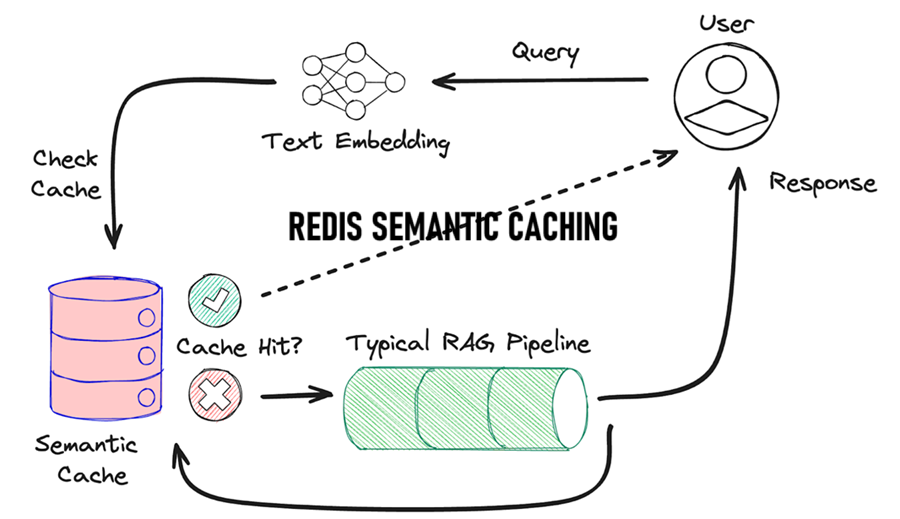
APPLICATION 基于Redis的LLM语义缓存 LLM非常强大,但它们可能会非常缓慢。如果你曾经等待超过10秒来回答一个你几乎之前问过的问题,你就知道这种挫败感了。这就是语义缓存发挥作用的地方。
LIBRARY 4个主流代理开发框架的对比 在这篇文章中,我们将重点关注四个值得注意的AI代理框架:CrewAI、AutoGen、LangChain和Pydantic AI。这些平台对“代理”的概念有不同的处理方式。
APPLICATION 集成Llama模型与MCP服务器 在这篇博客文章中,我们将学习如何使用任何开源LLM、OpenAI或Google Gemini的MCP服务器。我们将构建一个简单的CLI代理,该代理可以控制和与SQLite数据库交互。
APPLICATION 大模型驱动的语言学习导师 在这篇文章中,我将带你了解我是如何从概念到实现构建了一个改变我的波兰语学习体验的AI驱动的应用程序。查看我的Github仓库,并根据你正在学习的语言自定义应用程序。
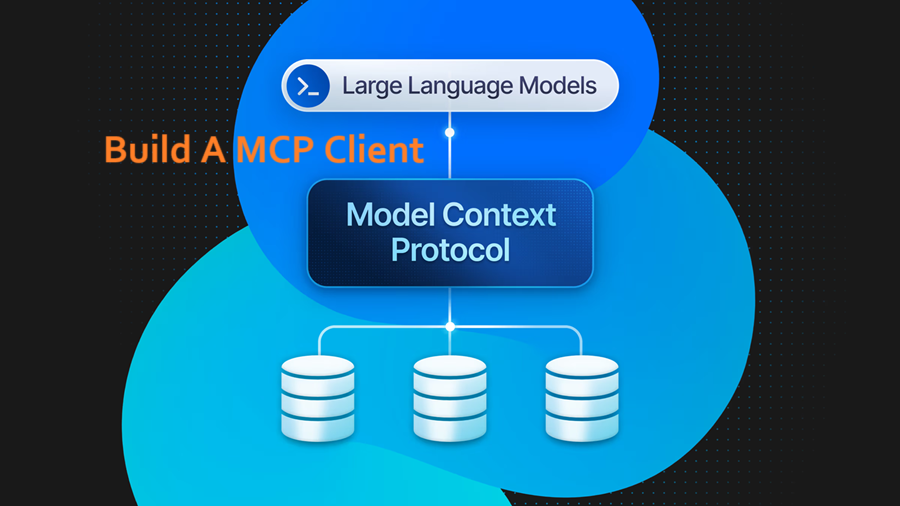
APPLICATION 开发一个MCP协议客户端 MCP并不局限于Claude桌面,它可以用任何支持它的其他LLM客户端使用。考虑到这一点,我们决定构建一个MCP CLI客户端来展示这一点。这个MCP客户端可以更快速地测试MCP服务器。
APPLICATION 从零构建医学多智能体AI 本文介绍使用Streamlit作为前端,并利用Ollama平台上的Llama-3.2:3b模型,实现用于总结医学文本、撰写研究文章以及屏蔽受保护健康信息(PHI)的多智能体系统。
PROMPT ENGINEERING 打造无敌AI代理的提示工程 几乎所有真正优秀的代理(比如 GPT Pilot、GPT Engineer、Devin,甚至是自我操作计算机)都使用了非常相似的提示技术来实现他们所做的一切。