加速实时视觉应用
本文介绍如何使用Roboflow推理管道和Nvidia Deepstream加速边缘视觉推理。
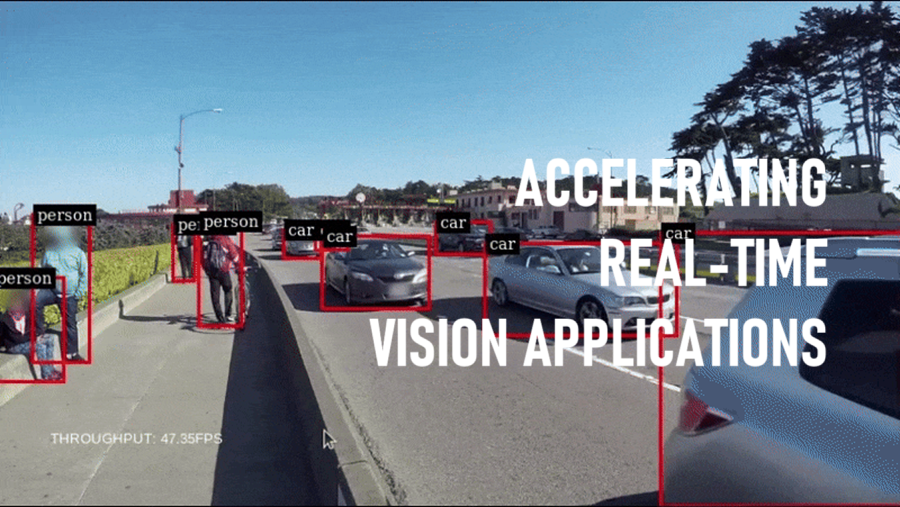
在边缘部署机器学习通常会在传感和监控应用中提供显著优势。通过将处理保持在数据源附近,可以节省大量的网络、存储和云计算成本,并且整体延迟也会降低。然而,边缘设备受限于其有限的计算资源,这些资源通常比服务器的要弱。因此,当在边缘部署机器学习应用程序时,必须对其进行专门优化以最大化性能。
在这篇文章中,我们将讨论加速实时计算机视觉应用的技术,这些技术可以在智能传感、监控或机器人等场景中找到。我们将通过使用开源库(如OpenCV、Roboflow推理和Nvidia Deepstream)来实现推理管道。
1、推理管道
推理管道将运行视频流上的机器学习推理的过程分为一系列离散步骤。一个基本的管道通常包括以下阶段:
- 视频流数据被提取并解码形成图像帧。
- 帧在推理前进行预处理(调整大小、归一化等)。
- 批量帧被转换为张量并发送到设备GPU(如果没有可用GPU,则发送到CPU)进行推理。
- 推理结果被叠加到原始帧上,并显示在屏幕上、本地保存或向下传输。
- 推理结果作为元数据发送以触发进一步操作。
更复杂的管道可能包括对象跟踪、感兴趣区域过滤和其他业务逻辑,具体取决于应用场景。
2、推理管道的异步化
虽然推理管道中的步骤是依次执行的,但它们实际上可以通过使用多线程在运行时并发执行。
多线程是指在同一时间运行多个线程或可运行代码段的过程。在Python中,这是通过上下文切换实现的,在这种情况下,处理器在当前线程空闲时切换到其他线程,从而给人一种两者同时执行的错觉。
由于推理管道包括I/O操作(读取帧、将张量复制到GPU、传输结果),在此期间CPU处于等待状态,因此多线程提供了加速的潜力。这在帧以批次方式处理时特别有用,因为这可以让CPU有时间继续处理其他任务,而当批次正在收集和发送进行推理时。
这就是Roboflow的推理管道实现的基础,它将视频解码、推理和后处理分离到专用线程中并发运行。

考虑以下使用OpenCV中的YOLOv8-nano目标检测模型实现的同步推理管道:
import cv2
from inference import get_model
import supervision as sv
model = get_model("yolov8n-640")
cap = cv2.VideoCapture('/path/to/video')
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("Can't receive frame (stream end?). Exiting ...")
break
predictions = model.infer(frame)
detections = sv.Detections.from_inference(predictions[0])
annotated_image = sv.BoxAnnotator().annotate(scene=frame, detections=detections)
annotated_image = sv.LabelAnnotator().annotate(scene=annotated_image, detections=detections)
cv2.imshow("output", annotated_image)
if cv2.waitKey(1) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
在上述代码中,管道从视频流中读取帧,调用检测模型,注释帧,最后将其投影到显示。这些步骤是顺序执行的,意味着每个步骤必须完成执行后下一个步骤才能开始。
与使用Roboflow推理管道实现相同管道的代码相比:
from inference import InferencePipeline
from inference.core.interfaces.camera.entities import VideoFrame
import supervision as sv
import cv2
def on_prediction(
predictions: dict,
video_frame: VideoFrame,
) -> None:
detections = sv.Detections.from_inference(predictions)
annotated_image = sv.BoxAnnotator().annotate(scene=frame, detections=detections)
annotated_image = sv.LabelAnnotator().annotate(scene=annotated_image, detections=detections)
cv2.imshow("output", annotated_image)
cv2.waitKey(1)
# 创建推理管道对象
pipeline = InferencePipeline.init(
model_id="yolov8n-640",
video_reference='/path/to/video'
)
# 启动管道
pipeline.start()
# 等待管道完成
pipeline.join()
在上面的例子中,帧注释和显示是在一个回调函数中实现的,该函数在一批推理完成后执行。
在Nvidia Jetson AGX Xavier上运行这两个程序,我们得到以下吞吐量测量结果:
- OpenCV — 同步:20.1 FPS
- Roboflow-异步:22.3 FPS
多线程因此导致了适度的性能提升,达到了11%,表现相当不错。
3、选择合适的推理引擎
在许多情况下,实时视觉应用的性能瓶颈并不是CPU执行;相反,GPU推理时间可能会很长,尤其是在使用较大模型时。在这种情况下,选择最适合目标设备硬件的推理运行时引擎非常重要。
机器学习模型通常在PyTorch或TensorFlow等框架中训练,这些框架旨在促进模型训练。一旦训练完成,这些模型可以转换为以加速后端为特点的部署专用格式,以便更快地进行推理。这些推理引擎通常针对特定的芯片组进行了优化。这些包括但不限于:
- TensorRT — Nvidia GPU
- OpenVINO — Intel x86 CPU
- Tensorflow Lite / Lite Micro — 嵌入式
- ONNX — 多平台
让我们回到之前的例子。Roboflow推理默认使用ONNX运行时引擎。为了充分利用我们的Jetson的Nvidia GPU,我们可以启用TensorRT,方法是设置以下环境变量:
export ONNXRUNTIME_EXECUTION_PROVIDERS="[TensorrtExecutionProvider,CUDAExecutionProvider,OpenVINOExecutionProvider,CoreMLExecutionProvider,CPUExecutionProvider]"
这将编译从我们的YOLOv8权重文件生成的TensorRT模型引擎,大约需要15分钟。再次运行两个管道,我们得到以下结果:
- OpenCV — 同步:26.7 FPS
- Roboflow-异步:31.9 FPS
两个管道都从TensorRT引擎获得了显著的性能提升。有趣的是,管道之间的吞吐量差距从11%增加到了19%,这表明异步管道从加速引擎中受益更多。
4、加速推理管道的其余部分
现在我们已经加快了推理步骤的速度,我们可以转向增强管道的其余部分。为此,我们使用Nvidia的Deepstream SDK,它将推理管道拆分为一组基于GStreamer媒体框架的硬件优化插件。
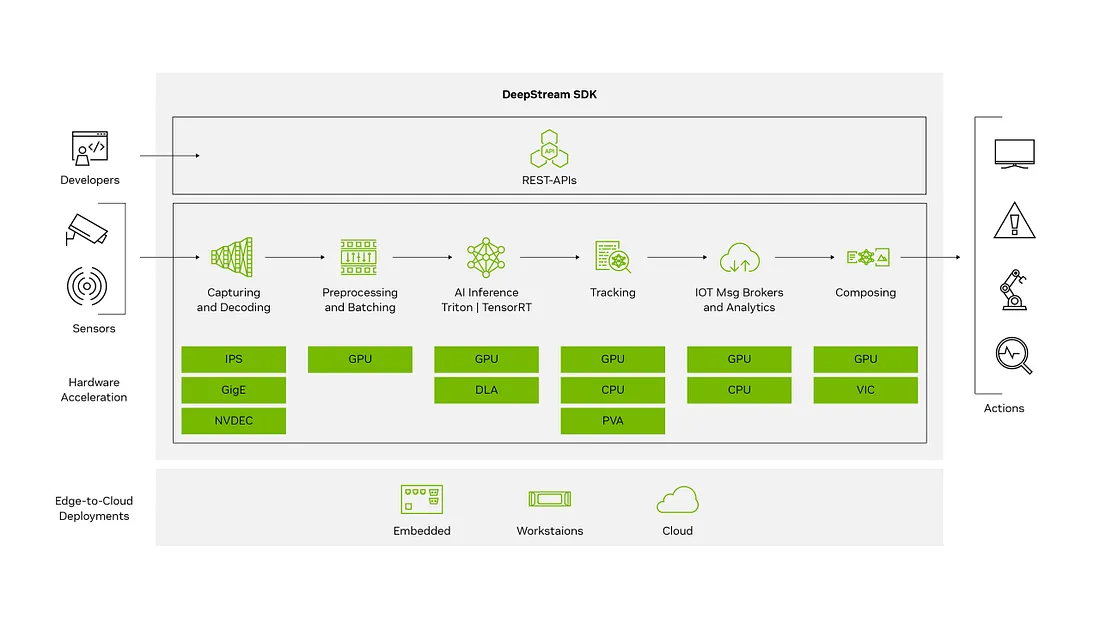
我们使用以下Deepstream插件构建了一个相同的推理管道:
- UriDecodeBin — 自动解码各种视频源,包括保存的文件、USB摄像头和RTSP流。
- Nvstreammux — 批量帧并实例化NvDsBatchMeta以保存推理结果和帧元数据。
- Nvinfer — TensorRT推理引擎。
- Nvvideoconvert — 将帧转换为可用于显示的格式。
- Nvosd — 屏幕显示容器。
- Sink — 在桌面上显示或保存到文件。
- Queue — 在管道元素之间启用异步性。
这相当于使用Deepstream Python绑定的以下Python应用程序:
import gi
gi.require_version('Gst', '1.0')
from gi.repository import GLib, Gst
import sys
# 添加包含deepstream-python-apps中的辅助函数的目录
sys.path.append('/opt/nvidia/deepstream/deepstream-6.3/sources/deepstream_python_apps/apps')
from common.bus_call import bus_call
import pyds
# 应用程序的DeepStream配置
# 初始化GST
Gst.init(None)
# 创建管道
pipeline = Gst.Pipeline()
# 创建视频源
uri_name = 'file:///path/to/video'
source_bin=create_source_bin(0, uri_name)
pipeline.add(source_bin)
# Streammux
streammux = Gst.ElementFactory.make('nvstreammux', 'streammux')
pipeline.add(streammux)
# 设置streammux属性
streammux.set_property('batch-size', 1)
streammux.set_property('width', 852)
streammux.set_property('height', 480)
sinkpad= streammux.get_request_pad("sink_0")
srcpad=source_bin.get_static_pad("src")
srcpad.link(sinkpad)
# 创建主要推理元素(GIE)
primary_gie = Gst.ElementFactory.make('nvinfer', 'primary-gie')
primary_gie.set_property('config-file-path', '/path/to/yolov8/config/file')
# 创建nvvidconv(视频转换器)
nvvidconv = Gst.ElementFactory.make('nvvideoconvert', 'nvvidconv')
# 创建OSD(屏幕显示)
osd = Gst.ElementFactory.make('nvdsosd', 'osd')
# 创建sink(显示输出)
sink = Gst.ElementFactory.make('nv3dsink', 'sink')
sink.set_property('sync', 0)
# 向管道添加元素
pipeline.add(primary_gie)
pipeline.add(nvvidconv)
pipeline.add(osd)
pipeline.add(sink)
# 创建队列元素以启用异步管道
queue1=Gst.ElementFactory.make("queue","queue1")
queue2=Gst.ElementFactory.make("queue","queue2")
queue3=Gst.ElementFactory.make("queue","queue3")
pipeline.add(queue1)
pipeline.add(queue2)
pipeline.add(queue3)
# 连接元素
streammux.link(queue1)
queue1.link(primary_gie)
primary_gie.link(queue2)
queue2.link(nvvidconv)
nvvidconv.link(queue3)
queue3.link(osd)
osd.link(sink)
# 初始化循环
loop = GLib.MainLoop()
bus = pipeline.get_bus()
bus.add_signal_watch()
bus.connect ("message", bus_call, loop)
# 启动管道
pipeline.set_state(Gst.State.PLAYING)
# 启动主循环
try:
loop.run()
except Exception as e:
print("Error during pipeline execution:", e)
pass
pipeline.set_state(Gst.State.NULL)
我们使用Deepstream-YOLO仓库将我们的PyTorch权重转换为TensorRT模型引擎文件。运行该应用程序,我们得到以下吞吐量测量结果:
- Deepstream-异步:48.2 FPS
这表明相对于前面两种实现,性能又有了显著提升。
5、结束语
总之,本教程演示了如何使用Roboflow推理管道和Deepstream SDK实现异步和加速推理管道,使吞吐量提高了两倍以上。
对于严重受限的设备,还可以通过其他技术进一步减少推理延迟,包括帧批处理、模型量化和剪枝以及使用更简单的模型。希望这篇文章能帮助你开发实时视觉应用。
该项目的完整代码可以在这里找到这里。
原文链接:Accelerating Real-time Vision Applications
汇智网翻译整理,转载请标明出处
