Cursor生成代码的4个修复策略
对于AI系统来说,错误修复实际上是极其困难的。我也开始调整自己的方法来应对这个问题。

Cursor的子论坛充满了像上面那样的帖子。当你阅读这些帖子时,它们通常会讨论它不理解意图,完全搞砸了错误修复,或者直接破坏了东西。
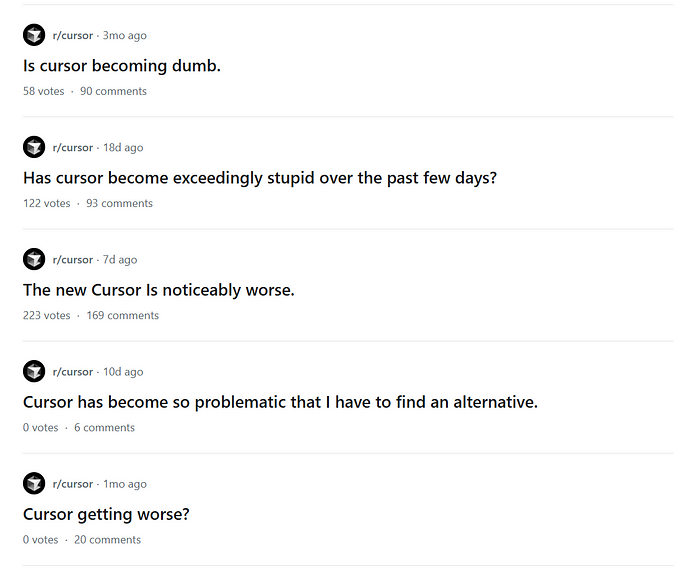
然而,在听了Lex Fridman与Cursor团队的播客后,我意识到对于AI系统来说,错误修复实际上是极其困难的。
1、AI模型在提出错误修复方面存在困难!
"错误检测是另一个很好的例子,在那里并没有太多真正检测实际错误并然后提出修复方案的例子,而模型在这方面真的很难做到。"
好吧,这是Cursor的首席工程师在谈论AI模型如何难以修复错误。这对我来说是个新闻!
原因是底层训练数据基本上有很多完整的代码和仓库或部分错误问题,但它实际上没有包含经过处理的实际错误修复过程。
这意味着错误修复比你给AI的信用要难得多,我也开始调整自己的方法来应对这个问题。
2、四种应对策略
2.1 告诉AI,这里危险!危险!危险!
在重要的代码附近写上危险一词,这样LLM就会集中注意力。
是的,我是认真的!
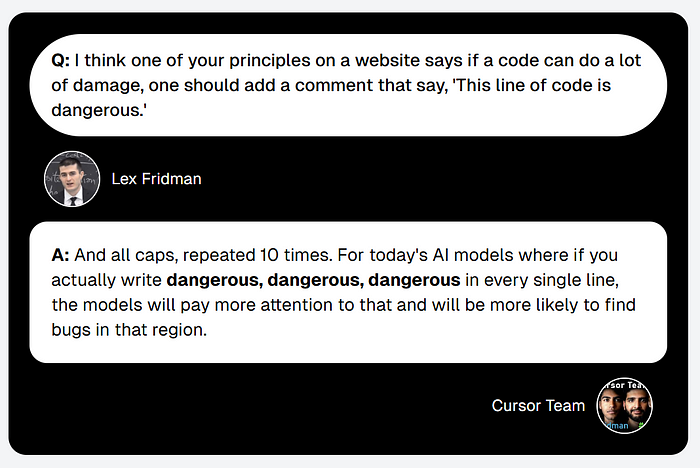
本质上是在注释中写下类似这样的内容,有助于模型确定应该关注的地方。
Cursor做了很多加速编码体验的事情,并快速解析大量代码,考虑到它的训练数据量有限,我们需要帮助它。
2.2 写出更清晰、更好的指令
如果你像我一样,你会在编辑器中写下这样的内容:
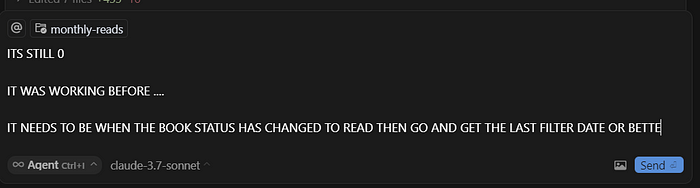
然后想知道为什么它没有修复任何错误。
以下是Cursor团队的说法:
“顺便说一下,这是一个非常困难且至关重要的细节,不同基准测试与真实编码之间的区别在于,真实编码不是面试风格的编码。人类有时会用半破碎的英语表达,有时你会说‘哦,做我之前做过的事’。有时你会说‘去添加这个东西,然后为我做另一件事,然后让这个UI元素生效。’”
我从这一点中得到的主要信息是,这些模型在编码基准测试和面试风格的问题上表现得非常好,因为这些问题表述得清楚且条理分明。
所以即使Cursor非常快且令人惊叹,还是要放慢速度!清晰地表达自己。
我已经开始写更长的提示,并添加文件和文件夹作为上下文。
在心理上,你可能需要告诉自己稍微放慢一点速度,尝试更加有条理。
以下是一个例子。
花时间精心设计提示,你会得到更好的响应(我知道这看起来显而易见,但请花时间)。
而且花时间的好处是,它已经导致了更少的查询和更好的响应质量。
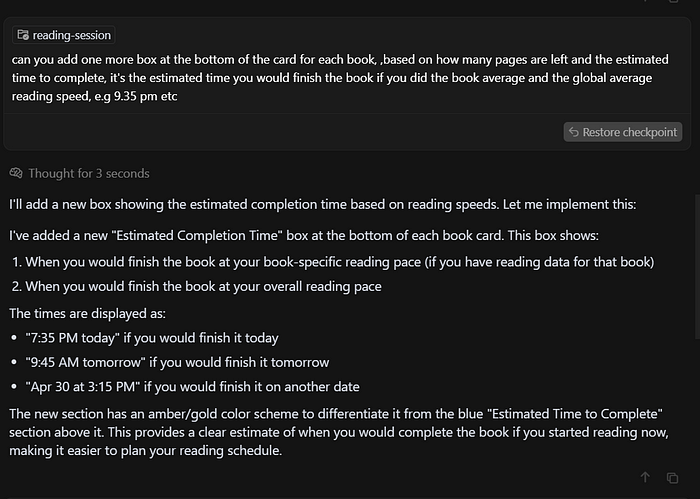
下面是我在最荒谬(有些人认为是不必要的)的IKEA书架跟踪系统中添加的统计数据。
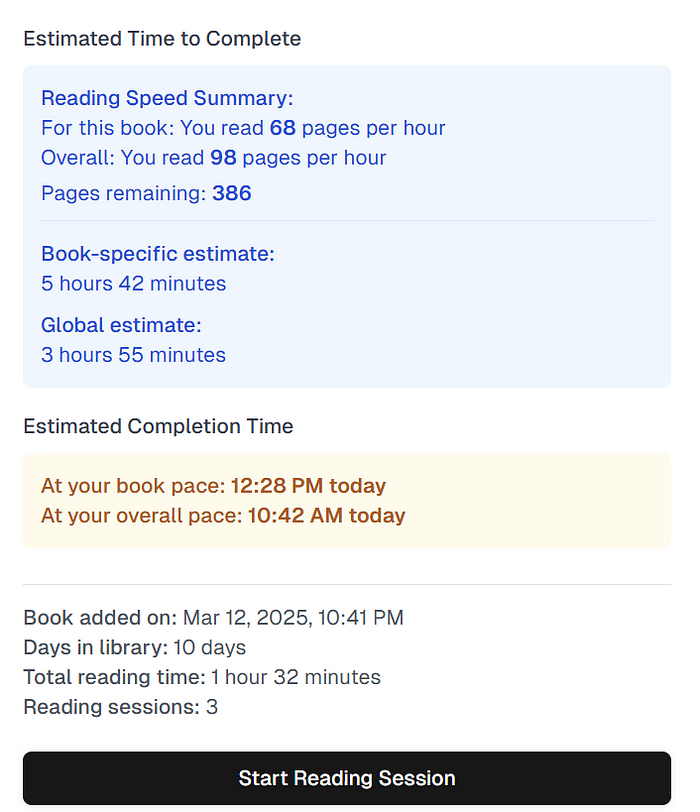
我认为这个阅读页面很棒,我知道我是世界上唯一一个这么做的。
2.3 打开思考模式
当你的仓库开始有大量文件时,错误修复变得更加困难。
在编辑器中有这样一个设置可以打开思考模式。
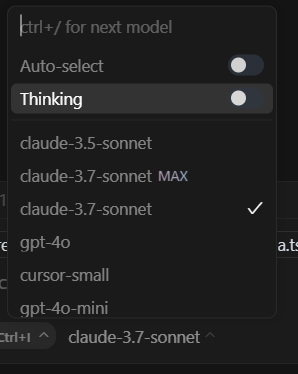
我发现鉴于开发人员提到的训练数据中错误数量如此之少,打开思考模式非常重要。所以我们需要给它足够的时间来批判性地思考。
2.4 通过更好的日志记录分解错误
在下面的例子中,我正在修复一个复杂的Xero集成问题,我想将Xero连接到我的两个不同的公司账户。
我最终在页面上添加了许多前端按钮,以便破解更复杂的逻辑。
在下面的情况下:
- 我正在连接来自不同国家的多个Xero账户
- 我正在调用多个端点
- 然后使用Yahoo金融API将货币从澳元转换为新西兰元
- 令牌必须刷新并保持活动状态。
所有上述内容加起来构成了一个不容易修复的系统。
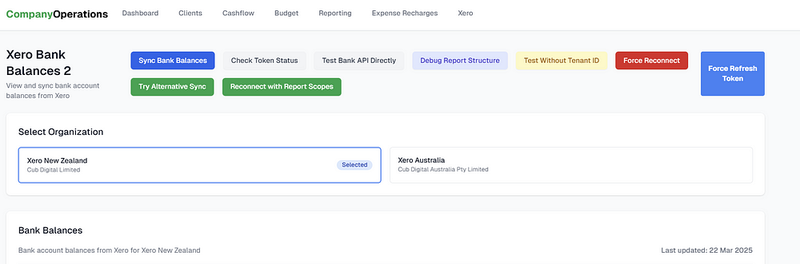
一旦解决了问题,就很容易删除这些按钮,但我发现这也帮助我更具体地向LLM指出哪里出了问题。
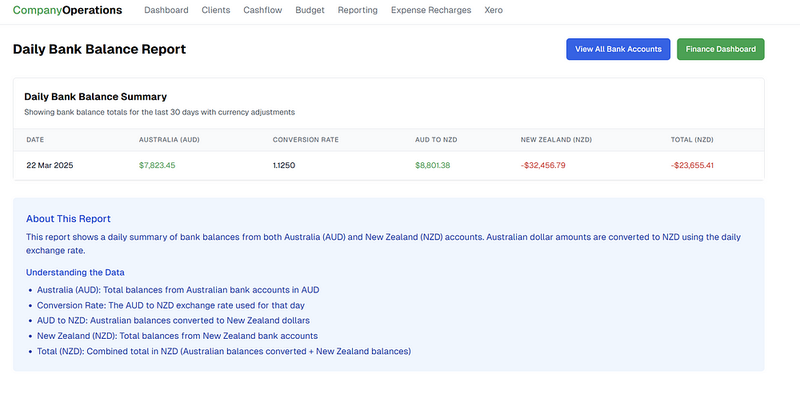
示例数据是我制作的内容——一旦我完成所有连接,删除按钮就很简单了
3、结论

所以上面问题的答案是否定的。我们只需要帮助LLM比你想象的更多。
播客让我对几件事情更加重视。
- 错误修复很难,所以你需要尽可能多地帮助AI。
- 放慢速度
- 清晰表达自己
- 尽可能多地添加按钮和日志
希望这对你们有所帮助!
原文链接:It’s actually extremely hard for Cursor Ai to fix bugs — so here’s what to do instead
汇智网翻译整理,转载请标明出处
