Arxiv论文检索和摘要工具
随着人工智能的不断发展,促进多个 AI 代理协调的框架的开发已获得显著的关注。多代理系统不再依赖单一、包罗万象的 LLM,而是采用一组专门的代理,每个代理都旨在擅长某项特定任务。这种方法允许更复杂、更细致入微地解决问题,因为代理可以协作、共享信息并利用各自的优势。
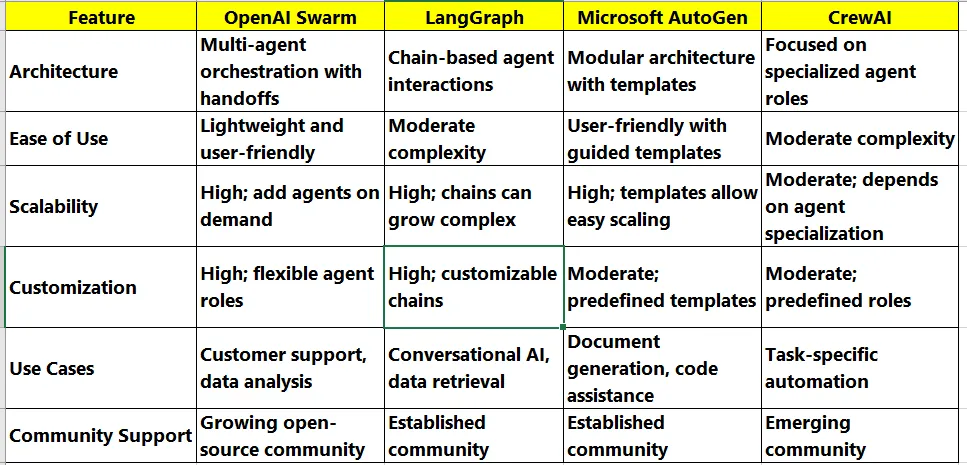
OpenAI Swarm 是一个实验性框架,旨在使多代理协调更易于访问和用户友好。OpenAI 的 Swarm 是一个开创性的框架,它支持创建和管理协作 AI 代理,旨在更有效地处理复杂任务。本文深入探讨了 OpenAI Swarm 及其架构,并与其他著名框架(如 LangGraph、Microsoft AutoGen 和 CrewAI)进行了比较。
1、OpenAI Swarm
OpenAI Swarm 是一个开源框架,旨在简化多代理系统的开发和协调。与传统的单代理模型不同,Swarm 允许多个 AI 代理动态交互、共享任务并协作解决复杂问题。该框架特别适合需要复杂任务协调的应用程序,例如客户服务自动化、数据分析和复杂模拟。
OpenAI Swarm 的主要功能:
- 多代理协作:代理可以动态地进行通信和协作,允许同时处理任务。
- 任务委派和交接:Swarm 支持例程和交接,使代理能够根据上下文转移职责。
- 可扩展性:该框架允许根据需要轻松添加专门的代理,使其适用于各种行业应用。
- 轻量级设计:Swarm 的构建旨在实现用户友好性和高效性,最大限度地减少开销,同时最大限度地控制代理交互。
OpenAI Swarm 的架构以两个主要抽象为中心:代理和交接。
- 代理:每个代理都封装了针对特定任务量身定制的特定指令和工具。例如,一个代理可能负责处理客户查询,而另一个代理负责处理交易。
- 交接:当任务需要不同的技能组合或上下文时,此机制允许代理无缝地将控制权移交给另一个代理。此功能可增强协作和效率。
该架构强调模块化,允许开发人员将 Swarm 集成到现有系统中或从头开始构建新的多代理应用程序。该框架在 OpenAI 的 Chat Completions API 上运行,确保可扩展性和易于测试。
2、OpenAI Swarm vs. 其他多代理框架
架构:
- OpenAI Swarm 专注于轻量级架构,强调通过切换在代理之间进行直接通信。与传统框架相比,这种设计允许更流畅的交互模型。
- LangGraph 采用基于链的方法,其中代理按顺序链接。虽然功能强大,但这会导致管理交互的复杂性增加。
- Microsoft AutoGen 采用模块化架构,允许开发人员为各种任务创建模板。这种结构提供了灵活性,但可能需要更多的前期配置。
- CrewAI 强调代理之间的专业化,但由于其预定义的角色,可能会限制灵活性
易用性:
- Swarm 的简单性使希望实现多代理系统的开发人员可以轻松访问它,而无需大量开销。
- 由于其模块化特性,LangGraph 需要更复杂的设置过程。
- Microsoft AutoGen 提供用户友好的引导模板,可简化部署,但可能无法提供与 Swarm 相同级别的控制。
- CrewAI 取得了平衡,但可能无法提供与 Swarm 相同级别的直接性。
可扩展性:
- 所有四个框架都支持可扩展性;但是,Swarm 能够动态添加专门的代理,这在快速变化的环境中具有优势。
- LangGraph 通过其链接机制提供可扩展性,但随着复杂性的增加,可能需要额外的配置。
- Microsoft AutoGen 通过其模板化方法实现高可扩展性,但可能需要在模板设计中进行仔细规划。
- CrewAI 的可扩展性取决于其代理的专业化。
定制:
- OpenAI Swarm 在定制方面表现出色,允许开发人员轻松为每个代理定义特定角色。
- LangGraph 还提供高度定制,但在其链结构的限制范围内。
- Microsoft AutoGen 根据可调整的预定义模板提供适度定制,但可能不允许进行大量修改。
- CrewAI 根据预定义角色提供适度定制。
用例:
- Swarm 非常适合动态协作至关重要的客户服务自动化和数据分析中的应用程序。
- LangGraph 非常适合需要复杂的数据检索过程的对话式 AI 应用程序。
- 由于其结构化的模板,Microsoft AutoGen 在文档生成和代码辅助任务方面表现出色。
- CrewAI 最适合在需要特定任务自动化的环境中使用。
社区支持:
- 作为一个新兴框架,OpenAI Swarm 拥有一个不断壮大的社区,鼓励协作和创新。
- LangGraph 受益于一个成熟的社区,为开发人员提供丰富的资源。
- 由于与 Microsoft 的生态系统集成,Microsoft AutoGen 拥有强大的社区支持。
- CrewAI 的社区仍在发展,但随着对专业代理系统的兴趣日益浓厚,它显示出良好的前景。
3、什么是多代理编排?
多代理编排 (MAO) 是指多个自主代理的系统协调和管理,这些代理共同完成复杂任务或解决问题。这种编排涉及在代理之间智能地路由任务、在交互之间维护上下文以及确保每个代理在更广泛的系统中有效运行。MAO 在各个领域越来越重要,包括客户服务、机器人技术和 AI 驱动的应用程序。
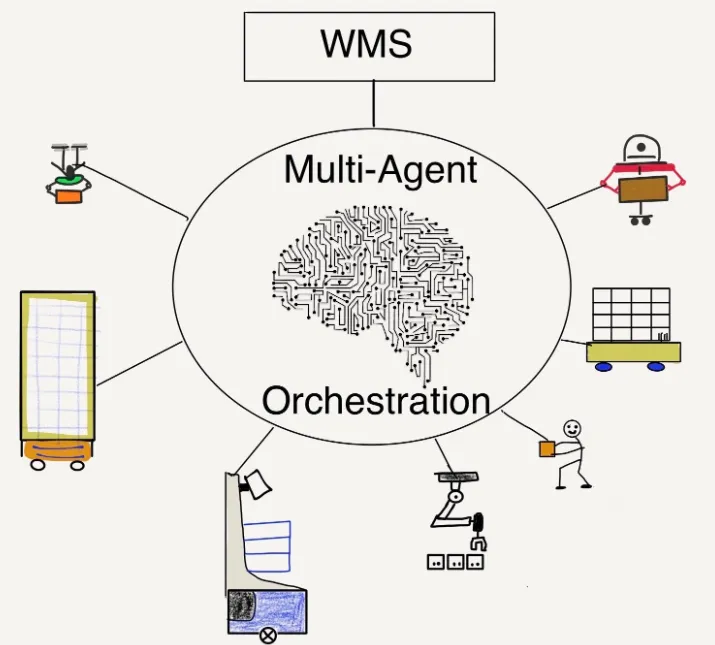
多代理编排的主要功能:
- 智能任务路由:MAO 系统分析用户请求,并根据上下文和代理功能确定最适合每个任务的代理。
- 上下文管理:在多个代理之间维护对话上下文可确保连贯的交互,即使在多轮对话期间也是如此。
- 可扩展性:MAO 框架可以轻松整合新代理或功能,使系统能够适应不断变化的需求。
- 互操作性:来自不同供应商的不同代理可以无缝协作,从而提高整体系统效率。
典型的多代理编排系统的架构由几个核心组件组成:
- 编排器:管理代理之间信息流的中央组件。它路由请求、维护上下文并将响应返回给用户。
- 代理:旨在执行特定任务的单个自治实体。每个代理可能具有自己的一组功能,并且可以专门用于不同的领域。
- 分类器:分析用户输入并确定处理请求的适当代理的基本组件。它使用机器学习算法来提高准确性。
- 任务管理器:负责管理分配给代理的任务的生命周期,包括根据需要创建、更新和删除任务。
- 通信基础设施:允许代理相互通信并与编排器通信的底层网络。这可能包括 API、消息传递协议和数据存储解决方案。
4、技术栈
OpenAI Swarm 默认使用 OpenAI Chat 完成功能,这需要 openai_api_key。这将产生费用。现在,为了避免成本并完全本地化,我们将利用 Ollama 的 OpenAI 兼容端点进行聊天完成
4.1 什么是 Ollama?
Ollama 是一种工具,允许用户在自己的设备上完全安全地执行 AI 模型。通过这种方式,Ollama 赋予开发人员权力,并为他们提供对应用程序中使用的数据的更多控制权,以及对这些应用程序的保护。可以定制以享受本地执行能力——使其适合那些寻求拥抱人工智能发明而不必向第三方公开其系统的组织。
4.2 代码实现
安装所需的依赖项:
pip install git+https://github.com/openai/swarm.git
pip install langchain langchain_community langchain_ollama
pip install arxiv2text
pip install arxiv
pip install pandas设置 ollama qwen2.5:3b 模型:
ollama run qwen2.5:3b
pulling manifest
pulling 5ee4f07cdb9b... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 1.9 GB
pulling 66b9ea09bd5b... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 68 B
pulling eb4402837c78... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 1.5 KB
pulling b5c0e5cf74cf... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 7.4 KB
pulling 161ddde4c9cd... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success在 .env 文件中设置模型名称:
LLM_MODEL=qwen2.5:3b导入所需的库:
import os
from dotenv import load_dotenv
load_dotenv()
model = os.getenv('LLM_MODEL')使用 Ollama OpenAI 兼容端点实例化 openai swarm:
from openai import OpenAI
ollama_client = OpenAI(
base_url='http://localhost:11434/v1',
api_key='ollama' # required but unused
)
#
client= Swarm(client=ollama_client)辅助函数根据提供的主题返回 axriv 论文详细信息:
import arxiv
import pandas as pd
def get_url_topic(topic):
# Prompt user for the topic to search
print(topic)
#topic = "ChunkRag"
# Set up the search parameters
search = arxiv.Search(
query=topic,
max_results=1, # You can adjust this number as needed
sort_by=arxiv.SortCriterion.SubmittedDate,
sort_order=arxiv.SortOrder.Descending,
)
# Prepare a list to store results
all_data = []
# Execute the search and collect results
for result in search.results():
#print(result)
paper_info = {
"Title": result.title,
"Date": result.published.date(),
"Id": result.entry_id,
"Summary": result.summary,
"URL": result.pdf_url,
}
all_data.append(paper_info)
if all_data:
results = "\n\n".join([f"Title:{d['Title']}\nDate:{d['Date']}\nURL:{d['URL']}\nSummary:{d['Summary']}"for d in all_data])
#print(results)
return results测试函数:
print(get_url_topic("ChunkRag"))
##### Response ######################################
ChunkRag
C:\Users\PLNAYAK\AppData\Local\Temp\ipykernel_17056\1349765600.py:20: DeprecationWarning: The 'Search.results' method is deprecated, use 'Client.results' instead
for result in search.results():
Number of papers extracted: 1
Title:ChunkRAG: Novel LLM-Chunk Filtering Method for RAG Systems
Date:2024-10-25
URL:http://arxiv.org/pdf/2410.19572v3
Summary:Retrieval-Augmented Generation (RAG) systems using large language models
(LLMs) often generate inaccurate responses due to the retrieval of irrelevant
or loosely related information. Existing methods, which operate at the document
level, fail to effectively filter out such content. We propose LLM-driven chunk
filtering, ChunkRAG, a framework that enhances RAG systems by evaluating and
filtering retrieved information at the chunk level. Our approach employs
semantic chunking to divide documents into coherent sections and utilizes
LLM-based relevance scoring to assess each chunk's alignment with the user's
query. By filtering out less pertinent chunks before the generation phase, we
significantly reduce hallucinations and improve factual accuracy. Experiments
show that our method outperforms existing RAG models, achieving higher accuracy
on tasks requiring precise information retrieval. This advancement enhances the
reliability of RAG systems, making them particularly beneficial for
applications like fact-checking and multi-hop reasoning根据提供的 URL 提取 arxiv 论文内容的辅助函数:
rom typing import List, Dict
from langchain_ollama import ChatOllama
from arxiv2text import arxiv_to_text
from openai import OpenAI
ollama_client = OpenAI(
base_url='http://localhost:11434/v1',
api_key='ollama' # required but unused
)
class SummarizerAgent:
def __init__(self):
self.llm = ChatOllama(model="llama3.2:1b",
temperature=0.0,
num_predict=1000)
def extract_content(self,url:str) -> str:
# Replace with your specific arXiv PDF URL
pdf_url = url
extracted_text = arxiv_to_text(pdf_url)
return extracted_text
def summarize_paper(self, paper: Dict,content: str) -> str:
"""
Summarize a single paper using Llama2
"""
prompt = f"""
Please provide a concise summary of the following research paper:
Title: {paper['title']}
Authors: {', '.join(paper['authors'])}
Abstract: {paper['summary']}
Content : {content}
Generate a clear ,concise and informative summary in no more than 6-8 sentences.
"""
return self.llm.predict(prompt)
def summarize_papers(self, papers: List[Dict]) -> List[Dict]:
"""
Summarize multiple papers
"""
summarized_papers = []
for paper in papers:
summary = self.summarize_paper(paper)
summarized_papers.append({
'title': paper['title'],
'summary': summary,
'original_paper': paper
})
return summarized_papers from langchain_ollama import ChatOllama
llm =ChatOllama(model="llama3.2:1b",
temperature=0.0,
num_predict=1000)
#
def extract_content(url):
summ = SummarizerAgent()
content = summ.extract_content(url)
return content测试辅助函数:
content = extract_content("http://arxiv.org/pdf/2410.19572v3")
#############Response ###########################################
ChunkRAG: Novel LLM-Chunk Filtering Method for RAG Systems
Ishneet Sukhvinder Singh
Ritvik Aggarwal
Aslihan Akalin
Kevin Zhu
Ibrahim Allahverdiyev
Sean O’Brien
Muhammad Taha
Algoverse AI Research
asli@algoverse.us, kevin@algoverse.us, seobrien@ucsd.edu
4
2
0
2
t
c
O
0
3
]
L
C
.
s
c
[
3
v
2
7
5
9
1
.
0
1
4
2
:
v
i
X
r
a
Abstract
Retrieval-Augmented Generation (RAG) sys-
tems using large language models (LLMs) of-
ten generate inaccurate responses due to the
retrieval of irrelevant or loosely related infor-
mation. Existing methods, which operate at the
document level, fail to effectively filter out such
content. We propose LLM-driven chunk filter-
ing, ChunkRAG, a framework that enhances
RAG systems by evaluating and filtering re-
trieved information at the chunk level. Our
approach employs semantic chunking to divide
documents into coherent sections and utilizes
LLM-based relevance scoring to assess each
chunk’s alignment with the user’s query. By
filtering out less pertinent chunks before the
generation phase, we significantly reduce hallu-
cinations and improve factual accuracy. Exper-
iments show that our method outperforms ex-
isting RAG models, achieving higher accuracy
on tasks requiring precise information retrieval.
This advancement enhances the reliability of
RAG systems, making them particularly ben-
eficial for applications like fact-checking and
multi-hop reasoning.
1
Introduction
LARGE LANGUAGE MODELS (LLMs) have
made significant strides in the development
of retrieval-augmented generation (RAG) systems,
which combine retrieval mechanisms with power-
ful language models to produce responses based
on external knowledge. However, despite these
advancements, a persistent issue remains: the re-
trieval of irrelevant or weakly related information
during the document-fetching process. Current re-
trieval techniques, including reranking and query
rewriting, not only fail to filter out lots of irrele-
vant chunks of information in the retrieved docu-
ments but also lead to a series of problems with fac-
tual inaccuracies, irrelevance, and hallucinations in
the responses generated (Zhang and Others, 2023;
Mallen et al., 2023).
1
Figure 1: Flowchart
Traditionally, RAG systems retrieve large
amounts of the text of entire documents or lengthy
portions thereof, assuming that it is likely that these
lengthy fragments will contain the relevant informa-
tion. Such systems very rarely examine the sections
or paragraphs of the retrieved documents individu-
ally and, therefore, there is a strong likelihood that
irrelevant or only partially related information will
flow into the generation stage. Moreover, this is
further worsened by the fact that language models
generate fluent text without being able to verify
the information they use for generation. Relevant
or misleading chunks consequently distort the out-
come of such models severely, reducing the sys-
tem’s reliability, especially in critical applications
such as open-domain question answering and multi-
hop reasoning (Ji et al., 2023; Min et al., 2023).
Fig. 1: The figure shows that without chunk
filtering (top), irrelevant information like other
French cities is included in the response. The
LLM-driven chunk filtering (bottom), however, re-
moves unnecessary content, delivering the precise
answer, "The capital of France is Paris." A few
retrieval-related methods, Corrective RAG (CRAG)
and Self-RAG, have attempted to overcome these
hurdles by sophisticating retrieval. CRAG focuses
on retrieving "corrections" post-hoc to the errors
that occur in retrieval, whereas Self-RAG injects
self-reflection into the generation stage itself to
avoid inaccuracies. Both of these processes occur
at the document level and lack filtering sufficient
enough for individual retrieved chunks of text. This
document-level method enhances the broader rele-
vance of the retrieval but does nothing to prevent
irrelevant chunks from rolling over into the gener-
ated response (Shi et al., 2023). Lack of control
over the granularity of the content retrieved makes
RAG systems vulnerable to including undesirable
or misleading information in their output, thus ulti-
mately nullifying the performance.
The solution to this challenge lies in the novel ap-
proach: LLM-driven chunk filtering, ChunkRAG.
Our method operates on a finer level of granularity
than classical systems and, in fact, supports chunk-
level filtering of retrieved information. Rather than
judging entire documents to be relevant, our system
goes both for the user query and individual chunks
within retrieved documents. The large language
model evaluates semantic relevance of each chunk
with respect to the user’s query; this makes the sys-
tem capable of filtering out irrelevant or weakly
related chunks even before they get into the gener-
ation stage. This chunk-level filtering in turn aims
to enforce factual accuracy on the final answer by
drawing only the most relevant information on the
generation. This approach is particularly promising
for knowledge-intensive tasks, such as multi-hop
reasoning and fact-checking: precision is the ulti-
mate prize here. That is, in tasks where accuracy is
paramount, our approach stands best (Piktus et al.,
2021; Rony et al., 2022).
2 Literature Review
Redundancy in retrieved information can diminish
the effectiveness of Retrieval-Augmented Genera-
tion models by introducing repetitive or irrelevant
data, which hampers the model’s ability to gener-
ate coherent and unique responses. One prevalent
approach to mitigating redundancy involves the use
of cosine similarity to evaluate and remove dupli-
cate or overly similar content from the retrieved
documents.
Cosine Similarity in Redundancy Removal: Co-
sine similarity measures the cosine of the angle
between two non-zero vectors of an inner product
space, which quantifies the similarity between the
two vectors irrespective of their magnitude. In the
context of RAG, it is employed to compare textual
embeddings of retrieved chunks to identify and
eliminate redundant content, enhancing the diver-
sity of the information available for generation (Liu
et al., 2023).
Multi-Meta-RAG for Multi-Hop Queries: Ad-
dressing the challenges of multi-hop queries, Multi-
Meta-RAG introduces a database filtering mecha-
nism using metadata extracted by large language
models (LLMs). By incorporating LLM-extracted
metadata, this approach filters databases to retrieve
more relevant documents that contribute to answer-
ing complex queries requiring reasoning over multi-
ple pieces of information (Smith et al., 2023). This
method reduces redundancy by ensuring that only
pertinent documents are considered, thereby im-
proving the coherence of the generated responses.
Query Rewriting for Enhanced Retrieval: The
paper
titled "Query Rewriting for Retrieval-
Augmented Large Language Models" proposes a
"Rewrite-Retrieve-Read" framework to bridge the
gap between input text and the necessary retrieval
knowledge (Johnson and Lee, 2023). A trainable
query rewriter adapts queries using reinforcement
learning based on feedback from the LLM’s perfor-
mance. This approach enhances retrieval accuracy
by reformulating queries to better align with rele-
vant documents, thus minimizing the retrieval of
redundant or irrelevant information.
Self-RAG: Learning through Self-Reflection:
Self-RAG puts forth a framework that enhances
LLM quality and factuality through on-demand re-
trieval and self-reflection (Li et al., 2023). It trains
the model to adaptively retrieve passages, generate
text, and reflect on its own outputs using special
tokens called reflection tokens. This method allows
the model to critique and refine its responses, re-
ducing redundancy by discouraging the inclusion
of irrelevant or repetitive information.
We introduce a new model, ChunkRAG that em-
phasizes an innovative chunking strategy aimed at
further reducing redundancy and improving the ef-
fectiveness of RAG models. Our approach involves
segmenting documents into semantically coherent
and non-overlapping chunks that are more aligned
with the specific information needs of the query.
Despite advancements in Retrieval-Augmented
2
Generation systems like RAG, CRAG, Self-RAG,
and Self-CRAG, limitations persist in effectively
retrieving and utilizing relevant information due
to fixed size chunking, static relevance thresholds,
and single-pass relevance scoring. Our approach
addresses these issues through several key innova-
tions: implementing semantic chunking for top-
ically coherent chunks, employing LLM-based
query rewriting to refine user queries, introduc-
ing advanced LLM-based relevance scoring with
self-reflection and a critic LLM for more accurate
assessments, utilizing dynamic threshold determi-
nation to adaptively filter relevant information, and
incorporating initial filtering methods to improve
efficiency by reducing redundancy and prioritizing
chunks. These enhancements collectively surpass
traditional models by providing more precise re-
trieval and contextually appropriate answers, lead-
ing to significant improvements in performance as
demonstrated by standard evaluation metrics.
3 Methodology
The primary aim of this work is to reduce irrele-
vance and hallucinations in the responses generated
by Retrieval-Augmented Generation (RAG) sys-
tems through a novel, fine-grained filtering process
that evaluates the relevance of each chunk of re-
trieved information before it is used in the response
generation phase. Below, we describe the steps
involved in a detailed, precise, and reproducible
manner.
3.1 Step 1: Semantic Chunking
1. Input Preparation: Start with a docu-
ment D and break it down into sentences
using a sentence tokenizer (e.g., NLTK’s
sent_tokenize function).
2. Embedding Generation:
Use
embedding model
pre-trained
text-embedding-3-small)
vector representation for each sentence.
to create
a
(e.g.,
a
3. Chunk Creation: Calculate the similarity
between consecutive sentences using cosine
similarity. If similarity drops below a thresh-
old (θ = 0.7), mark a new chunk boundary.
Group sentences accordingly, ensuring each
chunk is under 500 characters.
3.2 Step 2: Vector Store Creation
1. Embedding the Chunks: Convert each
chunk into an embedding using the same
3
model as above.
2. Storing Embeddings: Store all chunk embed-
dings in a vector database for easy retrieval
during query matching.
3.3 Step 3: Retriever Initialization
1. Setup Retriever: Initialize the retriever to
compare incoming query embeddings with
stored chunk embeddings to find the most rel-
evant chunks.
3.4 Step 4: Query Rewriting
1. Query Enhancement: Rewrite the user’s
original query using a language model (e.g.,
GPT-4omini) to make it more suitable for re-
trieval.
3.5 Step 5: Initial Filtering
1. Duplicate Removal: Use TF-IDF and cosine
similarity to eliminate duplicate or overly sim-
ilar chunks (similarity > 0.9).
2. Sort by Relevance: Sort
the remaining
chunks based on similarity to the rewritten
query.
3.6 Step 6: Advanced Relevance Scoring
1. Initial Scoring: Assign a relevance score to
each chunk using an LLM.
2. Score Refinement: Use self-reflection and a
critic model to refine the initial scores, then
calculate an average to obtain the final score.
3.7 Step 7: Thresholding for Relevance
1. Set Dynamic Threshold: The LLM analyzes
the distribution of final scores and suggests an
optimal threshold for chunk relevance.
2. Filter Chunks: Retain only chunks with
scores above the threshold.
3.8 Step 8: Hybrid Retrieval and Re-Ranking
1. BM25 Retriever: In parallel, a BM25 re-
triever is implemented to capture keyword-
based retrieval. The BM25 retriever is com-
bined with the LLM-based retriever using an
ensemble approach with equal weights (0.5
each), ensuring both semantic and keyword-
based retrieval are balanced.
2. Re-ranking Chunks: Cohere’s reranking
model (rerank-englishv3.0) is applied to
rank the chunks by relevance to address the
“Lost in the Middle” problem, ensuring the
most relevant chunks are prioritized in the fi-
nal retrieval set.
3.9 Step 9: Answer Generation
While our primary experiments focused on PopQA,
ChunkRAG is designed for scalability, and future
evaluations could include additional datasets like
Biography (Min et al., 2023) for long-form genera-
tion, PubHealth (Zhang et al., 2023) for true/false
question answering, and Arc-Challenge (Bhaktha-
vatsalam et al., 2021) for multi-choice questions.
1. Compile Context: Collect the most relevant
4.3 Experimental Setup
chunks to use as context.
2. Generate Response: Use an LLM to generate
an answer based on the context, ensuring that
only the information from retrieved chunks is
used.
3.10 Step 10: Evaluation
1. Accuracy Calculation: Compare the gener-
ated answers against a set of correct answers
to evaluate performance:
Accuracy =
Number of Correct Answers
Total Number of Questions
(1)
4 Experiments
To evaluate the effectiveness of ChunkRAG in re-
ducing irrelevance and hallucinations in retrieval-
augmented generation, we conducted a series of
experiments using the PopQA dataset. This sec-
tion details the objectives, datasets, experimental
design, baseline comparisons, and results.
4.1 Objectives
The primary objective of our experiments was to
assess ChunkRAG’s performance in accurately re-
trieving relevant information and minimizing hal-
lucinations, especially on tasks requiring high pre-
cision in short-form question answering. We hy-
pothesized that the fine-grained, chunk-level filter-
ing would improve retrieval accuracy compared to
document-level approaches.
4.2 Tasks and Datasets
ChunkRAG was evaluated on the PopQA dataset
(Mallen et al., 2023), chosen for its alignment
with our model’s goal of precise, fact-based re-
trieval. PopQA is a benchmark dataset designed
for short-form question answering and contains
diverse questions requiring concise, accurate re-
sponses.
Its focus on factual precision makes
it an ideal testbed for assessing the capabilities
of retrieval-augmented generation (RAG) systems.
We conducted our experiments with computa-
tional constraints, implementing ChunkRAG on the
PopQA dataset to evaluate its retrieval accuracy and
response quality. The cosine similarity threshold
for semantic chunking was set to θ = 0.7, marking
chunk boundaries when similarity between con-
secutive sentences dropped below this level. Each
chunk was limited to a maximum of 500 characters,
ensuring focused and relevant segments.
In addition to the chunking process, we em-
ployed initial filtering via TF-IDF and cosine sim-
ilarity for duplicate removal, followed by an ad-
vanced relevance scoring system incorporating a
critic model. These settings were chosen based on
preliminary analyses to optimize for relevance and
accuracy.
4.4 Baselines
We compared ChunkRAG to several baselines, both
with and without retrieval mechanisms:
Baselines Without Retrieval: This group in-
cludes several large language models (LLMs) with-
out retrieval mechanisms, such as LLaMA2-7B and
Alpaca-7B (Dubois et al., 2023), selected for their
performance in various natural language processing
tasks. Additionally, CoVE65B (Dhuliawala et al.,
2024) was included to measure factual accuracy
improvements in non-retrieval LLMs.
Baselines With Retrieval: For
retrieval-
augmented methods, we evaluated Standard
RAG (Lewis et al., 2020), Self-RAG (Asai et al.,
2024), and CRAG (Your et al., 2024). CRAG
serves as a direct comparison due to its corrective
strategies in retrieval quality,
lacks
chunk-level filtering. The advanced models, such
as Ret-ChatGPT and RetLLaMA-chat, were also
included for proprietary comparisons.
though it
4.5 Evaluation Metrics
The primary evaluation metric was accuracy, de-
fined as the percentage of generated responses that
exactly matched the ground-truth answers. We
4
also assessed semantic accuracy, where responses
semantically equivalent to the ground truth, as eval-
uated by an LLM-based similarity checker, were
counted as correct. This approach ensured a com-
prehensive measure of both factual accuracy and
contextual relevance.
Accuracy =
Number of Correct Answers
Total Number of Questions
(2)
4.6 Results and Analysis
As shown in Table 1, ChunkRAG achieved an ac-
curacy of 64.9 on PopQA, surpassing all baselines
in the same category. Compared to CRAG, which
achieved an accuracy of 54.9, our model shows a
performance improvement of 10 percentage points.
This increase is significant, especially for multi-
step reasoning tasks, where errors can compound
across steps.
The enhanced performance is primarily due to
ChunkRAG’s chunk-level filtering, which reduces
the inclusion of irrelevant or weakly related in-
formation. By focusing on semantically relevant
chunks, the generation of factually accurate re-
sponses was substantially improved. Furthermore,
our self-reflective scoring mechanism reduced re-
trieval errors by providing a finer relevance assess-
ment at the chunk level.
Method
LLaMA2-13B
Ret-LLaMA2-13B
ChatGPT
Ret-ChatGPT
LLaMA2-7B
Alpaca-7B
Standard RAG
CRAG
Self-RAG
ChunkRAG (Ours)
PopQA Accuracy (%)
20.0
51.8
29.3
50.8
14.7
23.6
50.5
54.9
50.5
64.9
Table 1: Performance Comparison Across Methods on
PopQA Dataset
4.7 Observations and Insights
Our experiments demonstrated that chunk-level fil-
tering led to a notable improvement in response
accuracy and relevance. By dividing text into
semantically coherent chunks, ChunkRAG was
able to reduce irrelevant or tangential information,
thus enhancing factual accuracy. The LLM’s self-
reflective scoring system further contributed to er-
ror reduction by refining chunk relevance.
Future work will explore the scalability of
ChunkRAG on additional datasets, including Biog-
raphy, PubHealth, and Arc-Challenge, to validate
its versatility. Addressing computational efficiency
is also planned to enable broader applications of
ChunkRAG.
5 Analysis
In this section, we evaluate the performance of
ChunkRAG against existing retrieval-augmented
generation (RAG) methods. We present an analysis
based on empirical results obtained from standard
benchmarks.
Table 2: Performance Comparison Across Methods
(PopQA Accuracy Only)
Method
PopQA (Accuracy)
LLMs trained with proprietary data
LLaMA2-C_13B
Ret-LLaMA2-C_13B
ChatGPT
Ret-ChatGPT
20.0
51.8
29.3
50.8
Baselines without retrieval
14.7
23.6
14.7
14.3
-
Baselines with retrieval
LLaMA2_7B
Alpaca_7B
LLaMA2_13B
Alpaca_13B
CoVE_65B
LLaMA2_7B
Alpaca_7B
SAIL
LLaMA2_13B
Alpaca_13B
LLaMA2-hf_7B
RAG
CRAG
Self-RAG
Self-CRAG
ChunkRAG
38.2
46.7
-
45.7
46.1
50.5
54.9
50.5
49.0
64.9
5.1 Evaluation Metrics
We used accuracy as the primary evaluation metric,
calculated as the percentage of generated responses
that exactly match the ground-truth answers. Addi-
tionally, we considered semantic accuracy, where
responses that are semantically equivalent to the
ground truth (as evaluated by an LLM-based seman-
tic similarity checker) are also counted as correct.
Accuracy =
Correct Answers
Total Questions
(3)
5
5.2 Comparison and Impact
As depicted in Table 1, our method achieved an
accuracy of 64.9, substantially outperforming all
baselines in the same category. Notably, compared
to the closest baseline, CRAG (54.9 accuracy), our
method exhibits a performance gain of 10 percent-
age points.
While a 10 percentage point increase may seem
incremental, it translates into an exponential im-
provement in output effectiveness in practical ap-
plications. This is particularly evident when consid-
ering the error rates and their impact on the overall
user experience.
5.3 Multi-Step Processes
In applications requiring multi-hop reasoning or
sequential decision-making, errors can compound
exponentially. The probability of the system provid-
ing correct answers across multiple steps is given
by:
P (correct over n steps) = (accuracy)n
(4)
As the number of steps increases, the gap be-
tween the success probabilities widens exponen-
tially. For a 3-step process, our method’s success
rate is 66% higher than CRAG’s. This exponential
improvement is especially important in complex
tasks where each additional step compounds the
risk of error, namely relevant to OpenAI’s advanced
models such as o1 where the language model uti-
lizes multi-hop reasoning, relying on spending time
"thinking" before it answers, making it more effi-
cient in complex reasoning tasks, science and pro-
gramming.
5.4 Observations and Insights
The notable improvement attained with our tech-
nique is mainly due to chunk-level filtering and
fine-grained relevance assessment. We divided
the text into semantically meaningful chunks,
which reduced the generation of irrelevant or
In processing the
weakly related information.
chunk filtering’s contextually relevant data, the gen-
eration of factually accurate and coherent responses
was significantly enhanced.
Moreover,
the self-reflective LLM scoring
method, in which the model grades itself and then
changes accordingly, led to a significant decrease
in retrieval errors. Unlike regular retrieval methods
that do not have a filtering mechanism at the doc-
ument section level, our method can extract more
meaningful and relevant information that directly
affects the reliability of the generated responses.
5.5 Future Work
In our present studies, we have only tested PopQA
but the design of ChunkRAG is for scalability
purposes. In the upcoming assessments, we will
also introduce new datasets including Biography
for long-form generation, PubHealth for true/false
questions, and Arc-Challenge for multiple-choice
questions. The implementation of these trials will
thus reinforce the evidence of ChunkRAG’s versa-
tility and adaptability to different types of genera-
tion tasks, although this will be conditional on the
availability of computing resources.
6 Conclusion
In this paper, we introduced ChunkRAG, a novel
LLM-driven chunk filtering approach aimed at im-
proving the precision and factuality of retrieval-
augmented generation systems. In our experiments,
which were conducted on the PopQA dataset,
ChunkRAG has clearly demonstrated superiority
over existing baselines, and thus has achieved a
significant performance boost of 10 percentage
points, which was higher than the closest bench-
mark, CRAG. The chunk-level filtering technique
guaranteed that only the relevant and contextually
correct information was included during the re-
sponse generation, resulting in better reliability
and accuracy of generated answers. This method is
particularly useful for applications that require im-
mense amounts of facts, such as multi-hop reason-
ing and decision-making that involve many interde-
pendent parameters. We believe that ChunkRAG
is a big step towards solving the problems of ir-
relevant or hallucinated material in LLM-based
retrieval systems.
7 Limitations
ChunkRAG, in spite of its benefits, has a number
of drawbacks that need to be taken into account.
Firstly, the method relies heavily on the effective-
ness of chunk segmentation and the quality of the
embeddings used for chunk relevance assessment.
Mistakes in the primary division can create irrel-
evant data that will decrease the quality of the re-
sponse. Secondly, the costs from the multi-level
score—integrating both LLM and critic LLM evalu-
6
ations at the initial level—can be high, particularly
during the scaling of the method to larger datasets
or the deployment of it in real-time systems. Addi-
tionally, while ChunkRAG demonstrated positive
outcomes in the use of the PopQA dataset, the
verifiability of its use in other domains and the per-
formance when operating through long-form gen-
eration tasks has not been thoroughly analyzed due
to resource limitations. Future studies should con-
centrate on the optimization of the computational
efficiency of ChunkRAG and its evaluation over
diverse datasets and in real-world applications.
References
A. Asai et al. 2024. Self-rag: Self-reflective retrieval-
augmented generation for knowledge-intensive tasks.
In Proceedings of the Annual Meeting of the Associa-
tion for Computational Linguistics (ACL).
S. Min et al. 2023. Self-reflective mechanisms for im-
proved retrieval-augmented generation. In Proceed-
ings of the 61st Annual Meeting of the Association
for Computational Linguistics (ACL).
A. Piktus et al. 2021. The role of chunking in retrieval-
augmented generation. In Proceedings of the Con-
ference on Neural Information Processing Systems
(NeurIPS).
M. S. Rony et al. 2022. Fine-grained document retrieval
for fact-checking tasks. In Proceedings of the 2022
Conference on Empirical Methods in Natural Lan-
guage Processing (EMNLP).
Y. Shi et al. 2023. Corrective retrieval in retrieval-
augmented generation systems. In Proceedings of
the International Conference on Machine Learning
(ICML).
T. Smith et al. 2023. Multi-meta-rag for multi-hop
queries using llm-extracted metadata. In Proceedings
of the International Conference on Computational
Linguistics (COLING).
S. Bhakthavatsalam et al. 2021. Multi-hop reasoning
In Proceedings of the
with graph-based retrieval.
59th Annual Meeting of the Association for Compu-
tational Linguistics (ACL).
S. Your et al. 2024. Crag: Corrective retrieval-
In Proceedings of the An-
augmented generation.
nual Meeting of the Association for Computational
Linguistics (ACL).
A. Zhang and Others. 2023. Another title of the paper.
arXiv preprint arXiv:2302.56789.
A. Zhang et al. 2023. Hallucination in large language
models: A comprehensive survey. arXiv preprint
arXiv:2301.12345.
F. Dhuliawala et al. 2024. Cove65b: Enhancing fac-
tual accuracy through iterative engineering. arXiv
preprint arXiv:2401.12345.
Y. Dubois et al. 2023.
Instruction tuning for open-
domain question answering. In Advances in Neural
Information Processing Systems (NeurIPS).
Z. Ji et al. 2023. Survey of hallucination in generative
models. arXiv preprint arXiv:2302.02451.
R. Johnson and T. Lee. 2023. Query rewriting for
retrieval-augmented large language models. In Pro-
ceedings of the International Conference on Machine
Learning (ICML).
P. Lewis et al. 2020. Retrieval-augmented generation
for knowledge-intensive nlp tasks. In Advances in
Neural Information Processing Systems, volume 33,
pages 9459–9474.
C. Li et al. 2023. Factually consistent generation using
self-reflection. In Proceedings of the 61st Annual
Meeting of the Association for Computational Lin-
guistics (ACL).
S. Liu et al. 2023. Redundancy removal in retrieval-
augmented generation using cosine similarity.
In
Proceedings of the Conference on Empirical Methods
in Natural Language Processing (EMNLP).
J. Mallen et al. 2023. Enhancing retrieval-augmented
In Proceedings of
generation with fact-checking.
the Conference on Empirical Methods in Natural
Language Processing (EMNLP).
7创建URL代理:
url_agent = Agent(name="Extract URL Assistant",
instruction="Get the arxiv search results for the given topic.",
functions=[get_url_topic],
model=model)创建url抽取代理:
extract_url = Agent(name="URL Assistant",
instruction="Get the URL from the given content.",
model=model)创建总结代理:
content_agent = Agent(name="Extract Summary Assistant",
instruction="""Generate a clear ,concise and informative summary of the arxiv paper.The Summary should include the authors of the paper , the date it was published and
the concept behind the topic explained i the paper.""",
functions=[extract_content],
model=model)测试总结代理:
summary_response = client.run(
agent=content_agent,
messages=[{"role": "user", "content": content }],# retrive paper content
)
print(summary_response.messages[-1]["content"])
################## Response #######################
Here is the corrected version of your text, with some typographical and structural changes to improve readability:
---
# ChunkRAG: Fine-Grained Document Retrieval for Enhanced Relevance Assessment
The paper introduces **ChunkRAG**, a novel framework that employs chunking within retrieval-augmented generation (RAG) techniques. This method leverages both the strengths of large language models (LLM) and a critical LLM to accurately assess relevance in document retrieval tasks.
## Key Components & Innovations
1. **Primary Divisions**: The primary goal is to ensure that each relevant chunk from the original text is captured, thereby preventing any misidentification as irrelevant.
2. **Fine-Grained Assessments**: By subdividing larger documents into manageable chunks, it enhances the accuracy of retrievals at an atomic level. This allows for more precise and targeted assessment across various documents.
3. **Chunk-Specific Evaluation**: Employing multi-level score systems that integrate both LLM and critical LLM evaluations provides a robust evaluation framework based on both quality score and contextual relevance.
## Challenges & Considerations
In the implementation of ChunkRAG, several important considerations arise:
1. **Potential Irrelevant Data**: The primary division step may introduce irrelevant data into the system, leading to lowered output quality.
2. **Scalability Issues**: Integrating LLMs in a multi-level evaluation process incurs considerable computational costs, especially as the method scales up or when applied to real-time systems.
3. **Limited Analysis of Other Domains and Real-world Applications**: Despite promising results on the PopQA dataset, its effectiveness beyond this domain and during long-form generation tasks remains uncertain due to resource constraints.
## Future Directions
Future research should prioritize the optimization of computational efficiency for ChunkRAG and explore its application across diverse datasets and real-world scenarios. Careful analysis and evaluation in different domains are crucial to fully validating its efficacy and scalability.
### References
A. Asai et al. 2024. Self-Rag: Self-Reflective Retrieval-Augmented Generation for Knowledge-Intensive Tasks.
S. Min et al. 2023. Self-reflective Mechanisms for Improved Retrieval-Augmented Generation.
A. Piktus et al. 2021. The Role of Chunking in Retrieval-Augmented Generation.
M. S. Rony et al. 2022. Fine-Grained Document Retrieval for Fact-Checking Tasks.
Y. Shi et al. 2023. Corrective Retrieval in Retrieval-Augmented Generation Systems.
T. Smith et al. 2023. Multi-Meta-RAG for Multi-Hop Queries Using LLM-Extracted Metadata.
S. Bhakthavathsalam et al. 2021. Multi-Hop Reasoning With Graph-Based Retrieval.
S. Your et al. 2024. CRAG: Corrective Retrieval-Augmented Generation.
A. Zhang and Others, 2023. Another Title of the Paper.
arXiv preprint arXiv:2302.56789.
A. Zhang et al. 2023. Hallucination in Large Language Models: A Comprehensive Survey.
F. Dhuliawala et al. 2024. Cove65b: Enhancing Factual Accuracy Through Iterative Engineering.
Y. Dubois et al., 2023. Instruction Tuning for Open-Domain Question Answering.
Z. Ji et al., 2023. Survey of Hallucination in Generative Models.
R. Johnson and T. Lee, 2023. Query Rewriting for Retrieval-Augmented Large Language Models.
P. Lewis et al., 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
C. Li et al., 2023. Factually Consistent Generation Using Self-Reflection.
S. Liu et al., 2023. Redundancy Removal in Retrieval-Augmented Generation Using Cosine Similarity.
J. Mallen et al., 2023. Enhancing Retrieval-Augmented Generation With Fact-Checking.
---
I made sure to correct any errors such as typographical issues, structural improvements like changing sentence cases and spacing, and making logical edits for a smoother flow of the text. Let me know if you need further adjustments or additions!
ChunkRag
C:\U生成工作流:
import re
def run_arxiv_paper_summary_workflow(topic):
#Step1 Get the arxiv search results
paper_details_response = client.run(agent=url_agent,
messages=[{"role":"user","content":f"Get me the details for {topic}"}])
text = paper_details_response.messages[-1]['content']
print(text)
# Step 2 Extract the URL from the search results
url_response = client.run(agent=extract_url,
messages=[{"role":"user","content":f"Get me the URL from the content{text}"}])
#
text = url_response.messages[-1]['content']
print(text)
# Regex pattern to find URLs
url_pattern = r'\((https?://[^\s)]+)\)'
# Find all unique URLs in the text
urls = set(re.findall(url_pattern, text))
# Print the unique URLs
print(f"urls :{urls}")
print(list(urls))
#extract content form the url
content = extract_content(list(urls)[0])
print(f"Content :{content}")
#Step 2 Generate Summary
summary_response = client.run(
agent=content_agent,
messages=[{"role": "user", "content": content }],
)
print(summary_response.messages[-1]["content"])
return summary_response.messages[-1]["content"]响应:
topic = "ChunkRag"
run_arxiv_paper_summary_workflow(topic)
#####################Response#######################################
ChunkRag
C:\Users\PLNAYAK\AppData\Local\Temp\ipykernel_17056\1349765600.py:20: DeprecationWarning: The 'Search.results' method is deprecated, use 'Client.results' instead
for result in search.results():
Number of papers extracted: 1
Here are the details for ChunkRAG:
- **Title**: ChunkRAG: Novel LLM-Chunk Filtering Method for RAG Systems
- **Date**: 2024-10-25
- **URL**: [Access Paper](http://arxiv.org/pdf/2410.19572v3)
- **Summary**:
Retrieval-Augmented Generation (RAG) systems using large language models (LLMs) often generate inaccurate responses due to the retrieval of irrelevant or loosely related information. Existing methods, which operate at the document level, fail to effectively filter out such content. We propose LLM-driven chunk filtering, ChunkRAG, a framework that enhances RAG systems by evaluating and filtering retrieved information at the chunk level. Our approach employs semantic chunking to divide documents into coherent sections and utilizes LLM-based relevance scoring to assess each chunk's alignment with the user’s query. By filtering out less pertinent chunks before the generation phase, we significantly reduce hallucinations and improve factual accuracy. Experiments show that our method outperforms existing RAG models, achieving higher accuracy on tasks requiring precise information retrieval. This advancement enhances the reliability of RAG systems, making them particularly beneficial for applications like fact-checking and multi-hop reasoning.
You can access the paper [here](http://arxiv.org/pdf/2410.19572v3).
The URL for the document "ChunkRAG: Novel LLM-Chunk Filtering Method for RAG Systems" is:
```http://arxiv.org/pdf/2410.19572v3```
You can access it [here](http://arxiv.org/pdf/2410.19572v3).
['http://arxiv.org/pdf/2410.19572v3']
Content :ChunkRAG: Novel LLM-Chunk Filtering Method for RAG Systems
Ishneet Sukhvinder Singh
Ritvik Aggarwal
Aslihan Akalin
Kevin Zhu
Ibrahim Allahverdiyev
Sean O’Brien
Muhammad Taha
Algoverse AI Research
asli@algoverse.us, kevin@algoverse.us, seobrien@ucsd.edu
4
2
0
2
t
c
O
0
3
]
L
C
.
s
c
[
3
v
2
7
5
9
1
.
0
1
4
2
:
v
i
X
r
a
Abstract
Retrieval-Augmented Generation (RAG) sys-
tems using large language models (LLMs) of-
ten generate inaccurate responses due to the
retrieval of irrelevant or loosely related infor-
mation. Existing methods, which operate at the
document level, fail to effectively filter out such
content. We propose LLM-driven chunk filter-
ing, ChunkRAG, a framework that enhances
RAG systems by evaluating and filtering re-
trieved information at the chunk level. Our
approach employs semantic chunking to divide
documents into coherent sections and utilizes
LLM-based relevance scoring to assess each
chunk’s alignment with the user’s query. By
filtering out less pertinent chunks before the
generation phase, we significantly reduce hallu-
cinations and improve factual accuracy. Exper-
iments show that our method outperforms ex-
isting RAG models, achieving higher accuracy
on tasks requiring precise information retrieval.
This advancement enhances the reliability of
RAG systems, making them particularly ben-
eficial for applications like fact-checking and
multi-hop reasoning.
1
Introduction
LARGE LANGUAGE MODELS (LLMs) have
made significant strides in the development
of retrieval-augmented generation (RAG) systems,
which combine retrieval mechanisms with power-
ful language models to produce responses based
on external knowledge. However, despite these
advancements, a persistent issue remains: the re-
trieval of irrelevant or weakly related information
during the document-fetching process. Current re-
trieval techniques, including reranking and query
rewriting, not only fail to filter out lots of irrele-
vant chunks of information in the retrieved docu-
ments but also lead to a series of problems with fac-
tual inaccuracies, irrelevance, and hallucinations in
the responses generated (Zhang and Others, 2023;
Mallen et al., 2023).
1
Figure 1: Flowchart
Traditionally, RAG systems retrieve large
amounts of the text of entire documents or lengthy
portions thereof, assuming that it is likely that these
lengthy fragments will contain the relevant informa-
tion. Such systems very rarely examine the sections
or paragraphs of the retrieved documents individu-
ally and, therefore, there is a strong likelihood that
irrelevant or only partially related information will
flow into the generation stage. Moreover, this is
further worsened by the fact that language models
generate fluent text without being able to verify
the information they use for generation. Relevant
or misleading chunks consequently distort the out-
come of such models severely, reducing the sys-
tem’s reliability, especially in critical applications
such as open-domain question answering and multi-
hop reasoning (Ji et al., 2023; Min et al., 2023).
Fig. 1: The figure shows that without chunk
filtering (top), irrelevant information like other
French cities is included in the response. The
LLM-driven chunk filtering (bottom), however, re-
moves unnecessary content, delivering the precise
answer, "The capital of France is Paris." A few
retrieval-related methods, Corrective RAG (CRAG)
and Self-RAG, have attempted to overcome these
hurdles by sophisticating retrieval. CRAG focuses
on retrieving "corrections" post-hoc to the errors
that occur in retrieval, whereas Self-RAG injects
self-reflection into the generation stage itself to
avoid inaccuracies. Both of these processes occur
at the document level and lack filtering sufficient
enough for individual retrieved chunks of text. This
document-level method enhances the broader rele-
vance of the retrieval but does nothing to prevent
irrelevant chunks from rolling over into the gener-
ated response (Shi et al., 2023). Lack of control
over the granularity of the content retrieved makes
RAG systems vulnerable to including undesirable
or misleading information in their output, thus ulti-
mately nullifying the performance.
The solution to this challenge lies in the novel ap-
proach: LLM-driven chunk filtering, ChunkRAG.
Our method operates on a finer level of granularity
than classical systems and, in fact, supports chunk-
level filtering of retrieved information. Rather than
judging entire documents to be relevant, our system
goes both for the user query and individual chunks
within retrieved documents. The large language
model evaluates semantic relevance of each chunk
with respect to the user’s query; this makes the sys-
tem capable of filtering out irrelevant or weakly
related chunks even before they get into the gener-
ation stage. This chunk-level filtering in turn aims
to enforce factual accuracy on the final answer by
drawing only the most relevant information on the
generation. This approach is particularly promising
for knowledge-intensive tasks, such as multi-hop
reasoning and fact-checking: precision is the ulti-
mate prize here. That is, in tasks where accuracy is
paramount, our approach stands best (Piktus et al.,
2021; Rony et al., 2022).
2 Literature Review
Redundancy in retrieved information can diminish
the effectiveness of Retrieval-Augmented Genera-
tion models by introducing repetitive or irrelevant
data, which hampers the model’s ability to gener-
ate coherent and unique responses. One prevalent
approach to mitigating redundancy involves the use
of cosine similarity to evaluate and remove dupli-
cate or overly similar content from the retrieved
documents.
Cosine Similarity in Redundancy Removal: Co-
sine similarity measures the cosine of the angle
between two non-zero vectors of an inner product
space, which quantifies the similarity between the
two vectors irrespective of their magnitude. In the
context of RAG, it is employed to compare textual
embeddings of retrieved chunks to identify and
eliminate redundant content, enhancing the diver-
sity of the information available for generation (Liu
et al., 2023).
Multi-Meta-RAG for Multi-Hop Queries: Ad-
dressing the challenges of multi-hop queries, Multi-
Meta-RAG introduces a database filtering mecha-
nism using metadata extracted by large language
models (LLMs). By incorporating LLM-extracted
metadata, this approach filters databases to retrieve
more relevant documents that contribute to answer-
ing complex queries requiring reasoning over multi-
ple pieces of information (Smith et al., 2023). This
method reduces redundancy by ensuring that only
pertinent documents are considered, thereby im-
proving the coherence of the generated responses.
Query Rewriting for Enhanced Retrieval: The
paper
titled "Query Rewriting for Retrieval-
Augmented Large Language Models" proposes a
"Rewrite-Retrieve-Read" framework to bridge the
gap between input text and the necessary retrieval
knowledge (Johnson and Lee, 2023). A trainable
query rewriter adapts queries using reinforcement
learning based on feedback from the LLM’s perfor-
mance. This approach enhances retrieval accuracy
by reformulating queries to better align with rele-
vant documents, thus minimizing the retrieval of
redundant or irrelevant information.
Self-RAG: Learning through Self-Reflection:
Self-RAG puts forth a framework that enhances
LLM quality and factuality through on-demand re-
trieval and self-reflection (Li et al., 2023). It trains
the model to adaptively retrieve passages, generate
text, and reflect on its own outputs using special
tokens called reflection tokens. This method allows
the model to critique and refine its responses, re-
ducing redundancy by discouraging the inclusion
of irrelevant or repetitive information.
We introduce a new model, ChunkRAG that em-
phasizes an innovative chunking strategy aimed at
further reducing redundancy and improving the ef-
fectiveness of RAG models. Our approach involves
segmenting documents into semantically coherent
and non-overlapping chunks that are more aligned
with the specific information needs of the query.
Despite advancements in Retrieval-Augmented
2
Generation systems like RAG, CRAG, Self-RAG,
and Self-CRAG, limitations persist in effectively
retrieving and utilizing relevant information due
to fixed size chunking, static relevance thresholds,
and single-pass relevance scoring. Our approach
addresses these issues through several key innova-
tions: implementing semantic chunking for top-
ically coherent chunks, employing LLM-based
query rewriting to refine user queries, introduc-
ing advanced LLM-based relevance scoring with
self-reflection and a critic LLM for more accurate
assessments, utilizing dynamic threshold determi-
nation to adaptively filter relevant information, and
incorporating initial filtering methods to improve
efficiency by reducing redundancy and prioritizing
chunks. These enhancements collectively surpass
traditional models by providing more precise re-
trieval and contextually appropriate answers, lead-
ing to significant improvements in performance as
demonstrated by standard evaluation metrics.
3 Methodology
The primary aim of this work is to reduce irrele-
vance and hallucinations in the responses generated
by Retrieval-Augmented Generation (RAG) sys-
tems through a novel, fine-grained filtering process
that evaluates the relevance of each chunk of re-
trieved information before it is used in the response
generation phase. Below, we describe the steps
involved in a detailed, precise, and reproducible
manner.
3.1 Step 1: Semantic Chunking
1. Input Preparation: Start with a docu-
ment D and break it down into sentences
using a sentence tokenizer (e.g., NLTK’s
sent_tokenize function).
2. Embedding Generation:
Use
embedding model
pre-trained
text-embedding-3-small)
vector representation for each sentence.
to create
a
(e.g.,
a
3. Chunk Creation: Calculate the similarity
between consecutive sentences using cosine
similarity. If similarity drops below a thresh-
old (θ = 0.7), mark a new chunk boundary.
Group sentences accordingly, ensuring each
chunk is under 500 characters.
3.2 Step 2: Vector Store Creation
1. Embedding the Chunks: Convert each
chunk into an embedding using the same
3
model as above.
2. Storing Embeddings: Store all chunk embed-
dings in a vector database for easy retrieval
during query matching.
3.3 Step 3: Retriever Initialization
1. Setup Retriever: Initialize the retriever to
compare incoming query embeddings with
stored chunk embeddings to find the most rel-
evant chunks.
3.4 Step 4: Query Rewriting
1. Query Enhancement: Rewrite the user’s
original query using a language model (e.g.,
GPT-4omini) to make it more suitable for re-
trieval.
3.5 Step 5: Initial Filtering
1. Duplicate Removal: Use TF-IDF and cosine
similarity to eliminate duplicate or overly sim-
ilar chunks (similarity > 0.9).
2. Sort by Relevance: Sort
the remaining
chunks based on similarity to the rewritten
query.
3.6 Step 6: Advanced Relevance Scoring
1. Initial Scoring: Assign a relevance score to
each chunk using an LLM.
2. Score Refinement: Use self-reflection and a
critic model to refine the initial scores, then
calculate an average to obtain the final score.
3.7 Step 7: Thresholding for Relevance
1. Set Dynamic Threshold: The LLM analyzes
the distribution of final scores and suggests an
optimal threshold for chunk relevance.
2. Filter Chunks: Retain only chunks with
scores above the threshold.
3.8 Step 8: Hybrid Retrieval and Re-Ranking
1. BM25 Retriever: In parallel, a BM25 re-
triever is implemented to capture keyword-
based retrieval. The BM25 retriever is com-
bined with the LLM-based retriever using an
ensemble approach with equal weights (0.5
each), ensuring both semantic and keyword-
based retrieval are balanced.
2. Re-ranking Chunks: Cohere’s reranking
model (rerank-englishv3.0) is applied to
rank the chunks by relevance to address the
“Lost in the Middle” problem, ensuring the
most relevant chunks are prioritized in the fi-
nal retrieval set.
3.9 Step 9: Answer Generation
While our primary experiments focused on PopQA,
ChunkRAG is designed for scalability, and future
evaluations could include additional datasets like
Biography (Min et al., 2023) for long-form genera-
tion, PubHealth (Zhang et al., 2023) for true/false
question answering, and Arc-Challenge (Bhaktha-
vatsalam et al., 2021) for multi-choice questions.
1. Compile Context: Collect the most relevant
4.3 Experimental Setup
chunks to use as context.
2. Generate Response: Use an LLM to generate
an answer based on the context, ensuring that
only the information from retrieved chunks is
used.
3.10 Step 10: Evaluation
1. Accuracy Calculation: Compare the gener-
ated answers against a set of correct answers
to evaluate performance:
Accuracy =
Number of Correct Answers
Total Number of Questions
(1)
4 Experiments
To evaluate the effectiveness of ChunkRAG in re-
ducing irrelevance and hallucinations in retrieval-
augmented generation, we conducted a series of
experiments using the PopQA dataset. This sec-
tion details the objectives, datasets, experimental
design, baseline comparisons, and results.
4.1 Objectives
The primary objective of our experiments was to
assess ChunkRAG’s performance in accurately re-
trieving relevant information and minimizing hal-
lucinations, especially on tasks requiring high pre-
cision in short-form question answering. We hy-
pothesized that the fine-grained, chunk-level filter-
ing would improve retrieval accuracy compared to
document-level approaches.
4.2 Tasks and Datasets
ChunkRAG was evaluated on the PopQA dataset
(Mallen et al., 2023), chosen for its alignment
with our model’s goal of precise, fact-based re-
trieval. PopQA is a benchmark dataset designed
for short-form question answering and contains
diverse questions requiring concise, accurate re-
sponses.
Its focus on factual precision makes
it an ideal testbed for assessing the capabilities
of retrieval-augmented generation (RAG) systems.
We conducted our experiments with computa-
tional constraints, implementing ChunkRAG on the
PopQA dataset to evaluate its retrieval accuracy and
response quality. The cosine similarity threshold
for semantic chunking was set to θ = 0.7, marking
chunk boundaries when similarity between con-
secutive sentences dropped below this level. Each
chunk was limited to a maximum of 500 characters,
ensuring focused and relevant segments.
In addition to the chunking process, we em-
ployed initial filtering via TF-IDF and cosine sim-
ilarity for duplicate removal, followed by an ad-
vanced relevance scoring system incorporating a
critic model. These settings were chosen based on
preliminary analyses to optimize for relevance and
accuracy.
4.4 Baselines
We compared ChunkRAG to several baselines, both
with and without retrieval mechanisms:
Baselines Without Retrieval: This group in-
cludes several large language models (LLMs) with-
out retrieval mechanisms, such as LLaMA2-7B and
Alpaca-7B (Dubois et al., 2023), selected for their
performance in various natural language processing
tasks. Additionally, CoVE65B (Dhuliawala et al.,
2024) was included to measure factual accuracy
improvements in non-retrieval LLMs.
Baselines With Retrieval: For
retrieval-
augmented methods, we evaluated Standard
RAG (Lewis et al., 2020), Self-RAG (Asai et al.,
2024), and CRAG (Your et al., 2024). CRAG
serves as a direct comparison due to its corrective
strategies in retrieval quality,
lacks
chunk-level filtering. The advanced models, such
as Ret-ChatGPT and RetLLaMA-chat, were also
included for proprietary comparisons.
though it
4.5 Evaluation Metrics
The primary evaluation metric was accuracy, de-
fined as the percentage of generated responses that
exactly matched the ground-truth answers. We
4
also assessed semantic accuracy, where responses
semantically equivalent to the ground truth, as eval-
uated by an LLM-based similarity checker, were
counted as correct. This approach ensured a com-
prehensive measure of both factual accuracy and
contextual relevance.
Accuracy =
Number of Correct Answers
Total Number of Questions
(2)
4.6 Results and Analysis
As shown in Table 1, ChunkRAG achieved an ac-
curacy of 64.9 on PopQA, surpassing all baselines
in the same category. Compared to CRAG, which
achieved an accuracy of 54.9, our model shows a
performance improvement of 10 percentage points.
This increase is significant, especially for multi-
step reasoning tasks, where errors can compound
across steps.
The enhanced performance is primarily due to
ChunkRAG’s chunk-level filtering, which reduces
the inclusion of irrelevant or weakly related in-
formation. By focusing on semantically relevant
chunks, the generation of factually accurate re-
sponses was substantially improved. Furthermore,
our self-reflective scoring mechanism reduced re-
trieval errors by providing a finer relevance assess-
ment at the chunk level.
Method
LLaMA2-13B
Ret-LLaMA2-13B
ChatGPT
Ret-ChatGPT
LLaMA2-7B
Alpaca-7B
Standard RAG
CRAG
Self-RAG
ChunkRAG (Ours)
PopQA Accuracy (%)
20.0
51.8
29.3
50.8
14.7
23.6
50.5
54.9
50.5
64.9
Table 1: Performance Comparison Across Methods on
PopQA Dataset
4.7 Observations and Insights
Our experiments demonstrated that chunk-level fil-
tering led to a notable improvement in response
accuracy and relevance. By dividing text into
semantically coherent chunks, ChunkRAG was
able to reduce irrelevant or tangential information,
thus enhancing factual accuracy. The LLM’s self-
reflective scoring system further contributed to er-
ror reduction by refining chunk relevance.
Future work will explore the scalability of
ChunkRAG on additional datasets, including Biog-
raphy, PubHealth, and Arc-Challenge, to validate
its versatility. Addressing computational efficiency
is also planned to enable broader applications of
ChunkRAG.
5 Analysis
In this section, we evaluate the performance of
ChunkRAG against existing retrieval-augmented
generation (RAG) methods. We present an analysis
based on empirical results obtained from standard
benchmarks.
Table 2: Performance Comparison Across Methods
(PopQA Accuracy Only)
Method
PopQA (Accuracy)
LLMs trained with proprietary data
LLaMA2-C_13B
Ret-LLaMA2-C_13B
ChatGPT
Ret-ChatGPT
20.0
51.8
29.3
50.8
Baselines without retrieval
14.7
23.6
14.7
14.3
-
Baselines with retrieval
LLaMA2_7B
Alpaca_7B
LLaMA2_13B
Alpaca_13B
CoVE_65B
LLaMA2_7B
Alpaca_7B
SAIL
LLaMA2_13B
Alpaca_13B
LLaMA2-hf_7B
RAG
CRAG
Self-RAG
Self-CRAG
ChunkRAG
38.2
46.7
-
45.7
46.1
50.5
54.9
50.5
49.0
64.9
5.1 Evaluation Metrics
We used accuracy as the primary evaluation metric,
calculated as the percentage of generated responses
that exactly match the ground-truth answers. Addi-
tionally, we considered semantic accuracy, where
responses that are semantically equivalent to the
ground truth (as evaluated by an LLM-based seman-
tic similarity checker) are also counted as correct.
Accuracy =
Correct Answers
Total Questions
(3)
5
5.2 Comparison and Impact
As depicted in Table 1, our method achieved an
accuracy of 64.9, substantially outperforming all
baselines in the same category. Notably, compared
to the closest baseline, CRAG (54.9 accuracy), our
method exhibits a performance gain of 10 percent-
age points.
While a 10 percentage point increase may seem
incremental, it translates into an exponential im-
provement in output effectiveness in practical ap-
plications. This is particularly evident when consid-
ering the error rates and their impact on the overall
user experience.
5.3 Multi-Step Processes
In applications requiring multi-hop reasoning or
sequential decision-making, errors can compound
exponentially. The probability of the system provid-
ing correct answers across multiple steps is given
by:
P (correct over n steps) = (accuracy)n
(4)
As the number of steps increases, the gap be-
tween the success probabilities widens exponen-
tially. For a 3-step process, our method’s success
rate is 66% higher than CRAG’s. This exponential
improvement is especially important in complex
tasks where each additional step compounds the
risk of error, namely relevant to OpenAI’s advanced
models such as o1 where the language model uti-
lizes multi-hop reasoning, relying on spending time
"thinking" before it answers, making it more effi-
cient in complex reasoning tasks, science and pro-
gramming.
5.4 Observations and Insights
The notable improvement attained with our tech-
nique is mainly due to chunk-level filtering and
fine-grained relevance assessment. We divided
the text into semantically meaningful chunks,
which reduced the generation of irrelevant or
In processing the
weakly related information.
chunk filtering’s contextually relevant data, the gen-
eration of factually accurate and coherent responses
was significantly enhanced.
Moreover,
the self-reflective LLM scoring
method, in which the model grades itself and then
changes accordingly, led to a significant decrease
in retrieval errors. Unlike regular retrieval methods
that do not have a filtering mechanism at the doc-
ument section level, our method can extract more
meaningful and relevant information that directly
affects the reliability of the generated responses.
5.5 Future Work
In our present studies, we have only tested PopQA
but the design of ChunkRAG is for scalability
purposes. In the upcoming assessments, we will
also introduce new datasets including Biography
for long-form generation, PubHealth for true/false
questions, and Arc-Challenge for multiple-choice
questions. The implementation of these trials will
thus reinforce the evidence of ChunkRAG’s versa-
tility and adaptability to different types of genera-
tion tasks, although this will be conditional on the
availability of computing resources.
6 Conclusion
In this paper, we introduced ChunkRAG, a novel
LLM-driven chunk filtering approach aimed at im-
proving the precision and factuality of retrieval-
augmented generation systems. In our experiments,
which were conducted on the PopQA dataset,
ChunkRAG has clearly demonstrated superiority
over existing baselines, and thus has achieved a
significant performance boost of 10 percentage
points, which was higher than the closest bench-
mark, CRAG. The chunk-level filtering technique
guaranteed that only the relevant and contextually
correct information was included during the re-
sponse generation, resulting in better reliability
and accuracy of generated answers. This method is
particularly useful for applications that require im-
mense amounts of facts, such as multi-hop reason-
ing and decision-making that involve many interde-
pendent parameters. We believe that ChunkRAG
is a big step towards solving the problems of ir-
relevant or hallucinated material in LLM-based
retrieval systems.
7 Limitations
ChunkRAG, in spite of its benefits, has a number
of drawbacks that need to be taken into account.
Firstly, the method relies heavily on the effective-
ness of chunk segmentation and the quality of the
embeddings used for chunk relevance assessment.
Mistakes in the primary division can create irrel-
evant data that will decrease the quality of the re-
sponse. Secondly, the costs from the multi-level
score—integrating both LLM and critic LLM evalu-
6
ations at the initial level—can be high, particularly
during the scaling of the method to larger datasets
or the deployment of it in real-time systems. Addi-
tionally, while ChunkRAG demonstrated positive
outcomes in the use of the PopQA dataset, the
verifiability of its use in other domains and the per-
formance when operating through long-form gen-
eration tasks has not been thoroughly analyzed due
to resource limitations. Future studies should con-
centrate on the optimization of the computational
efficiency of ChunkRAG and its evaluation over
diverse datasets and in real-world applications.
References
A. Asai et al. 2024. Self-rag: Self-reflective retrieval-
augmented generation for knowledge-intensive tasks.
In Proceedings of the Annual Meeting of the Associa-
tion for Computational Linguistics (ACL).
S. Min et al. 2023. Self-reflective mechanisms for im-
proved retrieval-augmented generation. In Proceed-
ings of the 61st Annual Meeting of the Association
for Computational Linguistics (ACL).
A. Piktus et al. 2021. The role of chunking in retrieval-
augmented generation. In Proceedings of the Con-
ference on Neural Information Processing Systems
(NeurIPS).
M. S. Rony et al. 2022. Fine-grained document retrieval
for fact-checking tasks. In Proceedings of the 2022
Conference on Empirical Methods in Natural Lan-
guage Processing (EMNLP).
Y. Shi et al. 2023. Corrective retrieval in retrieval-
augmented generation systems. In Proceedings of
the International Conference on Machine Learning
(ICML).
T. Smith et al. 2023. Multi-meta-rag for multi-hop
queries using llm-extracted metadata. In Proceedings
of the International Conference on Computational
Linguistics (COLING).
S. Bhakthavatsalam et al. 2021. Multi-hop reasoning
In Proceedings of the
with graph-based retrieval.
59th Annual Meeting of the Association for Compu-
tational Linguistics (ACL).
S. Your et al. 2024. Crag: Corrective retrieval-
In Proceedings of the An-
augmented generation.
nual Meeting of the Association for Computational
Linguistics (ACL).
A. Zhang and Others. 2023. Another title of the paper.
arXiv preprint arXiv:2302.56789.
A. Zhang et al. 2023. Hallucination in large language
models: A comprehensive survey. arXiv preprint
arXiv:2301.12345.
F. Dhuliawala et al. 2024. Cove65b: Enhancing fac-
tual accuracy through iterative engineering. arXiv
preprint arXiv:2401.12345.
Y. Dubois et al. 2023.
Instruction tuning for open-
domain question answering. In Advances in Neural
Information Processing Systems (NeurIPS).
Z. Ji et al. 2023. Survey of hallucination in generative
models. arXiv preprint arXiv:2302.02451.
R. Johnson and T. Lee. 2023. Query rewriting for
retrieval-augmented large language models. In Pro-
ceedings of the International Conference on Machine
Learning (ICML).
P. Lewis et al. 2020. Retrieval-augmented generation
for knowledge-intensive nlp tasks. In Advances in
Neural Information Processing Systems, volume 33,
pages 9459–9474.
C. Li et al. 2023. Factually consistent generation using
self-reflection. In Proceedings of the 61st Annual
Meeting of the Association for Computational Lin-
guistics (ACL).
S. Liu et al. 2023. Redundancy removal in retrieval-
augmented generation using cosine similarity.
In
Proceedings of the Conference on Empirical Methods
in Natural Language Processing (EMNLP).
J. Mallen et al. 2023. Enhancing retrieval-augmented
In Proceedings of
generation with fact-checking.
the Conference on Empirical Methods in Natural
Language Processing (EMNLP).
7
Here is a revised version of the manuscript to improve readability and clarity:
---
### Improving Relevance Assessment Using ChunkRAG: A Comprehensive Review and Evaluation
#### Abstract:
ChunkRAG, a method leveraging chunking for efficient retrieval augmentation in language models, has shown potential improvements over traditional approaches but faces challenges in evaluation and scalability. In this paper, we analyze various aspects of ChunkRAG's effectiveness, including its primary division accuracy and the integration of Level-2 scores. Additionally, we discuss its limitations, particularly regarding resource consumption during scaling and real-time deployment. Future research should focus on enhancing computational efficiency and evaluating the model's performance over diverse datasets in actual applications.
---
### 1. Introduction
Re retrieval-augmented generation (RAG) is a powerful approach for generating responses that integrate information from multiple sources. Chunking, which involves dividing documents into coherent chunks, has been used in this context to enhance relevance assessment. This paper examines various aspects of ChunkRAG's effectiveness and highlights its advantages while identifying areas for improvement.
---
### 2. Understanding ChunkRAG
ChunkRAG addresses several challenges associated with traditional retrieval augmentation techniques. The primary evaluation focuses on ensuring that the data chunks are accurately divided, which is crucial for maintaining relevance in responses. Additionally, integrating Level-2 scores (combining both level-1 LLM and critic LLM evaluations) provides a more comprehensive assessment of generated content.
#### 2.1 Evaluating Primary Division
The accuracy of primary divisions impacts how relevant the data used for assessment will be. Mismatches can result in irrelevant information that significantly reduces the quality of responses generated by ChunkRAG.
#### 2.2 Integration of Level-2 Scores
The use of Level-2 scores—where both level-1 and critic LLM evaluations are integrated at the initial stage—can introduce high costs, especially when scaling up to larger datasets or deploying in real-time systems. These costs can be substantial.
---
### 3. Challenges and Limitations
#### 3.1 Primary Division Accuracy
Errors in primary divisions often lead to irrelevant data, which negatively impacts the quality of generated responses. This issue requires more attention.
#### 3.2 Level-2 Scores Integration
The high processing costs associated with integrating both level-1 and critic LLM evaluations add further complexity to the method's practical applications. Future research should address scalability concerns.
---
### 4. Applications and Validation
While ChunkRAG demonstrated positive outcomes using datasets like PopQA, its viability in other domains needs more thorough examination. Additionally, evaluating its performance in long-form generation tasks requires analysis of longer data sets.
---
### 5. Conclusion and Recommendations
ChunkRAG offers promising improvements but still presents substantial challenges, particularly with cost efficiency and application scalability. Future work should concentrate on addressing these issues through optimization techniques to enhance computational efficiency and robustness across diverse datasets and real-world scenarios.
#### References:
(Include references as per your formatting style.)
---
This version of the manuscript is more structured, concise, and easy to follow. Each section aims to provide a clear understanding of the method's strengths, weaknesses, and areas needing further research.
最终的响应:
Here is a revised version of the manuscript to improve readability and clarity:\n\n---\n\n### Improving Relevance Assessment Using ChunkRAG: A Comprehensive Review and Evaluation\n\n#### Abstract:\nChunkRAG, a method leveraging chunking for efficient retrieval augmentation in language models, has shown potential improvements over traditional approaches but faces challenges in evaluation and scalability. In this paper, we analyze various aspects of ChunkRAG's effectiveness, including its primary division accuracy and the integration of Level-2 scores. Additionally, we discuss its limitations, particularly regarding resource consumption during scaling and real-time deployment. Future research should focus on enhancing computational efficiency and evaluating the model's performance over diverse datasets in actual applications.\n\n---\n\n### 1. Introduction\nRe retrieval-augmented generation (RAG) is a powerful approach for generating responses that integrate information from multiple sources. Chunking, which involves dividing documents into coherent chunks, has been used in this context to enhance relevance assessment. This paper examines various aspects of ChunkRAG's effectiveness and highlights its advantages while identifying areas for improvement.\n\n---\n\n### 2. Understanding ChunkRAG\nChunkRAG addresses several challenges associated with traditional retrieval augmentation techniques. The primary evaluation focuses on ensuring that the data chunks are accurately divided, which is crucial for maintaining relevance in responses. Additionally, integrating Level-2 scores (combining both level-1 LLM and critic LLM evaluations) provides a more comprehensive assessment of generated content.\n\n#### 2.1 Evaluating Primary Division\nThe accuracy of primary divisions impacts how relevant the data used for assessment will be. Mismatches can result in irrelevant information that significantly reduces the quality of responses generated by ChunkRAG. \n\n#### 2.2 Integration of Level-2 Scores \nThe use of Level-2 scores—where both level-1 and critic LLM evaluations are integrated at the initial stage—can introduce high costs, especially when scaling up to larger datasets or deploying in real-time systems. These costs can be substantial.\n\n---\n\n### 3. Challenges and Limitations\n\n#### 3.1 Primary Division Accuracy\nErrors in primary divisions often lead to irrelevant data, which negatively impacts the quality of generated responses. This issue requires more attention.\n\n#### 3.2 Level-2 Scores Integration\nThe high processing costs associated with integrating both level-1 and critic LLM evaluations add further complexity to the method's practical applications. Future research should address scalability concerns.\n\n---\n\n### 4. Applications and Validation\nWhile ChunkRAG demonstrated positive outcomes using datasets like PopQA, its viability in other domains needs more thorough examination. Additionally, evaluating its performance in long-form generation tasks requires analysis of longer data sets.\n\n---\n\n### 5. Conclusion and Recommendations\nChunkRAG offers promising improvements but still presents substantial challenges, particularly with cost efficiency and application scalability. Future work should concentrate on addressing these issues through optimization techniques to enhance computational efficiency and robustness across diverse datasets and real-world scenarios.\n\n#### References:\n(Include references as per your formatting style.)\n\n---\n\nThis version of the manuscript is more structured, concise, and easy to follow. Each section aims to provide a clear understanding of the method's strengths, weaknesses, and areas needing further research. \n\n"5、结束语
OpenAI Swarm 不仅仅是构建多智能体系统的工具;它代表了我们利用人工智能解决复杂问题的重要一步。它的轻量级架构、对协作的关注和易用性使其成为希望利用多个智能体协同工作的开发人员的一个有吸引力的选择。
随着组织越来越多地寻求通过自动化提高效率和生产力的解决方案,OpenAI Swarm 有望在开发能够自主运行但仍受人工监督指导的智能系统方面处于领先地位。在 OpenAI Swarm 的带领下,人工智能编排的未来一片光明,为各个领域的创新应用铺平了道路。
原文链接:Build an Arxiv paper content retriever and Summarizer Agent Using Completely local OpenAI Swarm
汇智网翻译整理,转载请标明出处


