能够很好地处理特定领域的任务。
为什么领域特定大模型优于基础模型?
通用语言模型 (LLM) 因其可扩展性和对话能力而广受赞誉,允许用户与它们交互并获得类似人类的响应。这种曾经难以想象的进步已成为现实。然而,尽管基础模型具有自然语言处理能力,但它们并非完美无缺。用户很快发现,例如,ChatGPT 可能会生成不准确的信息,这种现象被称为“幻觉”。例如,一位依靠聊天机器人进行研究的律师在不知情的情况下向法庭提交了虚假案件。
从根本上说,基础模型缺乏理解其所训练的庞大数据集之外的特定上下文的能力。如果不在法律语料库上训练语言模型并实施保护措施来检测不准确的信息,它可能会冒着虚假故事或曲解法律诉讼中上下文的风险。
因此,需要对特定领域内的语言有更深入了解的定制模型。当使用专业知识进行训练时,此类模型可以在其特定环境中更准确地发挥作用。例如,对特定领域的语言模型 (LLM) 进行微调可以使其与语义搜索结合使用,从而实现与特定组织相关的结果的对话检索。
特定领域大模型的示例包括:
- BloombergGPT :是一种专为金融自然语言处理 (NLP) 任务设计的大规模语言模型。这是一个拥有 500 亿个参数和超过 7000 亿个 token 的 AI 模型,已在大量金融语言文档数据集上进行了训练。
- FinGPT:是一种使用金融数据进行预训练的轻量级语言模型。它提供了比专有的 BloombergGPT 更实惠的培训选项。FinGPT 应对这些挑战,推出了一款开源金融语言模型。它采用从人类反馈中强化学习 (RLHF) 来理解和适应个人偏好,为个性化金融助理铺平了道路
- CLIMATEBERT:是一种基于 Transformer 的语言模型,它进一步在超过 200 万段气候相关文本上进行了预训练,这些文本来自各种来源,例如常见新闻、研究文章和公司气候报告。通过额外的微调,该模型使组织能够进行更准确的事实核查和其他专门针对环境数据的语言相关任务。
- BioGPT:BioGPT 是一种特定领域的生成式预训练 Transformer 语言模型,用于生物医学文本生成和挖掘。BioGPT 遵循 Transformer 语言模型主干,并从头开始对 1500 万篇 PubMed 摘要进行预训练
下面介绍三种创建领域特定大模型的方法:从零训练、微调和检索增强生成。
1、从头开始构建领域大模型
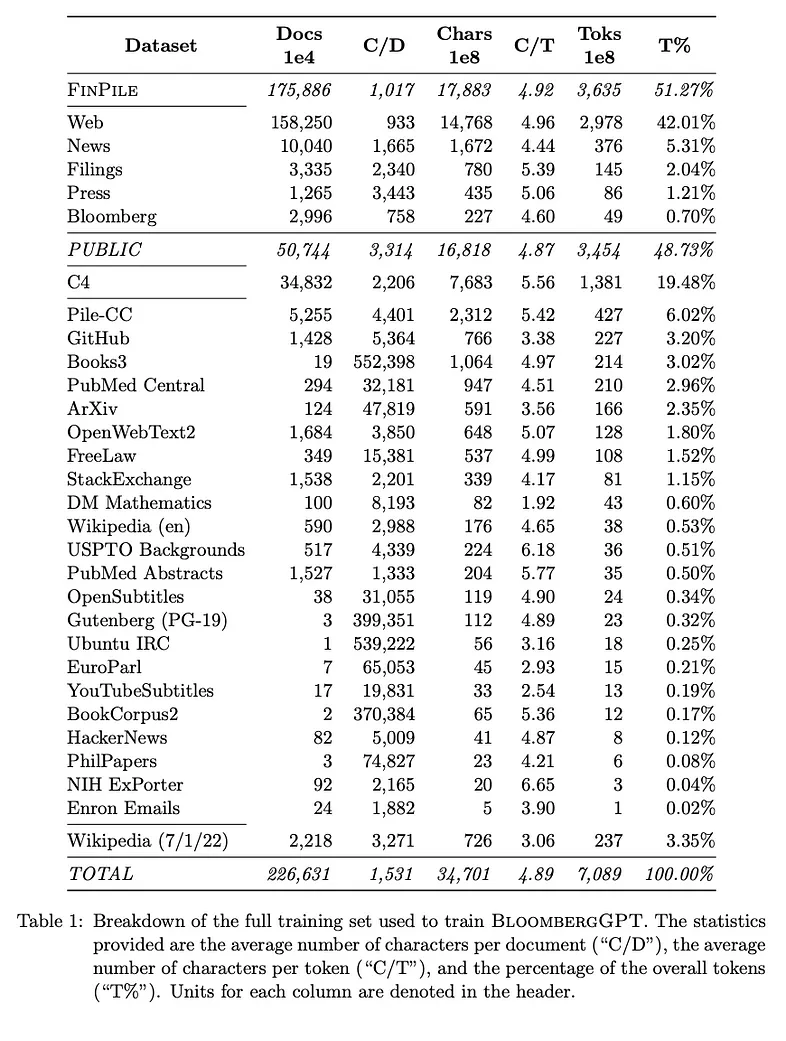
考虑一下,BloombergGPT 是使用金融(FINPILE)和公共数据集从头开始构建的。
可以使用行业特定知识从头开始训练基础模型。此过程涉及使用未标记的数据以自监督的方式教授模型。
BloombergGPT 是基于 BLOOM(BigScience 大型开放科学开放获取多语言语言模型)的仅解码器语言模型。该模型包含 70 层解码器块。在训练期间,该模型使用下一个标记预测和掩码级建模等技术。它通过掩蔽句子中的某些标记来顺序预测单词。
- 硬件:在 Amazon SageMaker 服务上训练的模型,总共 64 个 p4d.24xlarge 实例,可产生 512 个 40GB A100 GPU。 BloombergGPT 的训练需要 53 天才能完成。
- 1 GPU 的成本 = 4.10 美元/小时
- 训练模型的总估计成本:53 天 x 512 GPU x 24 小时 x 4.10 美元/小时 = 267.1 万美元
如果你选择这种方法,请注意该过程所需的大量计算资源、数据质量和昂贵的成本。从头开始训练模型需要资源,因此精心挑选和准备高质量的训练样本至关重要。
2、通过微调为特定领域定制 LLM
值得注意的是,并非所有组织都从头开始训练特定领域的大模型。在许多情况下,微调基础模型足以在特定任务中实现合理的准确性。这种方法需要更少的数据、计算资源和时间。
在微调过程中。我们必须利用预先训练的模型,例如 GPT 和 PaLM,它们已经表现出卓越的语言能力。他们通过在一小组带注释的数据上以较低的学习率进行训练来调整模型的权重。这种微调原则允许语言模型在保留其初始学习的同时整合新知识。此外,还应用了强大的内容审核机制来防止模型生成有害内容。
迁移学习是一种常见的微调技术,其中在一个任务上训练的模型(基础模型)被用作第二个任务(新模型)的起点。当第二个任务与第一个任务相似,或者第二个任务可用的数据有限时,这种方法特别有用。
MedPaLM 是使用此方法训练的领域特定模型的一个例子。它建立在 PaLM 的基础上,PaLM 是一个 5400 亿参数的语言模型,在复杂任务中表现出色。为了开发 MedPaLM,Google 使用了几种提示策略,向模型呈现带注释的医学问题和答案对。
3、检索增强生成
检索增强生成 (RAG) 是一种人工智能技术,通过将外部信息纳入生成过程来增强大型语言模型 (LLM) 的功能。
这种方法允许 AI 提供更准确、更符合语境、更最新的提示响应。
RAG 的工作原理是将搜索大型数据集或知识库的检索模型(图 A-D)与生成模型(如 LLM)相结合。检索模型接受输入查询并从知识库中检索相关信息。然后,生成模型使用此信息生成文本响应。
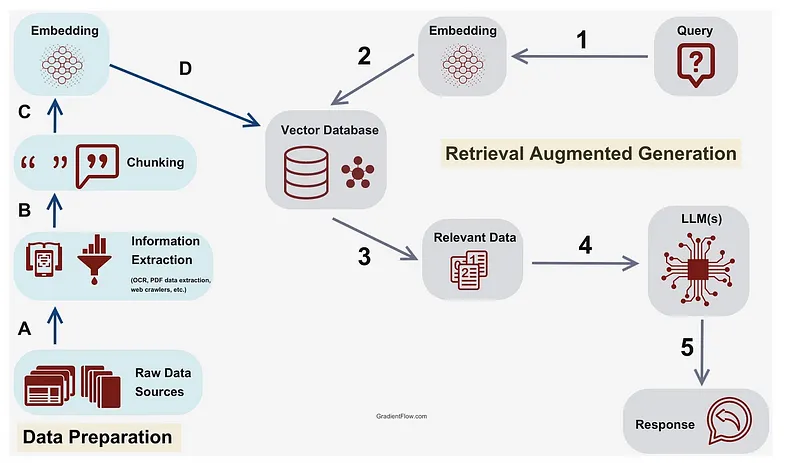
检索到的信息可以来自各种来源,例如关系数据库、非结构化文档存储库、互联网数据流、媒体新闻源、音频记录和交易日志。
RAG 的过程可以分为两个主要步骤:检索和生成。在检索步骤中,模型获取输入查询并使用它来搜索知识库、数据库或外部来源。然后将检索到的信息转换为高维空间中的向量,并根据其与输入查询的相关性进行排序。在生成步骤中,LLM 使用检索到的信息来生成文本响应。
这些响应更准确且与上下文相关,因为它们是由检索模型提供的补充信息塑造的。
4、结束语
领域特定大模型是为特定知识任务量身定制的,解决了通用语言模型在专业应用中的局限性。领先的AI提供商认识到这一需求,开发了领域特定模型,如 BloombergGPT、Med-PaLM 2 和 ClimateBERT。这些模型有望通过释放金融机会、提高运营效率和提升客户体验来彻底改变行业
原文链接:Building an LLM for domain-specific needs
汇智网翻译整理,转载请标明出处


