图像数据集自动标注指南
本文介绍如何使用 Grounding DINO、SAM 和 AutoDistill 等模型/工具自动生成图像数据集的标注数据。

在这个激动人心的冒险中,我们将深入研究用于物体检测和图像分割的小型但强大的模型的世界。我们的目标是什么?利用大型模型的力量来创建高效、高质量的数据集,这些数据集可以训练更快、更小的模型,而不会影响性能。让我们开始吧!
本文适用于那些准备使用 Grounding DINO、SAM 和 AutoDistill 等最先进的模型/工具构建自己的数据集的人。如果你曾经因模型速度慢或手动标注的麻烦而感到沮丧,请不要害怕!我们将自动生成标注数据的过程,并使用 Roboflow 对其进行改进以确保质量。
1、数据集创建简介
创建高质量的数据集是任何成功的机器学习项目的基础。在本节中,我们将探讨如何利用 Grounding DINO 和 SAM 等大型模型自动标记图像。我们还将使用 Roboflow 等工具来优化这些标签,从而实现流畅高效的工作流程。
在这次冒险中,我们将重点关注以下基本步骤:
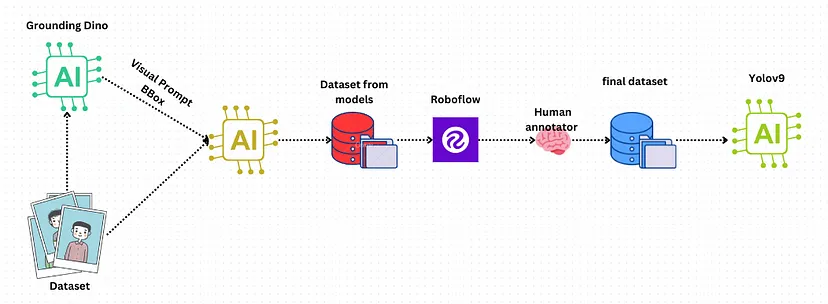
- Grounding DINO 用于基于文本提示的自动检测
- SAM模型用于精确的图像分割
- AutoDistill 用于简化数据集创建
- Roboflow 用于标签改进和增强
Grounding
Grounding将 AI 知识与现实世界的示例联系起来,提高准确性并减少错误,尤其是在复杂情况下。 在计算机视觉中,它将文本描述链接到特定的图像元素,帮助机器使用语言和图像来解释视觉效果。视觉基础 (VG) 旨在根据自然语言查询在图像中找到最相关的对象或区域
DINO
DINO(无标签自蒸馏)是 Facebook/metaAI 用于计算机视觉的一种自监督学习方法。 它通过比较同一幅图像的不同版本(没有人工标记的数据)来自学,使用师生方法来识别模式。
Grounding-DINO
Grounding DINO 扩展了 DINO 的语言功能,使其能够根据文本描述检测和定位对象。它在开放集对象检测和基于语言的查询等任务中表现出色。
SAM
SAM 由 Meta AI 开发,只需单击或几个点即可分割图像中的任何对象。它在从照片编辑到科学分析的应用中表现出色。根据他们的 GitHub repo,他们尚未实现文本作为输入
主要特点:
- 对看不见的物体进行零样本分割
- 可以用点、框或文本提示
- 实时生成掩码
- 处理物体遮挡和重叠
2、测试教师模型
在深入研究标注之前,我们将首先测试我们的教师模型,即 Grounding DINO 和 SAM 的组合。这些模型将充当我们的“老师”,根据我们提供的提示自动标记图像。
首先安装必要的软件包:
!pip3 install autodistill-grounded-sam roboflow autodistill-grounding-dino
!pip install -U ultralytics接下来,使用本体定义基础教师模型,将对象名称(如“自行车”、“人”等)映射到数据集中的类。例如:
- 定义一个本体,将类名映射到我们的 GroundingDINO 提示
- 本体词典的格式为
{caption: class}。标题应该是对象的描述,但在我的例子中,只需要一个词就足够了 - 其中标题是发送给基础模型的提示,而类是将在生成的标注中为该标题保存的标签
- 框和文本阈值,你可以通过在随机示例中进行测试来确定它们的值,就像我做的那样
from autodistill_grounded_sam import GroundedSAM
from autodistill.detection import CaptionOntology
from autodistill.utils import plot
import cv2
base_model = GroundedSAM(
box_threshold=0.4,
text_threshold=0.4,
ontology=CaptionOntology(
{
"Bike": "Bike",
"person":"Person",
"helmet":"Helmet"
}
)
)现在,在随机图像上测试教师模型,以确保它正确检测对象。此步骤可让你在扩大规模之前微调阈值和提示:
import supervision as sv
import matplotlib.pyplot as plt
from collections import Counter
path = "/kaggle/input/sports-classification/train/bmx/001.jpg"
def plot_annotated_image(path):
image = cv2.imread(path)
predictions = base_model.predict(path)
annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator(text_position=sv.Position.CENTER_LEFT)
mask_annotator = sv.MaskAnnotator()
annotated_image = annotator.annotate(scene=image.copy(), detections=predictions)
annotated_image = label_annotator.annotate(annotated_image, detections=predictions)
annotated_image = mask_annotator.annotate(annotated_image, detections=predictions)
# Count the occurrences of each class
class_counts = Counter(predictions.class_id)
class_names = {0: 'bikes', 1: 'persons', 2: 'helmets'}
# Create the title string
title = ', '.join(f"{count} {class_names[class_id]}" for class_id, count in class_counts.items())
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title(title)
sv.plot_image(annotated_image, size=(4, 4))
plot_annotated_image(path)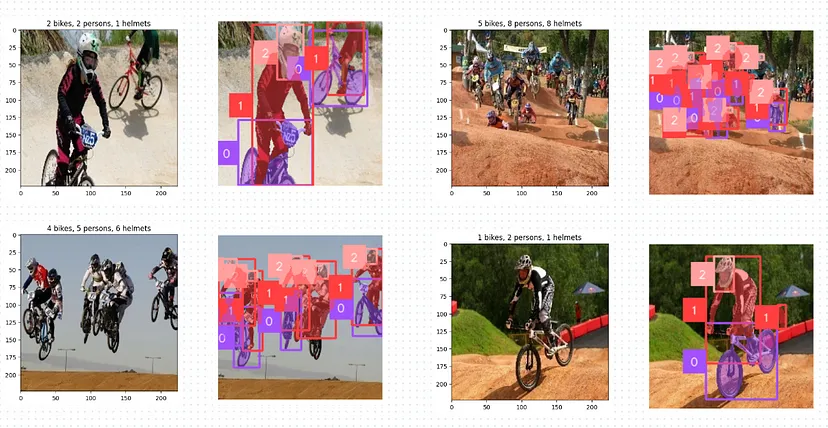
3、自动标注数据集
一旦你对老师感到满意模型的性能,是时候自动标注的数据集了。我们将创建一个新文件夹来存储我们标注的图像:
!mkdir datasets # make new folder for the dataset
base_model.label(
input_folder="/kaggle/input/sports-classification/train/bmx",# image folder
output_folder="/kaggle/working/datasets"
)
4、使用 Roboflow 细化标签
虽然自动标签是一个很好的开始,但它们可能需要一些人工细化。进入 Roboflow,这是一个强大的工具,可让你轻松清理标注并扩充数据集。
创建一个 Roboflow 帐户并设置一个工作区。然后将刚刚标记的数据集上传到 Roboflow。
然后,获取项目 ID 和空间密钥:
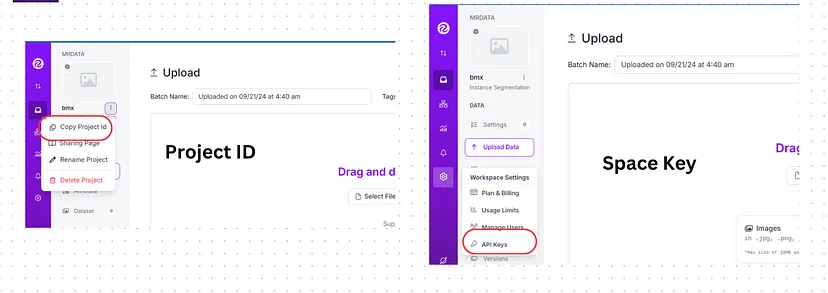
import roboflow
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_value_0 = user_secrets.get_secret("robo_flow_key")
rf = roboflow.Roboflow(api_key=secret_value_0)#space APi
# get a workspace
workspace = rf.workspace("ahmed-haytham")# name of work space
# Upload data set to a new/existing project
workspace.upload_dataset(
"/kaggle/working/datasets", # This is your dataset path
"bmx-waxnw",#project id # This will either create or get a dataset with the given ID
num_workers=10,
num_retries=0
)Roboflow 允许你编辑标签、调整边界框或蒙版,以及应用旋转、翻转和噪声等增强功能。你还可以直接在平台上将数据集拆分为训练集、验证集和测试集。
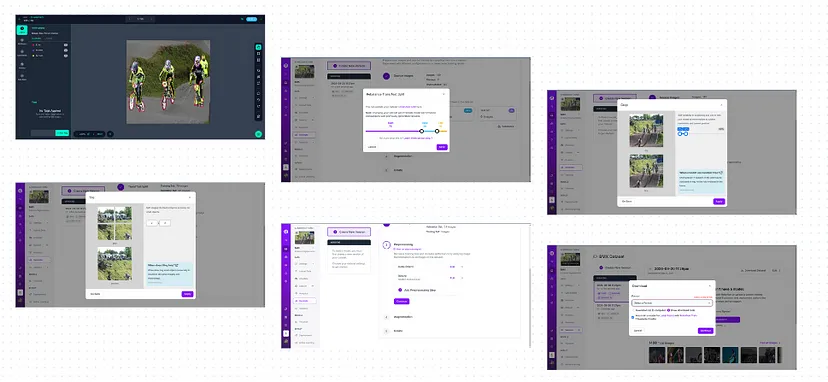
5、下载最终数据集
完善标签后,以训练所需的格式下载数据集。
from roboflow import Roboflow
rf = Roboflow(api_key=secret_value_0) # i canhged this to not make my key public
project = rf.workspace("ahmed-haytham").project("bmx-waxnw")
version = project.version(2)
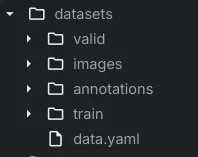
dataset = version.download("yolov9") # roboflow will write it for you如有必要,请更新数据集配置文件中的路径:
import yaml
with open('path/to/your/data.yaml') as f:
data = yaml.safe_load(f)
data['train'] = '/path/to/your/train/images'
data['val'] = '/path/to/your/val/images'
with open('path/to/your/data.yaml', 'w') as f:
yaml.dump(data, f)6、结束语
就是这样!
通过使用 Grounding DINO、SAM 和 AutoDistill 等模型/工具,你可以更轻松地创建数据集。现在,你有了一个强大且标记良好的数据集,可供你训练模型!
原文链接:Supercharging Small Models with Grounding DINO, SAM, and AutoDistill for Dataset Creation
汇智网翻译整理,转载请标明出处
