构建语义搜索的弹性嵌入系统
当 ChatGPT 于 2022 年引起公众关注时,Airtable 的一小群工程师开始构思我们的平台可以利用这组新功能的不同方式。一个想法不断涌现:对客户数据进行丰富的语义搜索。

当 ChatGPT 于 2022 年引起公众关注时,Airtable 的一小群工程师开始构思我们的平台可以利用这组新功能的不同方式。一个想法不断涌现:对客户数据进行丰富的语义搜索。
想象一下,一个营销团队问:“你能找到与这个类似的过去活动吗?”,一个产品管理团队问:“你能找到专业知识与这个项目相匹配的工程师吗?”,或者在我的情况下,“你能找到与这个问题类似的过去问题(内部称为“升级”)吗?”。嵌入式驱动系统可以让团队快速识别通常需要数小时手工劳动的见解。
考虑构建一个嵌入式驱动系统:
嵌入是语义搜索的核心。嵌入是向量,数字数组,数据的数字表示,以机器可以理解的方式捕获含义。具体来说,嵌入可以告诉你“猫”类似于“虎斑猫”,但与“汽车”不同。
围绕嵌入构建系统并非易事。需要考虑多个维度:
嵌入生命周期管理(本文重点):
- 触发:随着数据变化,需要(重新)生成嵌入。我们需要持久地跟踪生成状态。
- 生成:通过 API 调用生成嵌入(通过网络或进程内)
- 持久性:嵌入存储在哪里以及如何存储
- 删除:不再需要旧数据时删除旧数据
- 一致性:我们如何保持矢量数据和主数据库之间的一致性?
- 迁移:这有几种形式,例如对数据库架构的更改、对数据库引擎的更改(例如 LanceDB 与 Opensearch)、对 AI 嵌入模型的更改或对底层存储层加密的更改
- 灾难恢复:如果数据丢失会怎样?
数据准备:
- 语料库选择:我们将嵌入哪些数据?
- 配置:嵌入模型选择、分块策略、其他旋钮
查询和访问:
- 查询:通过语义搜索或直接访问
- 索引:用于高效语义相似性查询的数据结构
- 权限:使语义搜索尊重我们的权限模型
操作问题:
- 安全性:嵌入是敏感的客户数据,必须进行相应处理
- 成本:我们如何保持生成、持久性和查询的成本可控?
- 分区管理:如果你有许多集合,如何处理分区数量的扩展?
考虑到所有这些,我们需要一个不仅功能齐全而且健壮且适应性强的系统。
1、Airtable 架构的高级概述
Airtable 提供了一个基于自定义内存数据库(由 MySql 支持)构建的应用构建平台。
让我们介绍一下我们将要使用的两个有用术语
- MemApp :我们的内存数据库,管理基础的所有读写操作。数据最终保存在 MySql 中。
- Base :MemApp 的特定实例
一个关键细节:MemApp 是一个单写入器数据库。所有写入都是连续发生的,这在我们谈论保持一致性时变得很重要。
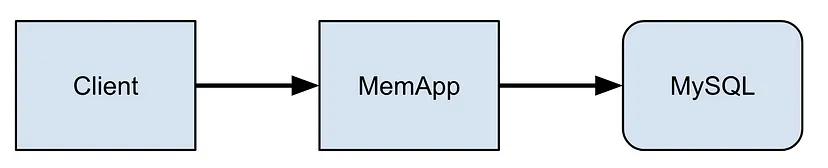
2、构建数据模型
完全一致还是最终一致?
我们的第一个基本设计问题是:嵌入是否应存储在 MemApp 中以确保与数据的完全一致性?虽然理论上很有吸引力,但这种方法有两个主要缺点:
- 成本:内存使用是 Airtable 费用的一个重要因素。在 MemApp 中存储嵌入会非常昂贵,因为嵌入通常是底层数据的 10 倍。
- 性能:实现强一致性需要在事务中生成嵌入。此过程对于批量更新来说太慢,并且会限制我们使用功能较差的内部模型,而不能利用 OpenAI 等顶级提供商。
解决方案?采用最终一致性,并在 MemApp 之外存储和处理嵌入。这一决定促使我们设计了一种数据流,其中嵌入是异步生成的,并存储在单独的向量数据库中 — 并在 MemApp 中跟踪其状态。
数据建模
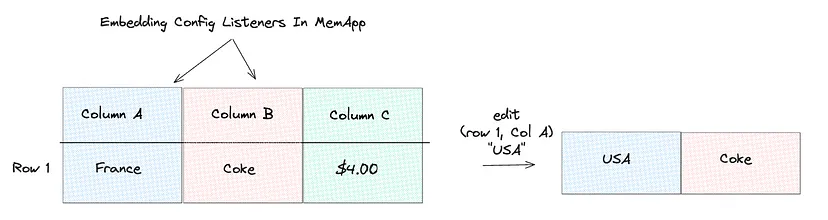
我们预计 AI 模型、嵌入提供商和存储引擎会不断发展。为了使我们的系统面向未来,我们在 MemApp 中引入了一个称为嵌入配置的抽象。这允许开发人员将数据从 MemApp 映射到向量数据库中的表,而不必担心底层的复杂性。
嵌入配置具有以下主要组件:
- 数据订阅:用户告诉我们他们想要嵌入的数据的声明性描述。
- 嵌入策略:如何嵌入数据
- 存储配置:数据存储位置。
- 触发配置:一旦数据过期,我们何时重新生成数据?
我们将在这篇文章中反复使用术语数据订阅和嵌入配置。
因为系统是最终一致性,我们知道我们需要跟踪数据订阅需要嵌入的每块数据的嵌入状态,这导致我们……
跟踪一致性:
鉴于我们最终保持一致,保存到我们的矢量数据库中的最新版本的数据将始终落后于 MemApp 中的数据。我们需要能够确定哪些数据已嵌入以及哪些数据可能已过期(用于过滤过时的结果或修复矢量数据库)。为了实现这一点,它有助于对数据版本进行排序。有序的数据版本还使我们能够处理无序写入操作。
由于 MemApp 是一个可序列化的数据库,因此它的事务号非常适合此目的 — 每次写入时都会递增的 BigInt。对于我们嵌入的每条数据,我们都会创建一个嵌入状态:
type EmbeddingState = {
// last recorded transaction that caused a write to the vector database
// this may be lower than the actual number in between when a write to
// the vector database occurs and when the update to MemApp occurs
// (those writes to MemApp may also be lost due to system failures)
lastPersistedTransaction: number | null,
// always correct and up to date, we update this transactionally when
// data in the data subscription is updated
lastUpdatedTransaction: number
}更具体地说,我们期望嵌入状态的生命周期内的更新如下所示:
// new data to be embedded enters the data subscription
{
lastPersistedTransaction: null,
lastUpdatedTransaction: 2,
}
// once the data is embedded, we mark it as up to date
{
lastPersistedTransaction: 2,
lastUpdatedTransaction: 2,
}
// data is edited, we mark it as stale so it can be re-embedded
{
lastPersistedTransaction: 2,
lastUpdatedTransaction: 5,
}3、嵌入的简单生命
以下是数据更改并需要重新嵌入时系统的粗略草图:
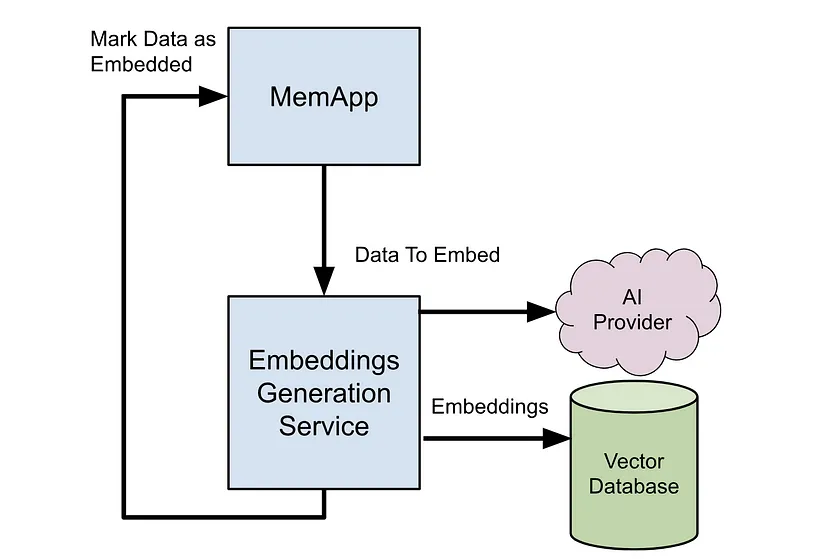
让我们在实践中介绍一下流程
初始化
在创建新的嵌入配置后,MemApp 会自动配置一个新的矢量数据库表并为每个相关数据块生成嵌入状态。
检测
当数据发生变化时,我们会更新嵌入状态的 lastUpdatedTransaction 以反映当前事务。
触发
创建任务以生成每个配置的嵌入,这些配置在其数据订阅中看到数据已更新。目前,我们在发生检测的事务中执行此操作。
生成
我们的嵌入服务处理任务并生成嵌入。如果失败,我们有足够的重试逻辑,这里还有一篇单独的博客文章,介绍如何防止行为不良的基地消耗来自 AI 提供商的全球速率限制或以其他方式降低服务质量。
持久性
一旦生成嵌入,我们就会将它们存储在我们的向量数据库中。我们通过使插入条件为写入的事务号大于存储在向量数据库中的事务号来防止无序写入。
如果更新速度已超过预期,我们会默默退出流程,因为无需再做任何工作。
然后,我们通过 MemApp 确认写入已发生,更新 lastPersistedTransaction。我们再次通过仅增加值来处理潜在的无序写入。
删除
删除单个嵌入状态将删除嵌入存储中的数据。我们再次使用条件删除来处理无序写入。
删除整个嵌入配置会触发所有数据的自动清理:我们删除相关的嵌入状态和向量数据库表。这降低了存储成本,并让我们满足各种数据保留保证。这实际上为系统创建了一个非常好的属性——这篇文章的真正内容……
4、实践中的操作—迁移和故障
系统发生故障,需求发生变化。我们需要一个处理以下问题的策略:
向量数据库故障:
- 数据库损坏——数据库存在,但处于不良状态
- 灾难性数据丢失——数据库被删除或不可用
向量数据库迁移:
- 架构迁移——存储新元数据
- 数据库引擎迁移——例如 LanceDB 到 Milvus 或反之亦然
- 数据驻留迁移——例如美国到欧盟
- KMS 迁移——当使用我们的 KMS 功能的客户轮换其加密密钥时
权限更改:
- AI 提供商更改——Airtable 支持多个 AI 提供商。如果用户禁止使用 OpenAI 并且只允许通过 Bedrock 提供的模型,该怎么办?
- 注意:不能/不应该跨模型比较嵌入。因此更新需要重新嵌入所有内容。
MemApp 迁移:
- 弃用 AI 模型:我们需要将 AI 模型更新为仍然受支持的模型
- 更新嵌入策略:如果我们改变了数据嵌入方式,我们会重新嵌入所有内容以保持比较的一致性
MemApp 操作:
- 更新数据订阅:这会更改我们嵌入的数据,因此通常需要完全重新嵌入数据
- 克隆基础:Airtable 允许您克隆数据库。我们需要单独的向量存储来保持数据模型随着时间的推移变得合理。
- 基础快照恢复 — Airtable 具有多年前的快照,可以在数据库中序列化
MemApp 向量数据库同步:
- MemApp 损坏 — 如果我们不为某些数据创建嵌入状态
- 检测更改错误 — 如果我们没有将更改传播到向量存储,因为我们无法检测到它们,该怎么办?
- 任务队列故障 — 如果我们的任务队列违反了其“至少一次交付”更新,会发生什么?
你可以想象出许多处理这些情况的方法。我发现自己反复想到的一个模式是:
- 删除旧的嵌入配置(如果存在,则清理旧数据)
- 在旧位置创建新的嵌入配置(可能使用新设置)
我们将此过程称为重置嵌入配置。
我意识到,如果系统检测到嵌入无效或即将无效,我们就可以处理所有这些情况,我们会重置嵌入配置。
将基地从美国移至欧盟就是一个例子。
当基地从美国移至欧盟时,与基地相关的敏感数据必须移至欧盟,而美国则不会保留任何数据。由于嵌入很敏感,因此也必须移动。为了处理这个问题,我们删除了基地中的每个嵌入配置,然后我们的系统会自动删除所有现有的嵌入数据,作为正常清理过程的一部分。然后,我们重新创建嵌入配置,并使用配置将数据存储在欧盟。瞧!基础的所有嵌入数据现已迁移。
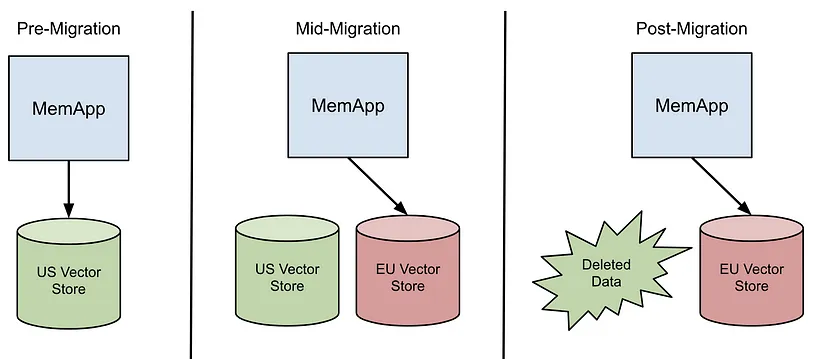
你可以针对上面列出的每个案例重复此练习。这种方法有几个我们必须考虑的权衡:
- 成本。重新生成嵌入会产生费用,但与增量更新的存储和索引成本相比,这些费用是可控的。
- 停机时间。重置嵌入会导致语义搜索功能暂时不可用。考虑到重置的罕见性和重新嵌入的速度(p99.9 不到 2 分钟),这是可以接受的。在产品级别处理这种停机时间已经是必要的,因为用户可以非常轻松地在产品中触发大规模生成(例如克隆基础)。
- 潜在的失控重置。我们必须实施保护措施以防止连续重置循环,这可能导致成本螺旋式上升和停机时间延长。我们结合使用了指标、警报、速率限制和幂等请求。
5、结束语
我们的嵌入系统并不完美,但它具有弹性和适应性。通过接受最终一致性并设计优雅地处理故障和迁移,我们建立了一个支持强大语义搜索功能的基础,并在我们找到利用 AI 来增强 Airtable 平台功能的新方法时继续迭代此系统。
我们完全忽略了其他一些有趣的主题,但将来可能会涉及:
- 嵌入生成中的故障
- MemApp 的停机时间
- 管理全局 AI 速率限制
- 向量索引的选择
- 如何应用过滤器和权限
原文链接:Building a Resilient Embedding System for Semantic Search at Airtable
汇智网翻译整理,转载请标明出处
