DuckDB VSS实现电影推荐
在本指南中,我们将使用DuckDB VSS扩展和Gemini构建一个可以解决 Netflix 早期挑战的电影推荐引擎。

你正站在古埃及,大约比现代日历早 250 年。当你的眼睛适应透过高窗照射进来的暖光时,你发现自己身处亚历山大大图书馆。你看到的景象令人震撼:书架向四面八方延伸,放着近 50 万卷卷轴。空气中弥漫着纸莎草的气味,你正在寻找有关天文学的著作。你听到图书馆最著名的学者卡利马科斯正在为你的问题寻找解决方案,发出沙沙声。
他通过创建世界上第一个图书馆目录 Pinakes 彻底改变了信息检索。他没有仅仅按作者或标题组织卷轴,而是开创了一种按主题和内容对作品进行分类的系统,使学者能够通过简单的字母浏览找到他们可能永远找不到的相关作品。

2000 多年后,我们面临着类似的挑战。在 Netflix 早期的数字档案中,工程师们致力于解决他们自己的亚历山大级问题。他们的电影推荐系统建立在简单的评级匹配之上,难以捕捉到电影真正相似的本质。一部关于婚礼的喜剧可能与一部浪漫剧有更多相似之处,而不是另一部关于体育的喜剧,但传统的分类方法——就像按物理属性组织卷轴一样——忽略了这些微妙的联系。这种语义理解的挑战——捕捉项目之间的真正含义和相似性——仍然是现代搜索和推荐系统的核心。
今天,我们站在一个有趣的十字路口。由于矢量搜索解决方案在检索增强生成 (RAG) 系统中的广泛使用,矢量搜索解决方案的发展有望解决这些语义匹配问题,但有一个问题:大多数解决方案都需要复杂的基础设施、大量资源和精心维护。但是,在某些情况下,这种复杂性有一个实用的答案:DuckDB 的向量相似性搜索 (VSS) 扩展。
在本指南中,我们将使用适合你笔记本电脑内存的现代工具构建一个可以解决 Netflix 早期挑战的电影推荐引擎。通过将 DuckDB 的 VSS 扩展与 Gemini 的嵌入功能相结合,我们将创建一个了解电影本质而不仅仅是其元数据的系统。无论你是构建下一个大型推荐引擎,还是只是想更好地理解向量搜索,这一实践之旅都将为你提供知识,以应对你自己项目中的语义搜索挑战。
1、文本到数字:理解嵌入
在深入研究相似性搜索之前,让我们先了解如何将电影描述转换为计算机可以理解的数字。这就是嵌入的作用所在。
嵌入的工作原理是将文本、图像和视频转换为浮点数数组(称为向量)。这些向量旨在捕捉文本、图像和视频的含义。嵌入数组的长度称为向量的维数。例如,一段文本可能由包含数百个维度的向量表示。
2、向量相似性搜索
一旦我们有了这些数值向量,我们就需要一些方法来测量它们的接近程度或相似程度。
DuckDB 在 v0.10.0 中引入了 ARRAY 数据类型,它存储固定大小的列表,以补充可变大小的 LIST 数据类型。
他们还为这种新的 ARRAY 类型添加了几个距离度量函数:array_distance、array_negative_inner_product 和 array_cosine_distance。使用这些距离函数,可以测量相似性:
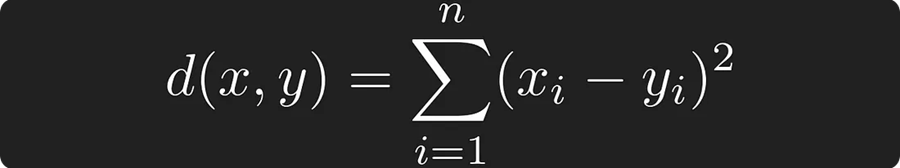
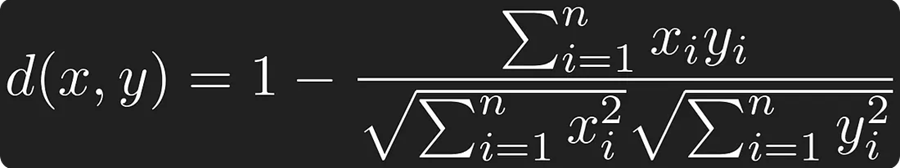
DuckDB 的 VSS 扩展随后增加了对分层可导航小世界 (HNSW) 索引的支持,以加速向量相似性搜索。
2、HNSW:了解小世界网络
让我们来了解一下 HNSW 索引是如何工作的。想象一下,你在纽约市试图寻找一位同时教授量子物理的魔兽世界玩家。以下是不同搜索方法的工作原理:
策略 1:强力搜索
拦住纽约市的每个人,询问他们是否符合您的标准。
- 时间:数月
- 准确率:100%
- 效率:不必要地检查数百万
策略 2:HNSW(智能分层搜索)
可以将其想象成一个组织巧妙的社交网络,具有不同的连接级别:
级别 3(顶级)——全球连接
- 例如了解主要游戏社区和大学物理系的领导者
- 快速、广泛的覆盖范围:“以下是需要检查的主要机构和游戏中心”
级别 2(中级)——地区连接
- 例如了解当地的魔兽世界公会领导和物理系负责人
- 更专注:“这三个物理部门拥有活跃的游戏社区”
级别1(基础级)——本地连接
- 直接了解个人游戏玩家和教授
- 候选人的精确匹配
搜索从顶层开始,快速识别有希望的领域,并有效地向下挖掘。对于 100 万名候选人,你将检查大约 20 名而不是全部 100 万名,同时保持 95-99% 的准确率。
3、构建电影推荐器
先决条件:
- Python 3.12
- 所需软件包:duckdb ≥ 1.1.3、httpx、google-cloud-aiplatform
- 电影数据的电影数据库 (TMDB) API 密钥
- 启用 Vertex AI 的 Google Cloud Platform (GCP) 服务帐户
3.1 设置
from typing import List, Dict
import duckdb
import httpx
from google.cloud import aiplatform
from vertexai.language_models import TextEmbeddingModel
tmdb_api_key: str = 'your-tmdb-api-key'
credentials = service_account.Credentials.from_service_account_file('your-sa.json')
aiplatform.init(project='your-project', location='us-central1', credentials=credentials)3.2 获取电影数据
我们使用 httpx 从 TMDB API 获取电影数据。此外,我们允许指定最低平均投票分数和计数,以将数据集缩小到更著名的电影。
def _get_movies(page: int, vote_avg_min: float, vote_count_min: float) -> List[Dict]:
""" Fetch movies from TMDB API """
response = httpx.get('https://api.themoviedb.org/3/discover/movie', headers={
'Authorization': f'Bearer {tmdb_api_key}'
}, params={
'sort_by': 'popularity.desc',
'include_adult': 'false',
'include_video': 'false',
'language': 'en-US',
'with_original_language': 'en',
'vote_average.gte': vote_avg_min,
'vote_count.gte': vote_count_min,
'page': page
})
response.raise_for_status() # Raise an error for bad responses
return response.json()['results']
def get_movies(pages: int, vote_avg_min: float, vote_count_min: float) -> List[Dict]:
""" Generator to yield movie data from multiple pages """
for page in range(1, pages + 1):
yield from _get_movies(page, vote_avg_min, vote_count_min)3.3 生成嵌入
我们使用 Gemini 的 text-embedding-004 模型生成嵌入并将向量维数设置为 256。
注意:嵌入生成和 DuckDB 表创建中的维度大小 (256) 必须匹配。
def embed_text(texts: List[str]) -> List[List[float]]:
""" Generate embeddings for a list of texts using Gemini """
model = TextEmbeddingModel.from_pretrained('text-embedding-004')
inputs = [TextEmbeddingInput(text, 'RETRIEVAL_DOCUMENT') for text in texts]
embeddings = model.get_embeddings(inputs, output_dimensionality=256)
return [embedding.values for embedding in embeddings]
# Fetch movies from TMDB API and generate embeddings
movie_data = list(get_movies(3, 6.0, 1000))
movies_for_embedding = [(movie['id'], movie['title'], movie['overview']) for movie in movie_data]
embeddings = embed_text([overview for _, _, overview in movies_for_embedding])3.4 DuckDB VSS 设置
下一步,我们在 DuckDB 中安装并加载 VSS 扩展,并启用持久性。这使我们能够将嵌入存储在数据库文件中。
INSTALL vss;
LOAD vss;
SET hnsw_enable_experimental_persistence = true;然后,我们使用与之前相同的维度创建表。
CREATE TABLE movies_vectors (
id INTEGER,
title VARCHAR,
vector FLOAT[256]
)插入嵌入后,我们在向量列上创建 HNSW 索引,以加快向量相似性搜索。
CREATE INDEX movies_vector_index ON movies_vectors USING HNSW (vector)然后,我们准备一个函数,以电影描述作为输入。这是来自用户的搜索查询。我们还根据此输入创建了一个嵌入向量。最后,我们使用 DuckDB 距离函数来获取相似的电影。
SELECT title
FROM movies_vectors
ORDER BY array_distance(vector, array[{vector_array}]::FLOAT[256])
LIMIT 3这样,DuckDB VSS 设置如下所示:
# Set up DuckDB with Vector Similarity Search (VSS) Extension and persistence enabled
# See: https://duckdb.org/docs/extensions/vss.html
with duckdb.connect(database='movies.duckdb') as conn:
conn.execute("""
INSTALL vss;
LOAD vss;
SET hnsw_enable_experimental_persistence = true;
""")
conn.execute("""
CREATE TABLE movies_vectors (
id INTEGER,
title VARCHAR,
vector FLOAT[256]
)
""")
# Insert embeddings into DuckDB
conn.executemany("INSERT INTO movies_vectors VALUES (?, ?, ?)", [
(movies_for_embedding[idx][0], movies_for_embedding[idx][1], embedding)
for idx, embedding in enumerate(embeddings) if len(embedding) == 256
])
# Create Hierarchical Navigable Small Worlds (HNSW) Index
conn.execute("CREATE INDEX movies_vector_index ON movies_vectors USING HNSW (vector)")
def search_similar_movies(query: str):
""" Search for movies similar to the given query description """
query_vector = embed_text([query])
vector_array = ', '.join(str(num) for num in query_vector[0])
query = conn.sql(f"""
SELECT title
FROM movies_vectors
ORDER BY array_distance(vector, array[{vector_array}]::FLOAT[256])
LIMIT 3
""")
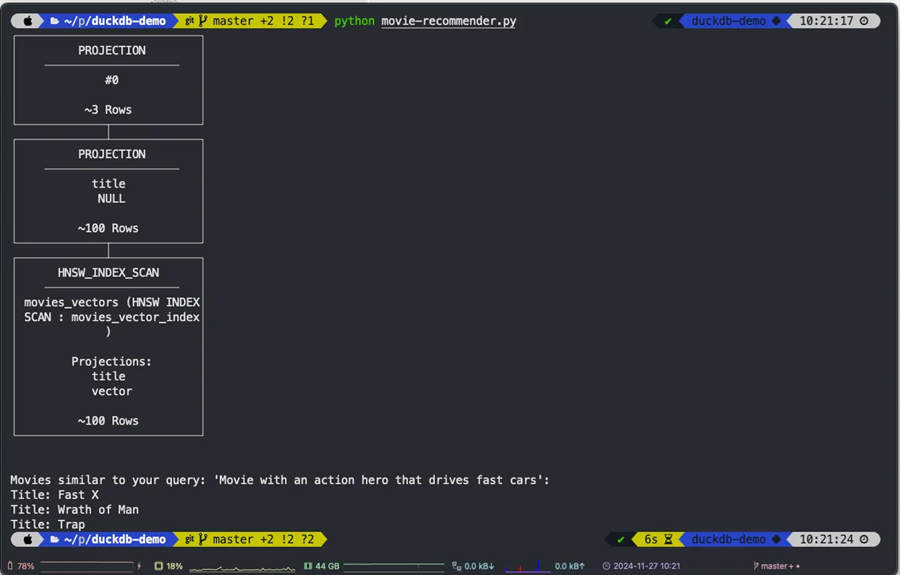
print(query.explain()) # Print the query plan to show the HNSW_INDEX_SCAN node
return query.fetchall()我们不仅返回相似性搜索结果,还使用 query.explain() 打印查询计划以显示实际使用了 HNSW 索引。
4、使用推荐器
将所有内容放在一起,这是完整的示例:
from typing import List, Dict
import duckdb
import httpx
from google.cloud import aiplatform
from google.oauth2 import service_account
from google.oauth2.service_account import Credentials
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
tmdb_api_key: str = 'your-tmdb-api-key'
credentials = service_account.Credentials.from_service_account_file('your-sa.json')
aiplatform.init(project='your-project', location='us-central1', credentials=credentials)
def _get_movies(page: int, vote_avg_min: float, vote_count_min: float) -> List[Dict]:
""" Fetch movies from TMDB API """
response = httpx.get('https://api.themoviedb.org/3/discover/movie', headers={
'Authorization': f'Bearer {tmdb_api_key}'
}, params={
'sort_by': 'popularity.desc',
'include_adult': 'false',
'include_video': 'false',
'language': 'en-US',
'with_original_language': 'en',
'vote_average.gte': vote_avg_min,
'vote_count.gte': vote_count_min,
'page': page
})
response.raise_for_status() # Raise an error for bad responses
return response.json()['results']
def get_movies(pages: int, vote_avg_min: float, vote_count_min: float) -> List[Dict]:
""" Generator to yield movie data from multiple pages """
for page in range(1, pages + 1):
yield from _get_movies(page, vote_avg_min, vote_count_min)
def embed_text(texts: List[str]) -> List[List[float]]:
""" Generate embeddings for a list of texts using Gemini """
model = TextEmbeddingModel.from_pretrained('text-embedding-004')
inputs = [TextEmbeddingInput(text, 'RETRIEVAL_DOCUMENT') for text in texts]
embeddings = model.get_embeddings(inputs, output_dimensionality=256)
return [embedding.values for embedding in embeddings]
# Fetch movies from TMDB API and generate embeddings
movie_data = list(get_movies(3, 6.0, 1000))
movies_for_embedding = [(movie['id'], movie['title'], movie['overview']) for movie in movie_data]
embeddings = embed_text([overview for _, _, overview in movies_for_embedding])
# Set up DuckDB with Vector Similarity Search (VSS) Extension and persistence enabled
# See: https://duckdb.org/docs/extensions/vss.html
with duckdb.connect(database='movies.duckdb') as conn:
conn.execute("""
INSTALL vss;
LOAD vss;
SET hnsw_enable_experimental_persistence = true;
""")
conn.execute("""
CREATE TABLE movies_vectors (
id INTEGER,
title VARCHAR,
vector FLOAT[256]
)
""")
# Insert embeddings into DuckDB
conn.executemany("INSERT INTO movies_vectors VALUES (?, ?, ?)", [
(movies_for_embedding[idx][0], movies_for_embedding[idx][1], embedding)
for idx, embedding in enumerate(embeddings) if len(embedding) == 256
])
# Create Hierarchical Navigable Small Worlds (HNSW) Index
conn.execute("CREATE INDEX movies_vector_index ON movies_vectors USING HNSW (vector)")
def search_similar_movies(query: str):
""" Search for movies similar to the given query description """
query_vector = embed_text([query])
vector_array = ', '.join(str(num) for num in query_vector[0])
query = conn.sql(f"""
SELECT title
FROM movies_vectors
ORDER BY array_distance(vector, array[{vector_array}]::FLOAT[256])
LIMIT 3
""")
print(query.explain()) # Print the query plan to show the HNSW_INDEX_SCAN node
return query.fetchall()
# Example Search
query_description = 'Movie with an action hero who drives fast cars'
similar_movies = search_similar_movies(query_description)
# Display results
print(f"Movies similar to your query: '{query_description}':")
for movie in similar_movies:
print(f"Title: {movie[0]}")你可以使用自然语言描述搜索类似的电影。例如:
query_description = 'Movie with an action hero who drives fast cars'
similar_movies = search_similar_movies(query_description)系统将:
- 将你的描述转换为 256 维向量
- 使用 HNSW 索引高效查找类似电影
- 返回前 3 个最接近的匹配项
5、结束语
记住 Callimachus和他的 Pinakes — 有时最优雅的解决方案也是最简单的。通常,科技行业对每个问题的答案都是增加更多基础设施。DuckDB VSS 提醒我们一个永恒的真理:你并不总是需要分布式系统来有效地解决挑战。正如古代图书管理员用基本原则创造了一个开创性的系统一样,我们也可以用简单、高效的工具来完成工作,以应对现代推荐挑战。
无论你是构建电影推荐引擎还是解决其他语义搜索挑战,这里展示的原则和技术都为你的项目提供了坚实的基础。向量相似性搜索的强大功能与 DuckDB 的简单性相结合,为创建复杂的搜索和推荐系统或检索增强生成 (RAG) 开辟了新的可能性,而无需分布式架构的复杂性。
原文链接:From Scrolls to Similarity Search: Building a Movie Recommender with DuckDB VSS
汇智网翻译整理,转载请标明出处
