Axolotl大模型微调工具
Axolotl 是一种旨在简化各种 AI 模型微调的工具,支持多种配置和架构。

Axolotl 是一种旨在简化各种 AI 模型微调的工具,支持多种配置和架构。
特点:
- 训练各种 Huggingface 模型,如 llama、pythia、falcon、mpt
- 支持 fullfinetune、lora、qlora、relora 和 gptq
- 使用简单的 yaml 文件或 CLI 覆盖自定义配置
- 加载不同的数据集格式、使用自定义格式或自带标记化数据集
与 xformer、flash 注意力、rope scaling 和 multipacking 集成
通过 FSDP 或 Deepspeed 与单个 GPU 或多个 GPU 配合使用 - 轻松在本地或云端使用 Docker 运行
- 将结果和可选检查点记录到 wandb
- 还有更多!
1、什么是微调?
预训练模型大多只获取一般语言知识,缺乏关于任务或领域的特定知识。为了弥补这一差距,后续的微调步骤遵循预训练模型。
微调使我们能够专注于预训练模型的功能,并优化其在下游特定任务上的性能。
微调意味着采用预训练模型并使用新数据在新任务上对其进行更多训练。通常,这意味着训练整个预训练模型,包括其所有部分和设置。但这可能需要大量的计算机能力和时间,尤其是对于大型模型。
另一方面,参数高效微调是一种通过仅关注预训练模型的一些设置来进行微调的方法。它找出哪些参数对新任务最重要,并且只在训练期间更改这些参数。这使得 PEFT 更快,因为它不必处理模型的所有参数。
微调技术栈
- Runpod:RunPod 是一个云计算平台,主要为提供 GPU 实例、无服务器 GPU 和 AI 端点的 AI 和机器学习应用程序而设计。我们使用了 1 个 NVIDIA 80GB GPU
- Axolotl:旨在简化各种 AI 模型微调的工具
- 数据集:teknium/GPT4-LLM-Cleaned
- LLM:openlm-research/open_llama_3b_v2 模型
3、微调实施
安装所需的依赖项:
!git clone https://github.com/OpenAccess-AI-Collective/axolotl.git将目录更改为 axolotl 文件夹:
%cd axolotl
####### RESPONSE ###############
/workspace/axolotl
/usr/local/lib/python3.10/dist-packages/IPython/core/magics/osm.py:417: UserWarning: using dhist requires you to install the `pickleshare` library.
self.shell.db['dhist'] = compress_dhist(dhist)[-100:]!pip install packaging
!pip install -e .'[flash-attn,deepspedd]'安装依赖项后,检查示例文件夹。有几种 LLM 模型,它们各自具有 lora cong=figuration 文件。这里我们使用 openllama 3b 作为基础 LLM。我们将在 ./axolot/examples/openllama-3b/lora.yml 查看它的配置文件。 lora.yaml 文件包含微调基础模型所需的配置。
什么是 LoRA?
- 它是一种旨在加快 LLM 训练过程的训练方法。
- 它通过引入秩分解权重矩阵对来帮助减少内存消耗。它将 LLM 的权重矩阵分解为低秩矩阵。这减少了需要训练的参数数量,同时仍保持原始模型的性能。
- 这些权重矩阵被添加到已经存在的权重矩阵(预训练)中
与 LoRA 相关的重要概念
- 预训练权重的保存:LoRA 保持冻结层先前训练的权重。这有助于防止灾难性遗忘现象。Lora 不仅保留了模型的现有知识,而且可以很好地适应新数据
- 训练权重的可移植性:LoRA 中使用的秩分解矩阵的参数明显较少。这允许在其他环境中使用和传输训练过的 lora 权重。
- 与注意层集成:Lora 权重矩阵基本上被合并到原始模型的注意层中。这允许控制模型适应新数据的上下文。
- 内存效率高,因为它将微调过程的计算量减少了 3 倍
配置作为 lora.yaml 文件的一部分。我们可以通过在 lora.yaml 文件中针对 base_model 和 datasets 参数指定值来设置基础模型和 tanning 数据集:
base_model: openlm-research/open_llama_3b_v2
model_type: LlamaForCausalLM
tokenizer_type: LlamaTokenizer
load_in_8bit: true
load_in_4bit: false
strict: false
push_dataset_to_hub:
datasets:
- path: teknium/GPT4-LLM-Cleaned
type: alpaca
dataset_prepared_path:
val_set_size: 0.02
adapter: lora
lora_model_dir:
sequence_len: 1024
sample_packing: true
lora_r: 8
lora_alpha: 16
lora_dropout: 0.0
lora_target_modules:
- gate_proj
- down_proj
- up_proj
- q_proj
- v_proj
- k_proj
- o_proj
lora_fan_in_fan_out:
wandb_project:
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
output_dir: ./lora-out
gradient_accumulation_steps: 1
micro_batch_size: 2
num_epochs: 4
optimizer: adamw_bnb_8bit
torchdistx_path:
lr_scheduler: cosine
learning_rate: 0.0002
train_on_inputs: false
group_by_length: false
bf16: false
fp16: true
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
gptq_groupsize:
gptq_model_v1:
warmup_steps: 20
evals_per_epoch: 4
saves_per_epoch: 1
debug:
deepspeed:
weight_decay: 0.1
fsdp:
fsdp_config:
special_tokens:
bos_token: "<s>"
eos_token: "</s>"
unk_token: "<unk>"Lora 超参数:
lora_r :它确定应用于权重矩阵的秩分解矩阵的数量,以减少内存消耗和计算要求。根据 LoRA 论文,默认或最小秩值为 8。
- 更高的秩会带来更好的结果,但需要更高的计算量。
- 随着训练数据的复杂性增加,它需要更高的秩。
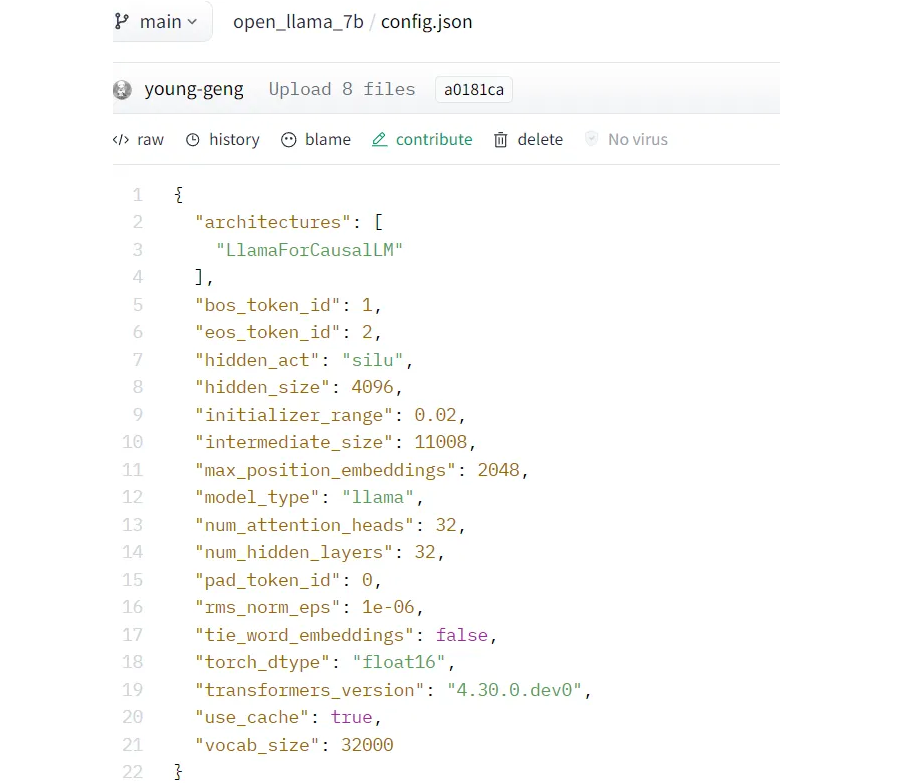
- 为了匹配完整的微调,权重矩阵的秩应该与基础模型的隐藏层数相匹配。模型隐藏大小可以从 config.json 中找到(“num_hidden_layers”:32)
lora_alpha :LoRA 的缩放因子决定了模型在训练过程中调整矩阵更新贡献的程度。
- 较低的 alpha 值赋予原始数据更多权重,并且它在更大程度上保持了模型的现有知识,即它更倾向于模型的原始知识
lora_target_modules:它确定要训练哪些特定权重和矩阵。最基本的是 q_proj(查询向量)和 v_proj(值向量)
- Q 投影矩阵应用于 transformers 块的注意机制中的查询向量。它将隐藏状态转移到所需的维度,以实现有效的查询呈现
- V 投影矩阵将隐藏状态转换为所需的维度,以实现有效的值表示。
4、Lora 微调
! accelerate launch -m axolotl.cli.train examples/openllama-3b/lora.ymlThe following values were not passed to `accelerate launch` and had defaults used instead:
`--num_processes` was set to a value of `1`
`--num_machines` was set to a value of `1`
`--mixed_precision` was set to a value of `'no'`
`--dynamo_backend` was set to a value of `'no'`
To avoid this warning pass in values for each of the problematic parameters or run `accelerate config`.
/usr/local/lib/python3.10/dist-packages/transformers/deepspeed.py:23: FutureWarning: transformers.deepspeed module is deprecated and will be removed in a future version. Please import deepspeed modules directly from transformers.integrations
warnings.warn(
[2024-01-01 08:31:18,370] [INFO] [datasets.<module>:58] [PID:2201] PyTorch version 2.0.1+cu118 available.
[2024-01-01 08:31:19,417] [INFO] [axolotl.validate_config:156] [PID:2201] [RANK:0] bf16 support detected, but not enabled for this configuration.
[2024-01-01 08:31:19,417] [WARNING] [axolotl.validate_config:176] [PID:2201] [RANK:0] `pad_to_sequence_len: true` is recommended when using sample_packing
config.json: 100%|█████████████████████████████| 506/506 [00:00<00:00, 2.10MB/s]
[2024-01-01 08:31:19,656] [INFO] [axolotl.normalize_config:150] [PID:2201] [RANK:0] GPU memory usage baseline: 0.000GB (+0.811GB misc)
dP dP dP
88 88 88
.d8888b. dP. .dP .d8888b. 88 .d8888b. d8888P 88
88' `88 `8bd8' 88' `88 88 88' `88 88 88
88. .88 .d88b. 88. .88 88 88. .88 88 88
`88888P8 dP' `dP `88888P' dP `88888P' dP dP
[2024-01-01 08:31:19,660] [WARNING] [axolotl.scripts.check_user_token:342] [PID:2201] [RANK:0] Error verifying HuggingFace token. Remember to log in using `huggingface-cli login` and get your access token from https://huggingface.co/settings/tokens if you want to use gated models or datasets.
tokenizer_config.json: 100%|███████████████████| 593/593 [00:00<00:00, 2.69MB/s]
tokenizer.model: 100%|███████████████████████| 512k/512k [00:00<00:00, 36.7MB/s]
special_tokens_map.json: 100%|█████████████████| 330/330 [00:00<00:00, 1.01MB/s]
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
[2024-01-01 08:31:20,716] [DEBUG] [axolotl.load_tokenizer:185] [PID:2201] [RANK:0] EOS: 2 / </s>
[2024-01-01 08:31:20,716] [DEBUG] [axolotl.load_tokenizer:186] [PID:2201] [RANK:0] BOS: 1 / <s>
[2024-01-01 08:31:20,717] [DEBUG] [axolotl.load_tokenizer:187] [PID:2201] [RANK:0] PAD: 2 / </s>
[2024-01-01 08:31:20,717] [DEBUG] [axolotl.load_tokenizer:188] [PID:2201] [RANK:0] UNK: 0 / <unk>
[2024-01-01 08:31:20,717] [INFO] [axolotl.load_tokenizer:193] [PID:2201] [RANK:0] No Chat template selected. Consider adding a chat template for easier inference.
[2024-01-01 08:31:20,717] [INFO] [axolotl.load_tokenized_prepared_datasets:147] [PID:2201] [RANK:0] Unable to find prepared dataset in last_run_prepared/f9e5091071bf5ab6f7287bd5565a5f24
[2024-01-01 08:31:20,717] [INFO] [axolotl.load_tokenized_prepared_datasets:148] [PID:2201] [RANK:0] Loading raw datasets...
[2024-01-01 08:31:20,717] [INFO] [axolotl.load_tokenized_prepared_datasets:153] [PID:2201] [RANK:0] No seed provided, using default seed of 42
Downloading readme: 100%|███████████████████████| 501/501 [00:00<00:00, 343kB/s]
/usr/local/lib/python3.10/dist-packages/huggingface_hub/repocard.py:105: UserWarning: Repo card metadata block was not found. Setting CardData to empty.
warnings.warn("Repo card metadata block was not found. Setting CardData to empty.")
Downloading data: 100%|████████████████████| 36.0M/36.0M [00:01<00:00, 27.0MB/s]
Downloading data: 100%|████████████████████| 4.91M/4.91M [00:00<00:00, 9.16MB/s]
Generating train split: 54568 examples [00:00, 187030.30 examples/s]
Map (num_proc=64): 13%|█▍ | 7057/54568 [00:11<03:55, 202.13 examples/s][2024-01-01 08:31:39,365] [WARNING] [axolotl._tokenize:66] [PID:2275] [RANK:0] Empty text requested for tokenization.
Map (num_proc=64): 100%|█████████| 54568/54568 [00:17<00:00, 3180.11 examples/s]
[2024-01-01 08:31:45,017] [INFO] [axolotl.load_tokenized_prepared_datasets:362] [PID:2201] [RANK:0] merging datasets
[2024-01-01 08:31:45,023] [INFO] [axolotl.load_tokenized_prepared_datasets:369] [PID:2201] [RANK:0] Saving merged prepared dataset to disk... last_run_prepared/f9e5091071bf5ab6f7287bd5565a5f24
Saving the dataset (1/1 shards): 100%|█| 54568/54568 [00:00<00:00, 524866.32 exa
Filter (num_proc=64): 100%|█████| 53476/53476 [00:02<00:00, 20761.86 examples/s]
Filter (num_proc=64): 100%|████████| 1092/1092 [00:00<00:00, 2586.61 examples/s]
Map (num_proc=64): 100%|████████| 53476/53476 [00:02<00:00, 19739.44 examples/s]
Map (num_proc=64): 100%|███████████| 1092/1092 [00:00<00:00, 2167.35 examples/s]
[2024-01-01 08:31:54,825] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] total_num_tokens: 188373
[2024-01-01 08:31:54,833] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] `total_supervised_tokens: 38104`
[2024-01-01 08:32:01,085] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 1.0 total_num_tokens per device: 188373
[2024-01-01 08:32:01,085] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] data_loader_len: 181
[2024-01-01 08:32:01,085] [INFO] [axolotl.log:60] [PID:2201] [RANK:0] sample_packing_eff_est across ranks: [0.9017549402573529]
[2024-01-01 08:32:01,086] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] sample_packing_eff_est: None
[2024-01-01 08:32:01,086] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] total_num_steps: 181
[2024-01-01 08:32:01,132] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] total_num_tokens: 10733491
[2024-01-01 08:32:01,495] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] `total_supervised_tokens: 6735490`
[2024-01-01 08:32:01,663] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 1.0 total_num_tokens per device: 10733491
[2024-01-01 08:32:01,664] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] data_loader_len: 10376
[2024-01-01 08:32:01,664] [INFO] [axolotl.log:60] [PID:2201] [RANK:0] sample_packing_eff_est across ranks: [0.8623549818747429]
[2024-01-01 08:32:01,664] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] sample_packing_eff_est: 0.87
[2024-01-01 08:32:01,664] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] total_num_steps: 10376
[2024-01-01 08:32:01,671] [DEBUG] [axolotl.train.log:60] [PID:2201] [RANK:0] loading tokenizer... openlm-research/open_llama_3b_v2
[2024-01-01 08:32:01,945] [DEBUG] [axolotl.load_tokenizer:185] [PID:2201] [RANK:0] EOS: 2 / </s>
[2024-01-01 08:32:01,945] [DEBUG] [axolotl.load_tokenizer:186] [PID:2201] [RANK:0] BOS: 1 / <s>
[2024-01-01 08:32:01,945] [DEBUG] [axolotl.load_tokenizer:187] [PID:2201] [RANK:0] PAD: 2 / </s>
[2024-01-01 08:32:01,945] [DEBUG] [axolotl.load_tokenizer:188] [PID:2201] [RANK:0] UNK: 0 / <unk>
[2024-01-01 08:32:01,946] [INFO] [axolotl.load_tokenizer:193] [PID:2201] [RANK:0] No Chat template selected. Consider adding a chat template for easier inference.
[2024-01-01 08:32:01,946] [DEBUG] [axolotl.train.log:60] [PID:2201] [RANK:0] loading model and peft_config...
[2024-01-01 08:32:02,058] [INFO] [axolotl.load_model:239] [PID:2201] [RANK:0] patching with flash attention for sample packing
[2024-01-01 08:32:02,058] [INFO] [axolotl.load_model:285] [PID:2201] [RANK:0] patching _expand_mask
pytorch_model.bin: 100%|████████████████████| 6.85G/6.85G [01:01<00:00, 111MB/s]
generation_config.json: 100%|███████████████████| 137/137 [00:00<00:00, 592kB/s]
[2024-01-01 08:33:13,199] [INFO] [axolotl.load_model:517] [PID:2201] [RANK:0] GPU memory usage after model load: 3.408GB (+0.334GB cache, +1.952GB misc)
[2024-01-01 08:33:13,204] [INFO] [axolotl.load_model:540] [PID:2201] [RANK:0] converting PEFT model w/ prepare_model_for_kbit_training
[2024-01-01 08:33:13,208] [INFO] [axolotl.load_model:552] [PID:2201] [RANK:0] converting modules to torch.float16 for flash attention
[2024-01-01 08:33:13,238] [WARNING] [auto_gptq.nn_modules.qlinear.qlinear_cuda.<module>:16] [PID:2201] CUDA extension not installed.
[2024-01-01 08:33:13,238] [WARNING] [auto_gptq.nn_modules.qlinear.qlinear_cuda_old.<module>:15] [PID:2201] CUDA extension not installed.
trainable params: 12,712,960 || all params: 3,439,186,560 || trainable%: 0.36965020007521776
[2024-01-01 08:33:13,490] [INFO] [axolotl.load_model:582] [PID:2201] [RANK:0] GPU memory usage after adapters: 3.455GB (+1.099GB cache, +1.952GB misc)
[2024-01-01 08:33:13,526] [INFO] [axolotl.train.log:60] [PID:2201] [RANK:0] Pre-saving adapter config to ./lora-out
[2024-01-01 08:33:13,529] [INFO] [axolotl.train.log:60] [PID:2201] [RANK:0] Starting trainer...
[2024-01-01 08:33:13,935] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 10733491
[2024-01-01 08:33:13,982] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 10733491
0%| | 0/1490 [00:00<?, ?it/s][2024-01-01 08:33:14,084] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 10733491
{'loss': 1.3828, 'learning_rate': 1e-05, 'epoch': 0.0}
0%| | 1/1490 [00:05<2:05:44, 5.07s/it][2024-01-01 08:33:19,125] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:33:19,322] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:33:19,323] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
0%| | 0/208 [00:00<?, ?it/s][2024-01-01 08:33:19,510] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
1%|▍ | 2/208 [00:00<00:19, 10.70it/s][2024-01-01 08:33:19,697] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:33:19,878] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
2%|▊ | 4/208 [00:00<00:29, 6.83it/s][2024-01-01 08:33:20,056] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
2%|█ | 5/208 [00:00<00:31, 6.42it/s][2024-01-01 08:33:20,237] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
3%|█▏ | 6/208 [00:00<00:33, 6.12it/s][2024-01-01 08:33:20,418] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
3%|█▍ | 7/208 [00:01<00:33, 5.93it/s][2024-01-01 08:33:20,593] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
4%|█▋ | 8/208 [00:01<00:34, 5.86it/s][2024-01-01 08:33:20,763] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
4%|█▊ | 9/208 [00:01<00:33, 5.87it/s][2024-01-01 08:33:20,936] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
5%|██ | 10/208 [00:01<00:33, 5.84it/s][2024-01-01 08:33:21,110] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
5%|██▏ | 11/208 [00:01<00:33, 5.81it/s][2024-01-01 08:33:21,280] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
...
{'loss': 1.0228, 'learning_rate': 3.653864333275081e-09, 'epoch': 1.0}
{'loss': 1.1322, 'learning_rate': 2.0553041633952774e-09, 'epoch': 1.0}
{'loss': 1.0027, 'learning_rate': 9.134702554591811e-10, 'epoch': 1.0}
{'loss': 0.9021, 'learning_rate': 2.283678246284282e-10, 'epoch': 1.0}
{'loss': 1.1726, 'learning_rate': 0.0, 'epoch': 1.0}
{'train_runtime': 6355.7444, 'train_samples_per_second': 8.414, 'train_steps_per_second': 0.234, 'train_loss': 1.0881121746245646, 'epoch': 1.0}
100%|█████████████████████████████████████| 1490/1490 [1:45:55<00:00, 4.27s/it]
[2024-01-01 10:19:09,776] [INFO] [axolotl.train.log:60] [PID:2201] [RANK:0] Training Completed!!! Saving pre-trained model to ./lora-out- 在 Nividia A 100 80 GB GPU 上训练耗时 1 小时 45 分钟
- 训练检查点发生并保存在 lora-out 文件夹下,该文件夹是 lora.yaml 文件中指定的输出目录
- 此外,适配器文件也保存在 lora.yaml 文件中指定的输出目录中。
- 此外,可以通过在 lora.yaml 文件中的 push_dataset_to_hub 参数中指定 repoid 和文件夹详细信息,将训练好的模型推送到存储库 huggingface
5、使用 gradio 进行交互式推理
# gradio
!accelerate launch -m axolotl.cli.inference examples/openllama-3b/lora.yml --lora_model_dir="./lora-out" --gradioThe following values were not passed to `accelerate launch` and had defaults used instead:
`--num_processes` was set to a value of `1`
`--num_machines` was set to a value of `1`
`--mixed_precision` was set to a value of `'no'`
`--dynamo_backend` was set to a value of `'no'`
To avoid this warning pass in values for each of the problematic parameters or run `accelerate config`.
/usr/local/lib/python3.10/dist-packages/transformers/deepspeed.py:23: FutureWarning: transformers.deepspeed module is deprecated and will be removed in a future version. Please import deepspeed modules directly from transformers.integrations
warnings.warn(
[2024-01-01 10:43:34,869] [INFO] [datasets.<module>:58] [PID:5297] PyTorch version 2.0.1+cu118 available.
dP dP dP
88 88 88
.d8888b. dP. .dP .d8888b. 88 .d8888b. d8888P 88
88' `88 `8bd8' 88' `88 88 88' `88 88 88
88. .88 .d88b. 88. .88 88 88. .88 88 88
`88888P8 dP' `dP `88888P' dP `88888P' dP dP
[2024-01-01 10:43:35,772] [INFO] [axolotl.validate_config:156] [PID:5297] [RANK:0] bf16 support detected, but not enabled for this configuration.
[2024-01-01 10:43:35,772] [WARNING] [axolotl.validate_config:176] [PID:5297] [RANK:0] `pad_to_sequence_len: true` is recommended when using sample_packing
[2024-01-01 10:43:36,062] [INFO] [axolotl.normalize_config:150] [PID:5297] [RANK:0] GPU memory usage baseline: 0.000GB (+0.811GB misc)
[2024-01-01 10:43:36,064] [INFO] [axolotl.common.cli.load_model_and_tokenizer:49] [PID:5297] [RANK:0] loading tokenizer... openlm-research/open_llama_3b_v2
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
[2024-01-01 10:43:36,345] [DEBUG] [axolotl.load_tokenizer:185] [PID:5297] [RANK:0] EOS: 2 / </s>
[2024-01-01 10:43:36,345] [DEBUG] [axolotl.load_tokenizer:186] [PID:5297] [RANK:0] BOS: 1 / <s>
[2024-01-01 10:43:36,345] [DEBUG] [axolotl.load_tokenizer:187] [PID:5297] [RANK:0] PAD: 2 / </s>
[2024-01-01 10:43:36,345] [DEBUG] [axolotl.load_tokenizer:188] [PID:5297] [RANK:0] UNK: 0 / <unk>
[2024-01-01 10:43:36,345] [INFO] [axolotl.load_tokenizer:193] [PID:5297] [RANK:0] No Chat template selected. Consider adding a chat template for easier inference.
[2024-01-01 10:43:36,345] [INFO] [axolotl.common.cli.load_model_and_tokenizer:51] [PID:5297] [RANK:0] loading model and (optionally) peft_config...
[2024-01-01 10:43:44,496] [INFO] [axolotl.load_model:517] [PID:5297] [RANK:0] GPU memory usage after model load: 3.408GB (+0.334GB cache, +1.850GB misc)
[2024-01-01 10:43:44,501] [INFO] [axolotl.load_model:540] [PID:5297] [RANK:0] converting PEFT model w/ prepare_model_for_kbit_training
[2024-01-01 10:43:44,505] [INFO] [axolotl.load_model:552] [PID:5297] [RANK:0] converting modules to torch.float16 for flash attention
[2024-01-01 10:43:44,506] [DEBUG] [axolotl.load_lora:670] [PID:5297] [RANK:0] Loading pretained PEFT - LoRA
[2024-01-01 10:43:44,533] [WARNING] [auto_gptq.nn_modules.qlinear.qlinear_cuda.<module>:16] [PID:5297] CUDA extension not installed.
[2024-01-01 10:43:44,533] [WARNING] [auto_gptq.nn_modules.qlinear.qlinear_cuda_old.<module>:15] [PID:5297] CUDA extension not installed.
trainable params: 12,712,960 || all params: 3,439,186,560 || trainable%: 0.36965020007521776
[2024-01-01 10:43:44,851] [INFO] [axolotl.load_model:582] [PID:5297] [RANK:0] GPU memory usage after adapters: 3.455GB (+1.148GB cache, +1.850GB misc)
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://87eb53a4929499e106.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)6、结束语
在这里,我们探索了如何利用 Axolotl 并使用 gradio 对微调模型进行几乎不执行代码微调和推理。
原文链接:No Code LLM Fine Tuning using Axolotl
汇智网翻译整理,转载请标明出处
