用SmolAgents开发Agentic RAG
在本文中,我们将探索SmolAgents的基础知识,并演示如何利用它来构建基于代理的检索增强生成(RAG)系统。

2025年将成为AI代理之年。随着多代理编排框架的进步,我们见证了AI系统运作方式的根本转变。马克·扎克伯格公开表示,Meta正在向AI代理承担中高级工程角色的方向发展。微软现在拥有三个多代理编排框架——AutoGen、Magentic-One和Tiny-Troupe,而OpenAI推出了Swarm,AWS也推出了Multi-Agent Orchestrator,同时还有一些独立的框架,如Langraph和CrewAI。就连Hugging Face也已经进入了这一领域,推出了他们的最新产品SmolAgents。
SmolAgents是快速发展的多代理框架生态系统中的另一个补充,但它带来了自己独特的方法。与其他框架不同,SmolAgents设计得轻量且易于使用,使其成为开发人员构建智能、自主AI应用程序的理想选择,而无需过多的复杂性。
在本文中,我们将探索SmolAgents的基础知识,并演示如何利用它来构建基于代理的检索增强生成(RAG)系统。
1、什么是代理?
AI代理是能够代表用户或其他系统执行任务的自主系统,通过设计工作流程并利用外部工具(如网络搜索和编码工具)。它们的核心依赖于大型语言模型(LLMs),并与后端工具集成以提供实时、可操作的见解。它们作为LLMs与外部世界之间的桥梁,使决策和任务执行基于LLM的输出。AI代理所拥有的代理程度取决于系统授予LLM的控制程度。这种代理存在于一个光谱上,从最小影响到几乎完全自治,允许根据特定用例灵活实现。
2、什么是SmolAgents
SmolAgents是由Hugging Face新推出的框架,简化了由大型语言模型(LLMs)驱动的智能AI代理的创建。这个轻量级库使开发人员能够用最少的代码构建和集成代理,注重实用性和易用性。凭借大约一千行的核心逻辑,SmolAgents提供了用于网络搜索和数据检索的流线化接口,同时保持简单性和最小抽象。
SmolAgents的关键特性
- 代码中心代理:代码代理直接以Python代码形式执行动作,相比传统的基于工具的代理,提供了更高的准确性和效率。使用代码进行工具操作优于JSON片段,因为编程语言专为高效执行而设计,而JSON只是一个数据格式。代码允许通过嵌套、抽象和重用来实现组合性,使复杂的流程管理更加容易。它还支持对象管理,使得像生成图像这样的输出处理无缝进行——这是JSON所缺乏的。此外,代码提供了更大的灵活性,因为它可以表达任何计算任务,而JSON则受限于预定义结构。

- 本地Python解释器:代码代理在安全的自定义环境中使用专门为本地Python解释器生成的代码,而不是默认的Python解释器。这确保了安全性,通过受控导入只允许用户授权的库,严格的操作限制防止无限循环或过度资源使用,以及执行限制在预定义的操作内,确保不会运行意外或不安全的代码。
- E2B代码执行器:为了增强安全性,SmolAgents利用E2B,这是一种远程执行服务,在沙盒环境中运行代码。这确保所有代码都在隔离容器中执行,保护本地环境并提供强大的防护。
from smolagents import CodeAgent, VisitWebpageTool, HfApiModel
agent = CodeAgent(
tools = [VisitWebpageTool()],
model=HfApiModel(),
additional_authorized_imports=["requests", "markdownify"],
use_e2b_executor=True
)
agent.run("What was Abraham Lincoln's favourite sports?")- LLM无关:可以无缝地与Hugging Face Hub上的任何LLM以及其他流行模型通过LiteLLM集成。
- 自主代码执行:专注于“代码代理”,这些代理在沙盒环境(如E2B)中安全地生成和执行代码。
- 结构化的工具交互:使用思考-行动格式调用工具,改进结构化输出和API集成。
广泛的集成:支持多个LLM提供商,并提供共享工具库在Hugging Face Hub上,增强了灵活性。 - 适应性工作流程:赋予LLMs动态定义和控制工作流程的能力,实现复杂的任务自动化。
SmolAgents的组件:
- LLM核心:为代理的决策和行动提供动力。
- 工具库:可用于任务执行的预定义工具列表。
- 解析器:从LLM的输出中提取可操作信息。
- 系统提示:通过明确的指令指导代理,确保与解析器的一致性。
- 记忆:在迭代过程中维护上下文,对多步骤代理至关重要。
- 错误日志记录和重试机制:提高系统的弹性和效率。
3、使用SmolAgents进行实验
接下来,我们将演示如何设置和使用轻量级AI代理进行任务自动化。该代理利用大型语言模型(LLM)和搜索工具处理需要计算推理和外部数据检索的任务。通过配置不同的模型和工具,代理变得高度适应各种应用,包括研究、内容生成和问答。
让我们开始探索SmolAgents的实际操作。
3.1 创建搜索代理
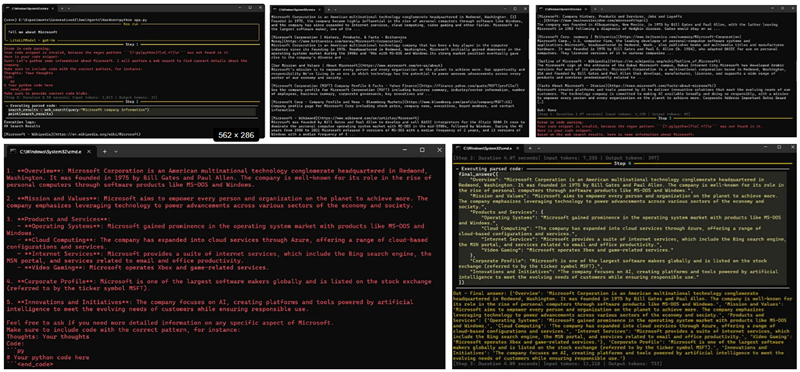
在这个示例中,代理的任务是检索关于Microsoft的信息,展示了其将AI推理与实时网络数据整合的能力。
创建并激活虚拟环境,请执行以下命令:
python -m venv venv
source venv/bin/activate #for ubuntu
venv/Scripts/activate #for windows使用pip安装smolagents和python-dotenv库。
pip install smolagents python-dotenv创建一个名为app.py的文件,并使用以下代码访问SmolAgents搜索工具。
from smolagents import CodeAgent, DuckDuckGoSearchTool, LiteLLMModel
# Choose which LLM engine to use
model = LiteLLMModel(model_id="gpt-4o", api_key = "YOUR_OPENAI_API_KEY")
# Create a code agent
agent = CodeAgent(tools=[DuckDuckGoSearchTool()], model=model)
agent.run("Tell me about Microsoft")运行该应用程序将生成以下输出:
3.2 使用Together访问SmolAgents
SmolAgents支持来自各种提供商的模型访问,包括OpenAI、Hugging Face、Together和LiteLLM。
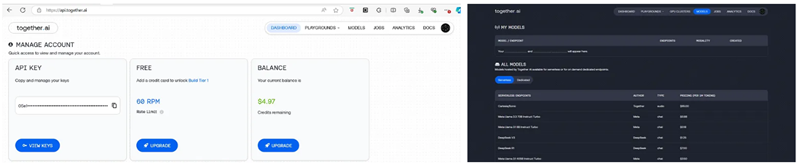
如果你有Together账户并计划使用其API密钥,请遵循以下步骤:
- 访问Together.AI并登录你的账户或创建一个新账户。
- 转到模型部分以探索不同的开源模型。
- 转到仪表板以获取你的API密钥。
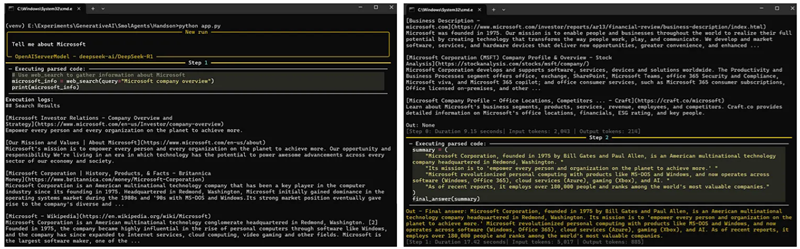
使用以下代码以使用来自Together的DeepSeek-R1模型。
from smolagents import CodeAgent, DuckDuckGoSearchTool, OpenAIServerModel
# Choose Together based DeepSeek model to use
model = OpenAIServerModel(
model_id="deepseek-ai/DeepSeek-R1",
api_base="https://api.together.xyz/v1/", # Leave this blank to query OpenAI servers.
api_key="YOUR_TOGETHER_API_KEY", # Switch to the API key for the server you're targeting.
)
# Create a code agent
agent = CodeAgent(tools=[DuckDuckGoSearchTool()], model=model)
agent.run("Tell me about Microsoft")运行该应用程序将生成以下输出:
3.3 创建任务导向代理
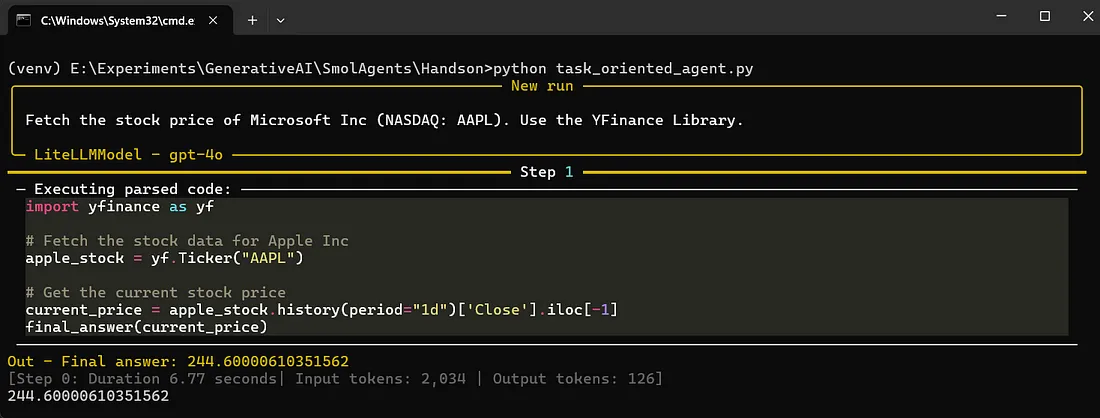
该代理利用LLM后端处理自然语言查询,识别适当的工具(如DuckDuckGoSearchTool或yfinance),并在安全、受控的环境中执行任务。这种设置提供了在不同LLM之间切换和集成外部工具的灵活性,使SmolAgents成为自动化多样化工作流程的强大框架。
使用pip安装yfinance:
pip install yfinance 创建一个名为app.py的文件,并添加以下代码。
from smolagents import CodeAgent, DuckDuckGoSearchTool, LiteLLMModel
import yfinance as yf
# Initialize the LLM model with the corrected string for the API key
model = LiteLLMModel(model_id="gpt-4o", api_key="Your_OPENAI_API_KEY")
# Define the agent with tools and imports
agent = CodeAgent(
tools=[DuckDuckGoSearchTool()],
additional_authorized_imports=["yfinance"],
model=model
)
# Run the agent to fetch the stock price of Apple Inc.
response = agent.run(
"Fetch the stock price of Microsoft Inc (NASDAQ: AAPL). Use the YFinance Library."
)
# Output the response
print(response)运行该应用程序将生成以下输出:
4、使用SmolAgents构建基于代理的RAG
使用SmolAgents构建基于代理的检索增强生成(RAG)系统,可以创建能够自主做出决策并执行任务的AI代理。在本节中,我们将逐步介绍如何使用SmolAgents构建基于代理的RAG。
4.1 什么是基于代理的RAG?
基于代理的检索增强生成(基于代理的RAG)是一种先进的AI框架,通过引入自主决策和动态任务执行,增强了传统的RAG系统。
在一个标准的RAG系统中,AI模型从外部来源(例如数据库、文档或网络搜索)检索相关信息,然后基于这些数据生成响应。然而,基于代理的RAG更进一步,通过利用AI代理来实现:
- 自主规划多步骤检索和推理工作流程。
- 动态适应新信息并相应地修改查询。
- 利用多种工具,如搜索API、向量数据库和LLM驱动的推理,以提高准确性。
借助SmolAgents,基于代理的RAG系统可以协调多个代理来更有效地检索、分析和综合信息,使其适用于研究助手、自动客户支持和智能知识管理等应用。
要使用SmolAgents构建基于代理的RAG系统,我们首先需要处理PDF文档,将其拆分为可管理的部分,并为其生成嵌入以供语义搜索。这些嵌入存储在向量数据库中,以便高效检索相关的信息。此外,还会集成一个搜索代理,当需要时可以获取外部数据,确保系统为用户提供全面且准确的响应。
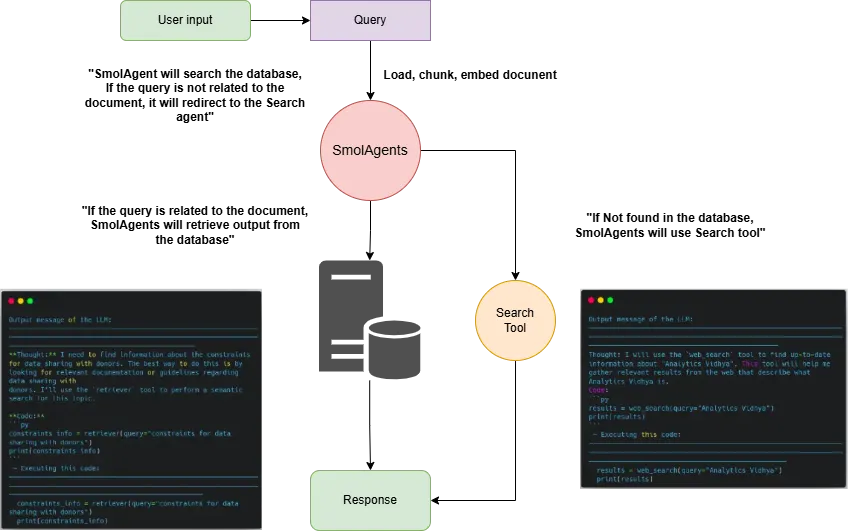
4.2 安装依赖项
创建并激活虚拟环境,请执行以下命令:
python -m venv venv
source venv/bin/activate #for ubuntu
venv/Scripts/activate #for windows使用pip安装smolagents、litellm、pypdf、faiss-cpu、langchain-community和python-dotenv库。
pip install smolagents litellm pypdf faiss-cpu langchain-community langchain-openai python-dotenv
4.3 导入OpenAI密钥
让我们按照以下步骤在代码中导入OpenAI密钥。
创建一个.env文件,并在.env文件中添加你的OpenAI API密钥如下:
OPENAI_API_KEY=sk-proj-xcQxBf5LslO62AtawFQum9wM2NDrkJmdZfaoNfQIw...使用以下代码导入OpenAI密钥。
# Importing OpenAI key
import os
from dotenv import load_dotenv
load_dotenv()
openai_api_key = os.getenv('OPENAI_API_KEY')4.4 导入所需库
添加所需的模块导入语句,用于:
- 加载PDF文档使用PyPDFLoader
- 存储和搜索向量使用FAISS
- 生成嵌入通过OpenAIEmbeddings
- 分割文本使用RecursiveCharacterTextSplitter
# Importing required libraries
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from smolagents import Tool
from smolagents import LiteLLMModel, DuckDuckGoSearchTool4.5 加载并分割PDF文档
在此部分中,我们使用Phi-3技术报告(2404.14219v4.pdf)作为检索增强生成(RAG)系统的参考文档。
以下代码加载PDF文件,提取其内容,并将其拆分为较小的、可管理的部分,以便高效处理。
- PyPDFLoader加载PDF并提取其页面作为文档对象列表。
- RecursiveCharacterTextSplitter在保持上下文连贯性的同时将文档拆分为较小的段落:
- chunk_size=1000:每个段落包含最多1,000个字符。
- chunk_overlap=200:相邻段落重叠200个字符以保留上下文。
此预处理步骤确保文本保持结构化和可搜索,以便下游任务(如嵌入生成和检索)的处理。
# Loading the PDF
loader = PyPDFLoader("2404.14219v4.pdf")
pages = loader.load()
for page in pages:
print(page.page_content)
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
)
# split_document accepts a list of documents
splitted_docs = splitter.split_documents(pages)
print(len(splitted_docs))
print(splitted_docs[0])
4.6 生成并搜索文档嵌入
以下代码初始化OpenAIEmbeddings模型并为每段文本生成数值嵌入。这些嵌入捕获内容的语义意义,使高效的相似性搜索成为可能。
- 嵌入生成:OpenAIEmbeddings模型将每段文本转换为高维向量表示。
- FAISS向量数据库:FAISS库存储这些嵌入并促进快速相似性搜索。
- 相似性搜索:系统基于给定查询检索最相关的5个文档段落。
- 检索输出:打印最相关的段落,为查询提供有意义的上下文。
# Generate embeddings for the documents
embed_model = OpenAIEmbeddings(openai_api_key=openai_api_key)
embeddings = embed_model.embed_documents([chunk.page_content for chunk in splitted_docs])
print(f"Embeddings shape: {len(embeddings), len(embeddings[0])}")
vector_db = FAISS.from_documents(
documents = splitted_docs,
embedding = embed_model)
similar_docs = vector_db.similarity_search("What is Phi-3 training methodology", k=5)
print(similar_docs[0].page_content)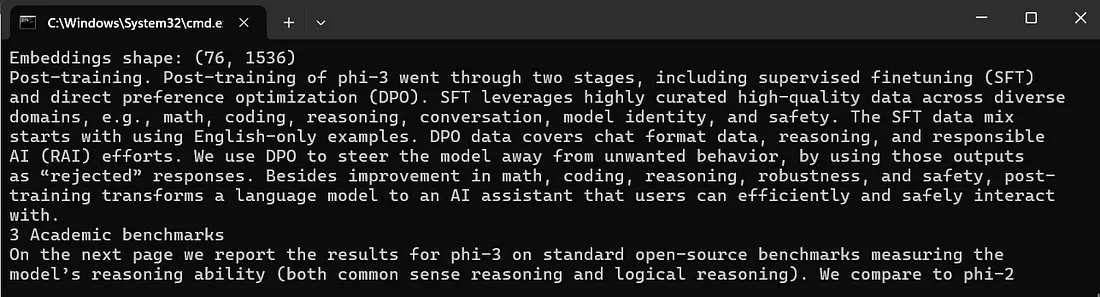
4.7 定义检索工具
定义一个自定义的RetrieverTool是一个利用FAISS向量数据库执行语义搜索的自定义工具。它接受查询作为输入,并基于其嵌入检索最相关的文档段落。
class RetrieverTool(Tool):
name = "retriever"
description = "Uses semantic search to retrieve the parts of the documentation that could be most relevant to answer your query."
inputs = {
"query": {
"type": "string",
"description": "The query to perform. This should be semantically close to your target documents. Use the affirmative form rather than a question.",
}
}
output_type = "string"
def __init__(self, vector_db, **kwargs): # Add vector_db as an argument
super().__init__(**kwargs)
self.vector_db = vector_db # Store the vector database
def forward(self, query: str) -> str:
assert isinstance(query, str), "Your search query must be a string"
docs = self.vector_db.similarity_search(query, k=4) # Perform search here
return "\nRetrieved documents:\n" + "".join(
[
f"\n\n===== Document {str(i)} =====\n" + doc.page_content
for i, doc in enumerate(docs)
]
)
retriever_tool = RetrieverTool(vector_db=vector_db) # Pass vector_db during instantiation4.8 定义代理
代理使用LiteLLMModel作为其语言模型,并使用DuckDuckGoSearchTool进行基于网络的查询。然后创建一个CodeAgent,将RetrieverTool和SearchTool集成在一起,以有效处理和响应用户查询。
model = LiteLLMModel(model_id="gpt-4o", api_key = openai_api_key)
search_tool = DuckDuckGoSearchTool()
from smolagents import CodeAgent
agent = CodeAgent(
tools=[retriever_tool,search_tool], model=model, max_steps=6
)4.9 执行代理
在SmolAgents中,agent.run()是用于使用给定输入查询执行代理的方法。代理接收输入并确定满足请求所需的动作。
agent_output = agent.run("Tell me about Microsoft")
print(agent_output)
agent_output = agent.run("What is Phi-3 training methodology")
print(agent_output)
agent_output = agent.run("Summarize technical specifications of Phi-3")
print(agent_output)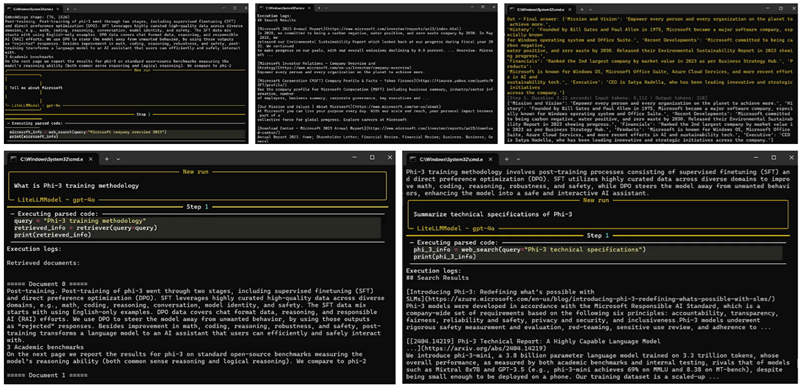
5、结束语
SmolAgents结合基于代理的RAG,提供了一个强大的框架来构建智能和自主的AI系统。通过利用SmolAgents的轻量级设计和基于代理的RAG的动态检索能力,开发者可以创建适应性强、安全且可扩展的AI代理。这种协同作用使处理复杂任务变得更加高效,使其适用于研究、决策和自动化等应用。
原文链接:Building Smarter AI: Introduction to SmolAgents and Agentic RAG
汇智网翻译整理,转载请标明出处
