AI驱动的C++到伪代码转换
在这篇博客中,我们将讨论构建一个基于深度学习的C++到伪代码转换器的技术实现、实际应用和挑战。
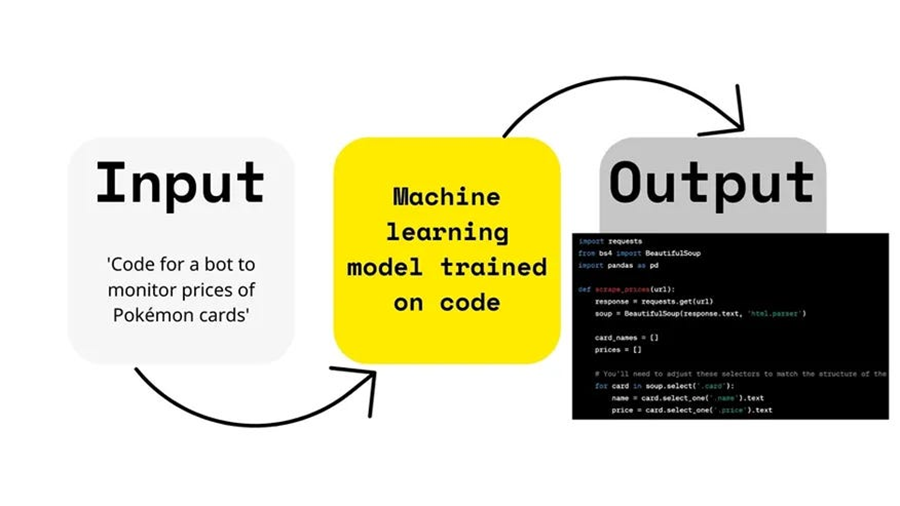
将代码翻译成人类可读的伪代码的能力对学生、教育者和开发人员都非常有价值。在这篇博客中,我们将讨论构建一个基于深度学习的C++到伪代码转换器的技术实现、实际应用和挑战。
1、数据预处理
高质量的数据集对于训练有效的模型至关重要。为此任务,我们使用包含C++代码片段及其对应伪代码描述的数据集。
- 加载数据集: 我们从TSV文件中加载数据集,确保每个条目都包含C++代码及其伪代码对应部分。
- 清理数据: 必须删除任何缺失或格式错误的数据行,以保持数据集的完整性。
def load_spoc_data_reversed(file_path, code_col='code', text_col='text'):
"""从TSV文件加载SPoC数据,C++作为源,伪代码作为目标。"""
df = pd.read_csv(file_path, sep='\t')
# 过滤掉'text'或'code'为空的行
df_clean = df.dropna(subset=[text_col, code_col])
return df_clean[code_col].tolist(), df_clean[text_col].tolist()
- 分词: 使用BERT等分词器对C++代码和伪代码进行分词,将其转换为适合模型输入的数值表示。
def tokenize_and_numericalize_bert(texts, codes, tokenizer, max_len=128):
"""使用BERT分词器对文本和代码序列进行分词、数值化并填充。"""
text_sequences_numericalized = []
code_sequences_numericalized = []
for text, code in zip(texts, codes):
encoded_text = tokenizer.encode(
BOS_TOKEN + " " + text + " " + EOS_TOKEN,
add_special_tokens=False,
max_length=max_len,
truncation=True,
padding='max_length'
)
encoded_code = tokenizer.encode(
BOS_TOKEN + " " + code + " " + EOS_TOKEN,
add_special_tokens=False,
max_length=max_len,
truncation=True,
padding='max_length'
)
text_sequences_numericalized.append(torch.tensor(encoded_text))
code_sequences_numericalized.append(torch.tensor(encoded_code))
text_sequences_padded = torch.stack(text_sequences_numericalized)
code_sequences_padded = torch.stack(code_sequences_numericalized)
return text_sequences_padded, code_sequences_padded
- 填充和序列化: 分词后,序列被填充以确保输入长度一致,从而在训练期间实现高效的批量处理。
2、模型架构
我们采用基于Transformer的Seq2Seq模型,因其在翻译任务中的有效性而闻名。
- 编码器: 处理输入的C++代码标记,捕获上下文信息并生成表示代码语义的嵌入。
class EncoderLayer(nn.Module): # ... (EncoderLayer类 - 同上)
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
# ... (EncoderLayer的__init__和forward方法 - 同上)
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = PositionwiseFeedforward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
# 自注意力机制及残差连接和层归一化
attn_out = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_out))
# 前馈网络及残差连接和层归一化
ff_out = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_out))
return x
- 解码器: 接收编码器的输出并生成相应的伪代码,利用注意力机制在生成过程中聚焦于输入的相关部分。
class DecoderLayer(nn.Module): # ... (DecoderLayer类 - 同上)
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
# ... (DecoderLayer的__init__和forward方法 - 同上)
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.enc_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = PositionwiseFeedforward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, trg_mask, src_mask):
# 自注意力机制及残差连接和层归一化
self_attn_out = self.self_attn(x, x, x, trg_mask)
x = self.norm1(x + self.dropout(self_attn_out))
# 编码器-解码器注意力机制及残差连接和层归一化
enc_attn_out = self.enc_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(enc_attn_out))
# 前馈网络及残差连接和层归一化
ff_out = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_out))
return x
- 注意力机制: 允许模型根据不同部分的重要性对输入进行加权,使其能够处理长距离依赖并提高翻译准确性。
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout=0.1):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.fc = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([self.head_dim]))
def forward(self, q, k, v, mask=None):
batch_size = q.shape[0]
# 线性投影和重塑
q = self.q_linear(q).view(batch_size, -1, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
k = self.k_linear(k).view(batch_size, -1, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
v = self.v_linear(v).view(batch_size, -1, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
# 注意力机制
energy = torch.matmul(q, k.permute(0, 1, 3, 2)) / self.scale.to(q.device)
if mask is not None:
energy = energy.masked_fill(mask == 0, -1e10)
attention = self.dropout(F.softmax(energy, dim=-1))
output = torch.matmul(attention, v)
# 重塑和拼接头
output = output.permute(0, 2, 1, 3).contiguous()
output = output.view(batch_size, -1, self.d_model)
# 最终线性投影
output = self.fc(output)
return output
3、训练模型
训练涉及教会模型有效地将C++代码映射为其伪代码表示。
- 损失函数: 我们使用交叉熵损失来衡量预测的伪代码与实际伪代码之间的差异。
- 优化器: 使用Adam优化器调整模型权重,在计算效率和收敛速度之间取得平衡。
- 训练循环: 模型在多个epoch中进行训练,每个epoch包括前向传播(预测)和反向传播(误差校正)。
model = Transformer(
src_vocab_size=cpp_vocab_size,
trg_vocab_size=ps_vocab_size,
d_model=256,
num_heads=8,
num_layers=3,
d_ff=512,
dropout=0.1
).to(device)
print(f'模型初始化参数总数为 {sum(p.numel() for p in model.parameters() if p.requires_grad):,}')
LEARNING_RATE = 0.0001
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
criterion = nn.CrossEntropyLoss(ignore_index=cpp_tokenizer.pad_token_id)
NUM_EPOCHS = 20
def train_epoch(model, dataloader, optimizer, criterion, device):
model.train()
epoch_loss = 0
for batch_idx, (src, trg) in enumerate(dataloader):
src, trg = src.to(device), trg.to(device)
optimizer.zero_grad()
output = model(src, trg[:, :-1])
output_reshape = output.contiguous().view(-1, output.shape[-1])
trg_reshape = trg[:, 1:].contiguous().view(-1)
loss = criterion(output_reshape, trg_reshape)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
```(pe)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(dataloader)
4、使用Streamlit进行部署
为了使模型易于访问,我们使用Streamlit进行了部署,Streamlit是一个用户友好的Web应用程序框架。
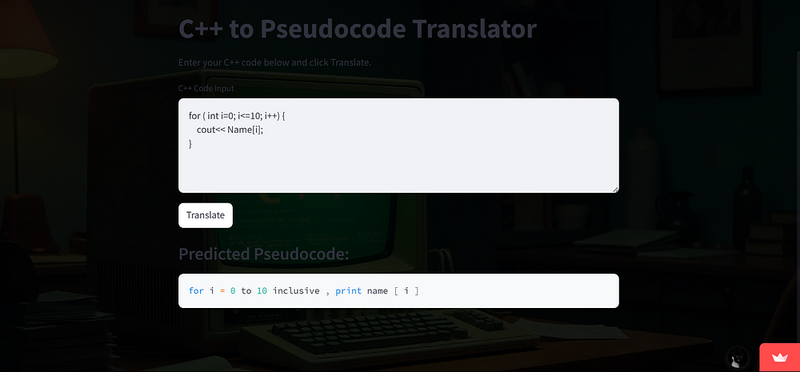
- 用户界面: Streamlit允许我们创建一个交互式界面,用户可以在其中输入C++代码并获得相应的伪代码输出。
- 实时处理: 部署的模型可以实时处理用户的输入,提供即时反馈,从而提升用户体验。

5、挑战与考虑因素
开发C++到伪代码的翻译器带来了独特的挑战:
- 语法多样性: C++允许以多种方式表达相同的逻辑,这使得模型在不同编码风格之间泛化变得困难。
- 复杂代码结构: 处理复杂的构造如模板、宏和复杂的指针操作需要模型对C++语义有深入的理解。
- 伪代码标准化: 伪代码没有通用的标准,导致表示方式存在差异,模型必须学会准确地解释和生成这些伪代码。
6、结束语
构建基于Transformer的Seq2Seq模型将C++代码转换为伪代码是一项多方面的努力,结合了数据预处理、复杂的模型架构和深思熟虑的部署。尽管面临挑战,这样的工具在教育背景、代码文档和增强代码可读性方面具有巨大的潜力。未来的工作可以集中在扩展数据集、改进模型以处理更复杂的代码模式以及提高生成伪代码的自然度。
通过利用先进的NLP技术和强大的部署策略,我们可以弥合代码与人类可读描述之间的差距,使编程更加易用和易懂。
原文链接:Building an AI-Powered C++ to Pseudocode Converter: Technical Insights, Applications, and Challenges
汇智网翻译整理,转载请标明出处
