5个文本/表格提取Python包
从非结构化数据中提取有意义的信息对于各种应用至关重要。从 PDF 等文档中提取文本和表格在数据分析、信息检索和自动化任务中发挥着重要作用。

在当今的数字时代,从非结构化数据中提取有意义的信息对于各种应用至关重要。从 PDF 等文档中提取文本和表格在数据分析、信息检索和自动化任务中发挥着重要作用。
在这篇博文中,我们将深入研究 Python 中的文本和表格提取世界,探索可以简化这些过程的不同包。
0、光学字符识别 (OCR)
在深入研究提取包之前,让我们先了解一下光学字符识别 (OCR) 的基本概念。
OCR 是一种使计算机能够识别和提取图像或扫描文档中的文本的技术。它涉及一系列步骤,包括图像预处理、字符分割和字符识别。

文本检测和文本识别是两个基本组件,它们协同工作以在 OCR 中从图像或扫描文档中提取文本。让我们详细探讨每个部分:
文本检测涉及定位图像或文档中包含文本的区域或边界框。此步骤对于确定需要执行文本提取的关注区域至关重要。以下是文本检测过程的概述:
- 对象定位:应用对象定位算法来识别图像中可能包含文本的潜在区域。这些算法分析视觉特征,例如边缘、角和纹理图案,以确定可能包含文本的区域。
- 边界框生成:一旦识别出潜在的文本区域,就会在这些区域周围生成边界框。这些边界框定义了图像中文本的空间范围,并提供了一种隔离和提取文本以供进一步处理的方法。
一旦检测到文本区域,下一步就是执行文本识别,这涉及将检测到的文本区域转换为机器可读的文本。以下是文本识别过程的概述:
- 字符分割:在此步骤中,进一步分析文本区域以分割单个字符或文本行。这种分割对于将文本分成可以单独识别的较小单元是必要的。
- 特征提取:对于每个分割的字符或文本行,提取边缘、角或纹理图案等特征。这些特征有助于以有意义的方式表示文本单元的视觉特征。
- 字符识别:提取的特征用作字符识别算法的输入,例如机器学习模型或模式匹配技术。该算法将特征与预先训练的字符或字体集进行比较,并确定每个片段最可能的字符。
- 文本组合:一旦字符被单独识别,它们就会根据其在文本区域内的空间排列组合并组织成单词、句子或段落。此组合步骤可确保识别的字符按正确的顺序排列,以形成连贯且有意义的文本。
- 后处理:在文本识别步骤之后,可以应用其他后处理技术来细化识别的文本。这可以包括语言建模、拼写检查和上下文分析,以提高提取文本的准确性和连贯性。
文本提取包
1、Pytesseract
Pytesseract 是一个流行的 Python 库,可用作 Google 的 Tesseract OCR 引擎的包装器。它提供了一个简单的界面来从图像和扫描文档中提取文本。它可以读取所有类型的图像,如 jpeg、png、gif、bmp、tiff 等。
从图像中提取文本的函数:
text = pytesseract.image_to_string(imagePath, **args)其他可选参数:
- lang — 文本的语言(例如 lang = ‘eng+fra’)
- config — OCR 配置(例如 config = ‘-c retain_interword_spaces=1’)
- output_type — 指定输出的类型,默认为字符串(例如 output_type = Output.STRING)
config 参数允许你自定义 Tesseract OCR 引擎的行为和性能。它使你能够传递其他配置选项来影响文本提取过程。
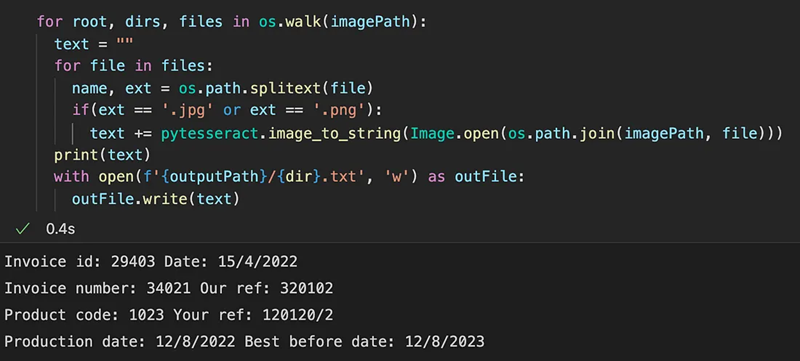
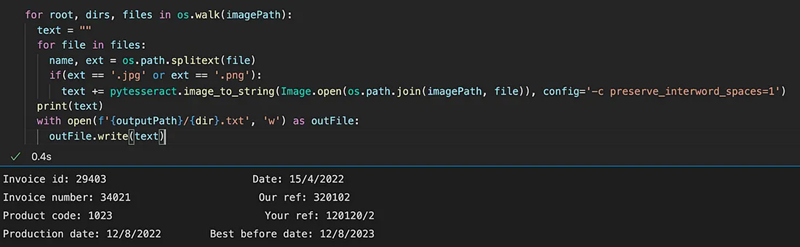
例如,要从下图中提取键值对,可以使用 -c retain_interword_spaces = 1 选项,该选项在文本提取期间保留单词间空格。默认情况下,Pytesseract 执行文本识别时不考虑各个单词之间的间距。这可能导致提取的文本作为连续字符串返回,而识别的单词之间没有任何空格。

当你在 Pytesseract 的配置字符串中包含 -c retain_interword_spaces=1 参数时,它会指示 Pytesseract 保留原始文本中的单词间空格。这意味着提取的文本将包括识别单词之间的空格,保持原始单词边界。
2、PyMuPDF (Fitz)
PyMuPDF,也称为 Fitz,是 MuPDF 库的 Python 绑定。它提供了处理 PDF 文档的全面功能,包括文本提取。PyMuPDF 允许你访问 PDF 文件中的文本内容、元数据和注释。其广泛的功能使其成为从简单和复杂的 PDF 文档中提取文本的多功能选择。
提取文本的函数:
get_text(option)我们可以从多个可用选项中选择一个选项。默认情况下,选择“文本”选项。选项列表如下。
选项:
- text:(默认)带换行符的纯文本。没有格式,没有文本位置详细信息,没有图像。
- blocks:生成文本块列表(= 段落)。
- words:生成单词列表(不包含空格的字符串)。
- html:生成 HTML 格式的内容。
- dict / json:与 HTML 信息级别相同,但以 Python 字典或 JSON 字符串形式提供。
- rawdict / rawjson:“dict”/“json”的超集。它还提供字符详细信息。
下面给出了按段落提取文本的示例:
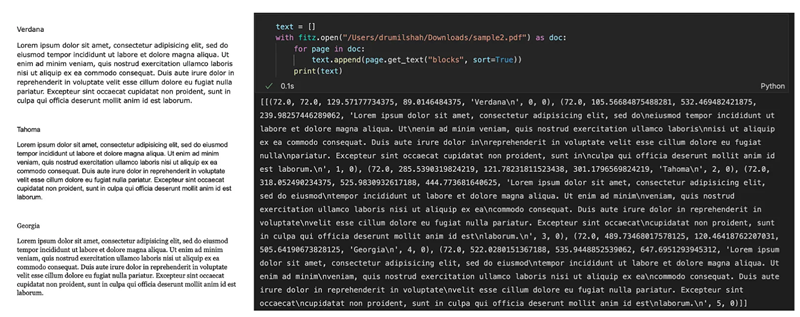
上面的代码将返回一个元组列表:
- 每个元组被视为一个块。
- 元组包含:(X0、Y0、X1、Y1、“块中的行”、block_no、block_type)
- 前四项是边界框坐标
- 第五项是文本本身(多行由换行符或“\n”分隔)
- 第六项是块编号
- 第七项是块类型(0 表示文本,1 表示图像)
Fitz 以自然阅读顺序读取 pdf。如果 PDF 被分成 2 列,Fitz 不会水平读取整行,而是先读取第一列,然后开始以自然阅读顺序读取第二列:

Fitz 的局限性:
- 仅适用于机器生成的 PDF,不适用于扫描的 PDF
- 该库需要安装非 Python 软件(MuPDF)。
3、pdfplumber
以下每个属性都返回匹配对象的 Python 列表:
- chars — 每个代表一个文本字符。
- lines — 每个代表一条一维线。
- rects — 每个表示一个二维矩形。
- curves — 每个表示任何一系列无法识别为线或矩形的连接点。
- images — 每个表示一张图片。
- annots — 每个表示一个 PDF 注释
- hyperlinks — 每个表示一个子类型为 Link 的 PDF 注释,并具有 URI 操作属性

在上图中,你可以看到键以粗体显示。因此,我们可以使用文本的字体属性从上图中提取键。代码片段如下所示:
boldKey = []
with pdfplumber.open(pdfPath) as pdf:
text = pdf.pages[0]
# filter only those words which have object type as char, Bold in fontname property
bold_text = text.filter(lambda obj: (obj["object_type"] == "char" and "Bold" in obj["fontname"]))
boldKey.append(bold_text.extract_text())
boldKey = boldKey[0].split("\n")
print(boldKey)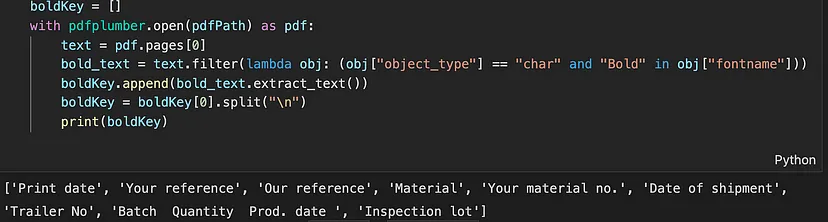
表格风格:
- Stream — Stream 可用于解析单元格之间有空格的表格,以模拟表格结构。

- Lattice — Lattice 本质上更具确定性,不依赖于猜测。它可用于解析单元格之间有分界线的表格。
表格提取包
4、Camelot
Camelot 是一个专门为从 PDF 文档中提取表格而设计的 Python 库。它利用先进的技术(包括计算机视觉算法)来准确检测和提取表格。Camelot 提供了不同的表格提取方法,例如 Lattice 和 Stream,以处理不同类型的表格结构。每个表都采用 pandas DataFrame 格式,可无缝集成到 ETL 和数据分析工作流中。我们可以将表导出为多种格式,包括 CSV、JSON、Excel 和 HTML。
提取表格的函数:
tables = camelot.read_pdf(filePath, **args)其他参数是
- pages — 从 PDF 读取的页数(默认值:'1')
- flavor — 解析方法(默认值:'lattice')
5、Tabula
Tabula 是一种流行的开源工具,可以从 PDF 文件中提取表格。它提供了一个用户友好的界面,既可以作为命令行实用程序,也可以作为 Python 库。Tabula 的算法可以智能地分析 PDF 布局,以有效地识别和提取表格。 Tabula-py 是 tabula-java 的简单 Python 包装器,可以读取 PDF 中的表格。你可以从 PDF 中读取表格并将其转换为 Pandas 数据框。Tabula-py 还允许你将 PDF 文件转换为 CSV、TSV 或 JSON 文件。
提取表格的函数:
dfs = tabula.read_pdf(filePath, **args)其他参数:
- pages — 从 PDF 读取的页数(默认值:‘1’)
6、结束语
从文档中提取文本和表格是许多数据驱动应用程序中的基本任务。在这篇博文中,我们探索了各种有助于从 PDF 中提取文本和表格的 Python 包。我们介绍了文本提取包,如 pytesseract、PyMuPDF (Fitz) 和 pdfplumber。对于表格提取,我们讨论了 Camelot 和 Tabula,它们提供了从 PDF 文档中提取表格的有效方法。
通过利用这些包,你可以自动执行从 PDF 文件中提取有价值信息的过程,从而提高工作效率并实现对非结构化数据的更深入分析。
原文链接:Exploring Text and Table Extraction Packages in Python
汇智网翻译整理,转载请标明出处
