AI编程代理:Grep vs. 语义搜索
当编码代理无法找到正确的代码时,它们会失败。Grep 适用于精确匹配。但当你的代理需要理解“我们在哪里处理身份验证?”时,grep 会返回空结果。

当编码代理无法找到正确的代码时,它们会失败。Grep 适用于精确匹配。但当你的代理需要理解“我们在哪里处理身份验证?”时,grep 会返回空结果。
1、何时使用哪种方法
当代理确切知道要查找什么时,使用 grep。
模型有很高的信心。它想要 getUserById、stripe.charges.create 或匹配 *Controller.ts 的文件。Grep 可以立即找到它们。
当代理在探索时,使用语义搜索。
模型不知道需要什么代码。它会问“我们在哪里处理限流?”或“JWT 验证是如何工作的?”语义搜索能理解意图并找到相关代码,而无需精确关键词。
我们的评估显示,结合两者是所有前沿模型中的最先进方法。Grep 用于精确性。语义搜索用于发现。它们一起平均将成功率提高了 31%,在大型代码库中提高了 56%。
Cursor 最近发表的研究表明,语义搜索在平均情况下产生了 12.5% 更高的准确性,并在大型代码库中提高了 2.6% 的代码保留率。他们的发现与我们一致:仅靠 grep 是不够的。
Morph SDK 通过一次导入即可提供现成的语义搜索。所有复杂性——Merkle 树、AST 感知分块、自定义嵌入、GPU 重新排序——都已为您处理。
2、它是如何工作的
我们训练了一个自定义的嵌入模型,并构建了一个两阶段检索系统:
第一阶段:向量搜索(约 50ms)
HNSW 索引从整个代码库中检索出 50 个候选。
第二阶段:GPU 重新排序(约 150ms)
morph-rerank-v4 对候选进行评分以确保精度,返回前 10 名。
总延迟:在 1,000 多个文件的代码库中约为 1230ms。
import { MorphClient } from '@morphllm/morphsdk';
const morph = new MorphClient({ apiKey: process.env.MORPH_API_KEY });
// Push 触发嵌入(后台 3-8 秒)
await morph.git.push({ dir: './project' });
// 使用自然语言进行搜索
const results = await morph.codebaseSearch.search({
query: "JWT 验证是如何工作的?",
repoId: 'project',
target_directories: [],
// 可选:搜索特定分支或提交
// branch: 'develop',
// commitHash: 'abc123...'
});
// 或与您的代理集成(支持 Anthropic、OpenAI、Vercel AI SDK)
import { createCodebaseSearchTool } from '@morphllm/morphsdk/tools/codebase-search/anthropic';
const tool = createCodebaseSearchTool({
repoId: 'project',
// 可选:搜索特定分支或提交
// branch: 'develop'
});
3、为什么实现方式很重要
那些声称“语义搜索已死”的人通常运行的是懒散的实现。
懒散的方法:
- OpenAI text-embedding
- 每 4k 个 token 分块
专业的方法:
- 使用 Merkle 树来监控文件更改(只重新嵌入更改的部分)
- AST 感知分块,尊重函数/类边界
- 在代码特定模式上训练的自定义代码嵌入模型
- 使用 HNSW 索引进行快速数据库查找
- 全局缓存
区别不是语义搜索 vs grep。而是好的语义搜索 vs 坏的语义搜索。懒散的实现增加了延迟却没有提高准确性。专业的实现使代理更快更准确。
4、结果
我们在一个包含 50 个仓库(200–5,000 个文件)的 500 个编码任务基准测试中对三种配置进行了测试:
| 配置 | 成功率 | 平均完成时间 |
|---|---|---|
| 仅 Grep | 64.2% | 38.4s |
| 仅语义搜索 | 71.8% | 35.7s |
| 语义 + Grep | 84.1% | 21.2s |
仅语义搜索比 grep 提高了 7.6 个百分点。但结合两者比仅用 grep 提高了 19.9 个百分点——提高了 31%。
5、为什么两者都很重要
语义搜索缩小到正确的文件。Grep 精确地定位这些文件中的位置。
示例工作流程:
- 代理询问:“我们在哪里验证 JWT 令牌?”(语义搜索)
- 返回
auth/middleware.ts、utils/jwt.ts - 代理搜索:
function.*verifyToken(Grep) - 找到确切的实现
这种两阶段方法在我们评估的所有前沿模型中取得了最佳效果。
6、大型代码库获得更大的收益
在拥有 1,000+ 个文件的仓库中,改进更加明显:
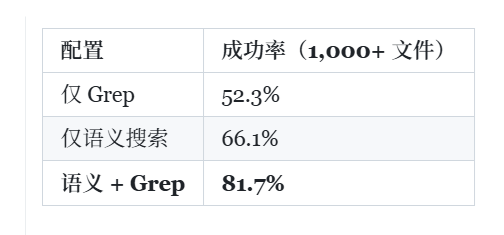
这是一次 56% 的成功率提升。代码库越大,语义搜索的帮助就越多。Grep 在代码库规模增大时扩展性差,因为它依赖于知道要查找什么。语义搜索让代理可以概念性地探索。
7、Morph SDK 如何工作
1. Push 触发自动索引:
await morph.git.init({ repoId: 'my-project', dir: './my-project' });
await morph.git.add({ dir: './my-project', filepath: '.' });
await morph.git.commit({ dir: './my-project', message: 'Initial commit' });
await morph.git.push({ dir: './my-project' });
// 嵌入在后台进行,3-8 秒
// 每个提交都会被单独索引,以便进行时间旅行调试
2. 使用您喜欢的 SDK 进行搜索:
// 直接搜索(支持分支/提交过滤)
const results = await morph.codebaseSearch.search({
query: "限流是在哪里实现的?",
repoId: 'my-project',
target_directories: [],
branch: 'develop' // 可选:搜索特定分支或提交
});
// Anthropic
import { createCodebaseSearchTool } from '@morphllm/morphsdk/tools/codebase-search/anthropic';
// OpenAI
import { createCodebaseSearchTool } from '@morphllm/morphsdk/tools/codebase-search/openai';
// Vercel AI SDK
import { createCodebaseSearchTool } from '@morphllm/morphsdk/tools/codebase-search/vercel';
3. 用 Grep 进行后续精确查找:
一旦语义搜索找到了正确的文件,就可以使用 Grep 查找确切的符号、导入或调用点。
8、在真实代理行为上进行训练
我们基于真实的代理会话训练了嵌入和重新排序模型——使用代理轨迹来学习“相关”在实践中意味着什么。这与 Cursor 的方法相吻合:在实际代理行为上进行训练,而不是通用代码相似性。标准嵌入模型优化的是相似性。而我们的模型则优化的是任务完成。
9、经验
当模型知道要找什么时,Grep 有效。当它们需要探索时,语义搜索有效。两者结合,平均将代理成功率提高了 31%,在大型代码库中提高了 56%。
原文链接:Grep Isn't Enough: Why Agents Need Semantic Search too
汇智网翻译整理,转载请标明出处
