打造免费的本地AI助手
在本文中,我将介绍使用 LangChain、Chroma 实现 RAG 管道的 Flask 应用程序的开发。该应用程序允许用户上传 PDF 文档、存储嵌入并查询它们以进行信息检索。

如果你想使用自己的本地 AI 助手或文档查询系统,我将在本文中解释如何使用,最好的部分是,你无需为任何 AI 请求付费。
现代应用程序需要强大的解决方案来访问和检索 PDF 等非结构化数据中的相关信息。检索增强生成 (RAG) 是一种尖端方法,将 AI 的语言生成功能与基于向量的搜索相结合,以提供准确、上下文感知的答案。
在本文中,我将介绍使用 LangChain、Chroma 实现 RAG 管道的 Flask 应用程序的开发。该应用程序允许用户上传 PDF 文档、存储嵌入并查询它们以进行信息检索——所有这些都由 Ollama 提供支持。
如果你准备在计算机或服务器上创建一个简单的 RAG 应用程序,本文将为你提供指导。换句话说,你将学习如何构建自己的本地助手或文档查询系统。
我们将构建什么
我们的应用程序包括以下功能:
- 查询通用 AI 的任何问题。你可以使用 flask post 方法向本地 LLM 模型直接提问
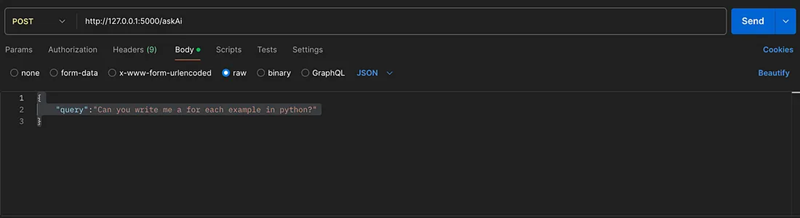
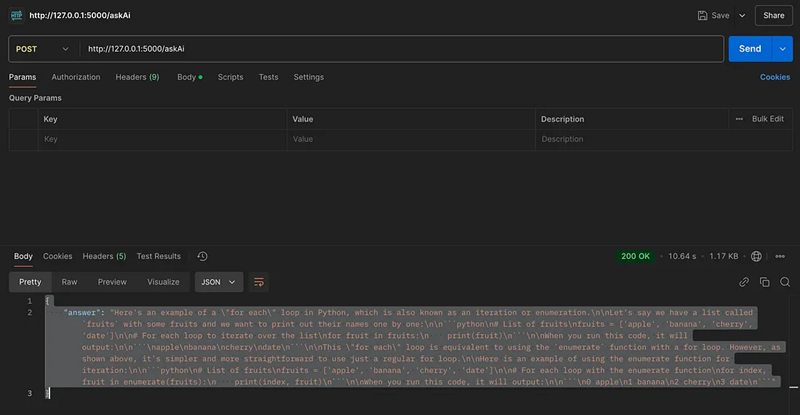
- 上传 PDF 文档进行处理和存储。你可以将 PDF 上传到本地存储和本地向量数据库。
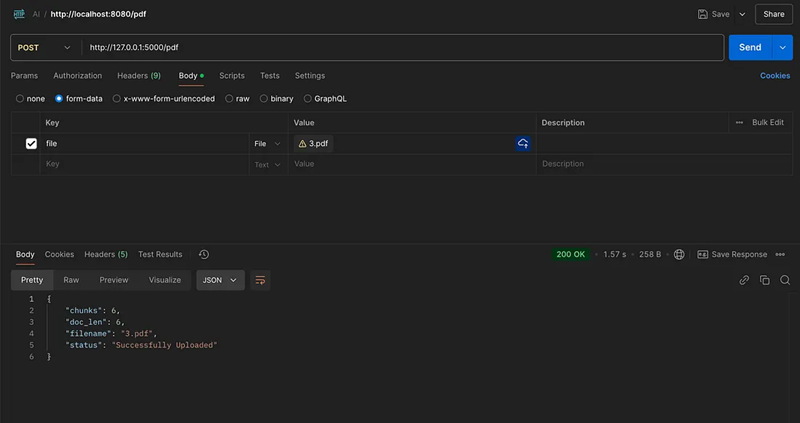
- 你可以询问有关文档的任何问题。检索特定于上传 PDF 内容的答案。
技术栈:工具和库
我们将使用以下技术栈来构建此应用程序:
- Flask:用于创建 REST API 的轻量级 Python 框架。
- LangChain:用于构建检索和生成管道。
- Chroma:用于存储和查询文档嵌入的向量存储。
- PDFPlumber:用于从 PDF 中提取文本。
- Ollama LLM:开源大型语言模型以生成 AI 响应。
1、设置 Flask
Flask 是我们 API 的骨干。它公开了处理用户查询、PDF 上传和 AI 响应所需的端点。
首先,我们访问本地 LLM,然后使用 Json 返回答案:
cached_llm = Ollama(model="llama3.2:latest")
@app.route("/askAi", methods=["POST"])
def ask_ai():
print("Post /ai called")
json_content = request.json
query = json_content.get("query")
print(f"query: {query}")
response = cached_llm.invoke(query)
print(response)
response_answer = {"answer": response}
return response_answer2、上传和处理 PDF
使用 PDFPlumber,我们从 PDF 中提取文本。 LangChain 的 RecursiveCharacterTextSplitter 将文本拆分为可管理的块,这些块嵌入并存储在 Chroma 中,以便高效查询:
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = PDFPlumberLoader("example.pdf")
docs = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=80)
chunks = text_splitter.split_documents(docs)3、在 Chroma 中存储数据
Chroma 用作我们的矢量数据库,存储文档块的嵌入。这些嵌入允许在检索期间进行基于相似性的搜索:
from langchain_community.vectorstores import Chroma
vector_store = Chroma.from_documents(chunks, embedding=FastEmbedEmbeddings())
vector_store.persist(directory="db")4、查询 PDF
/askPdf 端点从向量存储中检索上下文,并使用提示模板通过 AI 模型生成答案:
@app.route("/askPdf", methods=["POST"])
def ask_pdf():
query = request.json["query"]
retriever = vector_store.as_retriever(search_type="similarity_score_threshold")
chain = create_retrieval_chain(retriever, document_chain)
result = chain.invoke({"input": query})
return {"answer": result["answer"]}5、API端点概述
Flask 应用程序提供三个主要端点:
/askAi:直接查询 AI 以获得通用答案。/askPdf:查询已上传的 PDF 以获得上下文特定的答案。/addPdf:上传并处理 PDF 文档以进行存储。
每个API端点都设计得简单易用,并与 LangChain 框架紧密集成以进行 RAG 操作。
4、运行应用程序
首先,你必须启动 Ollama 提供服务,然后安装需要的库:
ollama serve # 1. 启动ollama提供服务
pip install -r requirements.txt # 2. 安装必要的库
python app.pyhttp://127.0.0.1:5000 # 3. 运行程序5、挑战与解决方案
- 高效文本分块
在不丢失上下文的情况下拆分文档至关重要。使用 LangChain 的 RecursiveCharacterTextSplitter,我们确保分块保持一致性,同时保持足够小以进行嵌入。
- 可扩展向量存储
Chroma 提供快速、轻量级的向量存储,非常适合处理大型数据集,同时支持快速查询。
- 上下文感知响应
自定义提示模板可确保 AI 模型将检索到的文档内容无缝集成到其答案中。
5、结束语
通过结合 AI、向量搜索和文档处理,此应用程序展示了 RAG 在解决实际问题方面的强大功能。无论你是研究人员、开发人员还是公司员工,本指南都为你提供了构建自定义文档查询系统的工具。
想要更进一步吗?克隆 GitHub 存储库并立即开始构建!
原文链接:Build Your Free AI Assistant-RAG Python &Ollama
汇智网翻译整理,转载请标明出处
