Agentic AI驱动的医学研究系统
这篇文章将演示如何利用 Qdrant 和 Crewai 构建数据采集管道和 RAG 代理。

这篇文章将演示如何利用 Qdrant 和 Crewai 构建数据采集管道和 RAG 代理。我们考虑一个现有的医院管理系统,其中传统数据被输入到数据库(例如 MongoDB)中。这些数据随后被流式传输到 Kafka,然后在 Qdrant 中矢量化。Crewai 代理将与 Qdrant 互动以满足用户请求。
1、持续数据采集
任何数据库与 kafka 和 qdrant 的结合都会创建一个强大而高效的数据流管道。 Qdrant Sink Connector 可确保将数据从 Kafka 持续提取到 Qdrant,而无需人工干预。这种实时集成对于依赖最新数据进行决策和分析的应用程序至关重要。此管道集成了 MongoDB 或任何传统数据库(如用于数据存储的 postgresql、用于数据流的 Kafka 和用于矢量搜索的 Qdrant)的功能,为大量数据的管理和实时处理提供了全面的解决方案。该架构的可扩展性、容错性和实时处理能力对其功效至关重要,使其成为当代数据驱动应用程序的多功能解决方案。
假设 Confluent Kafka 和 Qdrant 都已启动并运行,请按如下方式安装 qdrant kafka 连接器:
confluent-hub install qdrant/qdrant-kafka:1.1.0此命令直接从 Confluent Hub 检索指定的连接器并将其安装到你的 Confluent Platform 或 Kafka Connect 环境中。安装过程会自动管理所有必需的依赖项,从而促进 Qdrant Kafka 连接器与你当前配置的无缝集成。安装后,可以通过 Confluent 控制中心或 Kafka Connect REST API 配置和管理连接,从而促进 Kafka 和 Qdrant 之间的高效数据流,而无需复杂的人工配置。
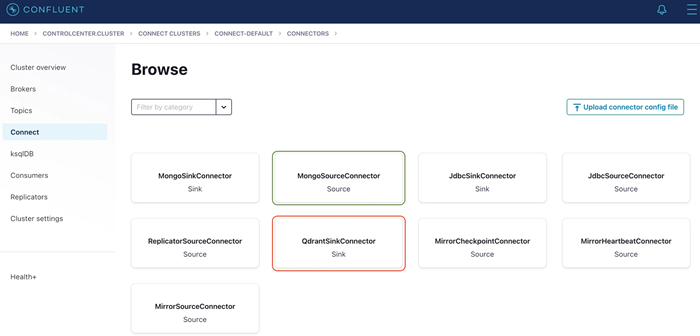
安装连接器后,请确保其配置如下。请记住,你的 key.converter 和 value.converter 对于 kafka 安全地将消息从主题传递到 qdrant 非常重要:
{
"name": "QdrantSinkConnectorConnector_0",
"config": {
"value.converter.schemas.enable": "false",
"name": "QdrantSinkConnectorConnector_0",
"connector.class": "io.qdrant.kafka.QdrantSinkConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"topics": "topic_62,qdrant_kafka.docs",
"errors.deadletterqueue.topic.name": "dead_queue",
"errors.deadletterqueue.topic.replication.factor": "1",
"qdrant.grpc.url": "http://localhost:6334",
"qdrant.api.key": "************"
}
}按如下方式安装 mongodb kafka 连接器:
confluent-hub install mongodb/kafka-connect-mongodb:latest安装 MongoDB 连接器后,连接器配置如下所示:
{
"name": "MongoSourceConnectorConnector_0",
"config": {
"connector.class": "com.mongodb.kafka.connect.MongoSourceConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"connection.uri": "mongodb://127.0.0.1:27017/?replicaSet=rs0&directConnection=true",
"database": "qdrant_kafka",
"collection": "docs",
"publish.full.document.only": "true",
"topic.namespace.map": "{\"*\":\"qdrant_kafka.docs\"}",
"copy.existing": "true"
}
}完成这些步骤后,数据将自动插入 mongodb 的数据现在将无缝流向 qdrant。
2、Crewai 代理实战
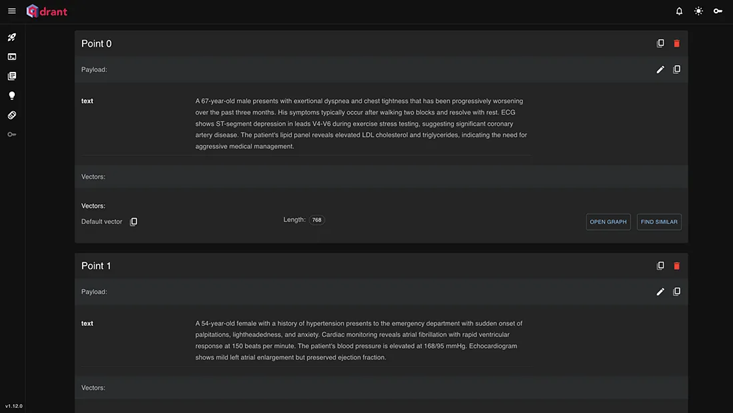
假设你有大量记录被刷新到 qdrant(下面显示了一个示例),现在是时候构建代理并为这些代理分配适当的任务,以便从他们那里获得正确的答案并协助用户。在我们的例子中,用户是医生和其他医院管理人员。
2.1 代码实现
下面的代码演示了一个使用当代 AI 方法查询医疗记录的强大系统。两个基本类协作以促进医疗记录的智能搜索。
初始类 SearchInput 是一个基本但必不可少的组件,它描述了搜索查询的框架。它源自 BaseModel 并需要单个输入:字符串格式的搜索查询。将其视为网站搜索框的数字对应物,尽管对其允许的输入类型有严格的规定。这种标准化保证了在搜索请求中的统一性,增强了系统的可靠性和可维护性。
第二个类 SearchMedicalHistoryTool 是真正的功能所在。该程序旨在使用称为向量相似性的方法搜索医疗记录。它不仅对齐关键字,还利用 OpenAI 的嵌入方法将搜索查询转换为数学表示(向量)。该向量封装了查询的语义意义,使系统能够理解搜索背后的上下文和意图,而不仅仅是确切的术语。
class SearchInput(BaseModel):
"""Input schema for search tool."""
query: str = Field(..., description="The search query")
class SearchMedicalHistoryTool(BaseTool):
name: str = "search_medical_records"
description: str = "Search through medical records using vector similarity"
args_schema: Type[BaseModel] = SearchInput
def _run(self, query: str) -> Any:
# Use OpenAI embeddings to match data_loader.py
query_vector = next(embedding_model.query_embed(query=query))
search_results = qdrant_client.search(
collection_name='medical_records',
query_vector=query_vector,
limit=10,
score_threshold=0.7
)
return [
{
"score": hit.score,
"text": hit.payload.get('text', 'N/A'),
}
for hit in search_results
]该程序随后使用特定的数据库客户端 (Qdrant) 来识别最相关的医疗记录。它寻找与搜索查询在数学上类似的记录,产生最多 10 个相似度阈值超过 0.7 的结果(其中 1.0 代表完全匹配)。每个结果都包含一个相关性分数以及医疗记录中的相应文本。
该系统的优势在于它能够理解医学术语和上下文的微妙之处。例如,如果医生查询“胸痛伴有呼吸困难的病例”,系统可能会使用各种相关医学术语来识别相关记录,使其成为需要及时访问重要患者数据的医疗保健从业者的宝贵资源。
def trigger_crew(query: str) -> str:
# initialize the tools
search_tool = SearchMedicalHistoryTool()
# Create agents
medical_data_search = Agent(
role='Medical Records Search Assistant',
goal='Find and analyze relevant information',
backstory="""You are an expert at finding and analyzing information.
You know when to search medical history records, and when
to perform detailed analysis.""",
tools=[search_tool],
verbose=True
)
data_synthesizer = Agent(
role='Information Synthesizer',
goal='Create comprehensive and clear responses',
backstory="""You excel at taking raw information and analysis
and creating clear, and present them as actionable insights.""",
verbose=True
)
# Create tasks with expected_output
data_search_task = Task(
description=f"""Process this query: '{query}'
2. If it needs medical history information, use the search tool.
3. For detailed analysis, use search tool.
Explain your tool selection and process.""",
expected_output="""A dictionary containing:
- The tools used
- The raw results from each tool
- Any analysis performed""",
agent=medical_data_search
)
data_synthesis_task = Task(
description="""Take the research results and create a clear response.
Explain the process used and why it was appropriate.
Make sure the response directly addresses the original query.""",
expected_output="""A clear, structured response that includes:
- Direct answer to the query
- Supporting evidence from the research
- present it in the form of bullets""",
agent=data_synthesizer
)
# Create and run crew
crew = Crew(
agents=[medical_data_search, data_synthesizer],
tasks=[data_search_task, data_synthesis_task],
verbose=True
)
result = crew.kickoff()
return str(result)上述代码建立了一个 Agentic AI驱动的医学研究系统,它使用一组专门的人工智能代理来处理和解释医学咨询。它类似于一群熟练的助手在合作,每个助手都有不同的专业功能。
trigger_crew 函数充当这个数字集合的指挥。它接受查询字符串作为输入,并利用两个专门的人工智能代理协调响应。这种方法类似于医学的协作努力团队,各种专业人员运用他们的知识来解决复杂问题。
初始代理 medical_data_search 被设计为检索和分析医疗记录的专家。可以将其视为熟练的研究助理,擅长准确确定何时以及如何检查病史。它配备了以前见过的搜索功能,使其能够使用语义理解分析医疗记录。
第二个代理 data_synthesizer 充当团队的沟通专家。其功能是将初始代理的初步研究和分析转化为连贯、可操作的发现。这与医生解释复杂的测试数据的方式相似,以精确和易于理解的方式表达它们。
每个代理通过 Task 类分配不同的职责。医疗搜索工作旨在确定查询是否需要过去的医疗数据,并在适当的时候进行彻底的分析。综合任务强调制定与初步询问直接相关的连贯、有组织的响应,并附上确凿的证据。
Crew 类集成了所有组件,监督代理之间的工作流程及其指定职责。它类似于项目经理,保证每个团队成员的贡献无缝过渡到后续阶段,最终为初始查询提供彻底的解决方案。
将它们组合在一起,可以作为独立的代理 RAG 应用程序运行:
import os
import sys
from qdrant_client import QdrantClient
from fastembed.text import TextEmbedding
from pydantic import BaseModel, Field
from typing import Type, Any
from crewai import Agent, Task, Crew
from crewai.tools import BaseTool
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
# Initialize qdrant client
qdrant_client = QdrantClient(url=os.environ.get('QDRANT_URL'), api_key=os.environ.get('QDRANT_API_KEY'))
# initialize the text embedding
embedding_model = TextEmbedding(model_name='snowflake/snowflake-arctic-embed-m')
class SearchInput(BaseModel):
"""Input schema for search tool."""
query: str = Field(..., description="The search query")
class SearchMedicalHistoryTool(BaseTool):
name: str = "search_medical_records"
description: str = "Search through medical records using vector similarity"
args_schema: Type[BaseModel] = SearchInput
def _run(self, query: str) -> Any:
# Use OpenAI embeddings to match data_loader.py
query_vector = next(embedding_model.query_embed(query=query))
search_results = qdrant_client.search(
collection_name='medical_records',
query_vector=query_vector,
limit=10,
score_threshold=0.7
)
return [
{
"score": hit.score,
"text": hit.payload.get('text', 'N/A'),
}
for hit in search_results
]
def trigger_crew(query: str) -> str:
# initialize the tools
search_tool = SearchMedicalHistoryTool()
# Create agents
medical_data_search = Agent(
role='Medical Records Search Assistant',
goal='Find and analyze relevant information',
backstory="""You are an expert at finding and analyzing information.
You know when to search medical history records, and when
to perform detailed analysis.""",
tools=[search_tool],
verbose=True
)
data_synthesizer = Agent(
role='Information Synthesizer',
goal='Create comprehensive and clear responses',
backstory="""You excel at taking raw information and analysis
and creating clear, and present them as actionable insights.""",
verbose=True
)
# Create tasks with expected_output
data_search_task = Task(
description=f"""Process this query: '{query}'
2. If it needs medical history information, use the search tool.
3. For detailed analysis, use search tool.
Explain your tool selection and process.""",
expected_output="""A dictionary containing:
- The tools used
- The raw results from each tool
- Any analysis performed""",
agent=medical_data_search
)
data_synthesis_task = Task(
description="""Take the research results and create a clear response.
Explain the process used and why it was appropriate.
Make sure the response directly addresses the original query.""",
expected_output="""A clear, structured response that includes:
- Direct answer to the query
- Supporting evidence from the research
- present it in the form of bullets""",
agent=data_synthesizer
)
# Create and run crew
crew = Crew(
agents=[medical_data_search, data_synthesizer],
tasks=[data_search_task, data_synthesis_task],
verbose=True
)
result = crew.kickoff()
return str(result)
if __name__ == "__main__":
while True:
query = input("\nEnter your query (type 'bye' or 'quit' to exit): ").strip()
if query.lower() in ['bye', 'quit']:
print("Goodbye!")
break
if not query:
print("Please enter a valid query.")
continue
try:
result = trigger_crew(query)
print(f"\nResult: {result}")
except Exception as e:
print(f"Error processing query: {str(e)}")3、构建 UI
以下代码使用 Streamlit 为医疗记录搜索系统。它具有一个简单的查询输入框,可连接到我们之前讨论过的 Agentic AI 搜索后端。
界面保留所有搜索及其结果的聊天式历史记录,并按时间倒序显示。每个查询和响应都存储在会话状态中并显示在可扩展部分中。该应用程序包括强大的错误处理功能,可清晰显示搜索过程中出现的任何问题。
import streamlit as st
import traceback
from rag_agents import trigger_crew
import openlit
openlit.init(otlp_endpoint="http://127.0.0.1:4318")
def main():
st.set_page_config(
page_title="Query Interface",
page_icon="🤖",
layout="wide"
)
st.title("Medical Case History Retriever")
st.markdown("Enter your query below to get started.")
# Initialize session state
if 'chat_history' not in st.session_state:
st.session_state.chat_history = []
# Query input using a form
with st.form(key='query_form'):
query = st.text_input(
"Enter your query:",
key="query_input",
placeholder="Type your query here..."
)
submit_button = st.form_submit_button("Submit")
# Clear history button outside the form
if st.button("Clear History"):
st.session_state.chat_history = []
# Process the query when form is submitted
if submit_button and query:
try:
result = trigger_crew(query)
# Add to chat history
st.session_state.chat_history.append({
"query": query,
"result": result,
"error": None
})
except Exception as e:
error_msg = f"Error: {str(e)}\n{traceback.format_exc()}"
st.session_state.chat_history.append({
"query": query,
"result": None,
"error": error_msg
})
# Display chat history in reverse chronological order
st.markdown("### Chat History")
for item in reversed(st.session_state.chat_history):
with st.expander(f"Query: {item['query']}", expanded=True):
if item['result']:
st.success(item['result'])
if item['error']:
st.error(item['error'])
# Add some helpful information at the bottom
st.markdown("---")
st.markdown("""
**Tips:**
- Enter your query in the text box above
- Press Enter or click Submit to process your query
- Click Clear History to start fresh
- Each query and its result will be saved in the chat history
""")
if __name__ == "__main__":
main()主要功能包括主搜索表单、清除历史记录按钮和底部的提示部分,以帮助用户浏览界面。该设计优先考虑简单性和可用性,同时为医疗专业人员提供有效搜索医疗记录所需的所有功能。
4、结束语
该医疗记录搜索系统展示了将当代人工智能方法与实用医疗应用相结合的有效性。该技术利用向量相似性搜索、专门的人工智能代理团队和直观的界面,为医疗从业者提供了一种检索和评估患者记录的有效方法。搜索中语义理解的集成和清晰的结果显示使其成为需要快速、准确获取患者信息的医疗从业者不可或缺的资源。
原文链接:Building Agentic RAG Pipelines for Medical Data with CrewAI and Qdrant
汇智网翻译整理,转载请标明出处
