构建知识图谱驱动的AI代理
在这篇文章中,我们展示了如何构建可以轻松集成基于数据库的工具的自主应用程序。虽然我们专注于Neo4j知识图谱的GraphRAG用例,但可以在同一个自主应用程序中结合不同的数据源和类型的数据库。
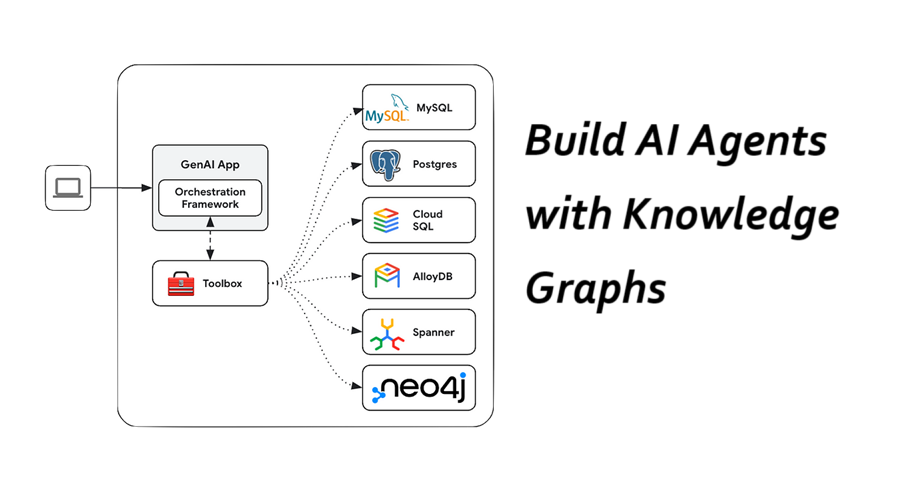
上个月,Google宣布了公共测试版发布的Gen AI工具箱对数据库的支持。今天,我们很高兴地宣布工具箱支持Neo4j,一个图形数据库管理系统。Neo4j一直是支持和开发工具箱的关键合作伙伴。他们的加入使使用Neo4j的开发人员和组织能够创建访问其数据的代理工具,使用流行的GraphRAG技术,扩展了工具箱在Gen AI应用中的实用性。
1、Neo4j — 图形数据库管理系统
Neo4j是领先的开源图形数据库——它将信息管理为实体(节点)及其之间的关系,而不是表格,允许灵活且强大的连接信息表示。图形为许多领域如生物医学、供应链、制造、欺诈检测和运输物流等提供了独特的功能。您可以将其视为您组织的数字孪生体的知识图谱(包括人员、流程、产品、合作伙伴等)是LLM语言技能的一个很好的“事实记忆”伴侣。使用GraphRAG可以提高GenAI应用程序的准确性、可靠性和可解释性。
2、Gen AI工具箱
在创建访问数据库的工具时,开发人员在生产中构建AI代理时会遇到许多挑战:认证、授权、清理、连接池等。这些挑战可能会成为负担,减慢开发速度,并在反复实现相同的样板代码时留下犯错的空间。
Gen AI工具箱——这个开源服务器可以帮助您更轻松、更快捷、更安全地开发工具。工具箱位于您的应用程序和数据库之间——处理诸如连接池、认证等复杂性。工具箱使您能够在集中位置定义工具,并在不到三行代码内与代理集成:
from toolbox_langchain import ToolboxClient
# 更新url以指向您的服务器
client = ToolboxClient("http://127.0.0.1:5000")
# 这些工具可以传递给您的代理!
tools = await client.aload_toolset()
工具箱是真正开源的:作为发布的组成部分,Google Cloud与其他数据库供应商(如Neo4j)合作,为大量开源和专有数据库构建支持:
- PostgresSQL(包括AloylDB和Cloud SQL for MySQL)
- MySQL(包括Cloud SQL for MySQL)
- SQL Server(包括Cloud SQL for SQL Server)
- Spanner
- Neo4j
3、使用工具箱访问Neo4j
安装完工具箱服务器后,就可以配置你的tools.yaml。要创建一个查询Neo4j的工具,你需要配置以下两件事:
一个Neo4j源,定义如何连接和认证到你的Neo4j实例。这是我们的示例的Neo4j源:
sources:
companies-graph:
kind: "neo4j"
uri: "neo4j+s://demo.neo4jlabs.com"
user: "companies"
password: "companies"
database: "companies"
定义好源之后,就是时候定义工具了。一个neo4j-cypher工具定义了当代理调用该工具时应运行的cypher查询。工具可以表达您可以在cypher语句中表达的任何内容——包括读取或写入!为了在代理设置中使用它,非常重要的是详细描述工具、参数和结果,以便LLM可以推理其适用性。
这是我们的示例工具配置的一部分,包括源、语句、描述和参数:
tools:
articles_in_month:
kind: neo4j-cypher
source: companies-graph
statement: |
MATCH (a:Article)
WHERE date($date) <= date(a.date) < date($date) + duration('P1M')
RETURN a.id as article_id, a.author as author, a.title as title, toString(a.date) as date, a.sentiment as sentiment
LIMIT 25
description: 给定日期月份范围内的文章列表(文章id、作者、标题、日期、情感)
parameters:
- name: date
type: string
description: 开始日期格式为yyyy-mm-dd
companies_in_articles:
kind: neo4j-cypher
source: companies-graph
statement: |
MATCH (a:Article)-[:MENTIONS]->(c)
WHERE a.id = $article_id AND not exists { (c)<-[:HAS_SUBSIDARY]-() }
RETURN c.id as company_id, c.name as name, c.summary as summary
description: 根据文章id查找文章中提到的公司(公司id、名称、摘要)
parameters:
- name: article_id
type: string
description: 查找文章中提到的公司的文章id
4、投资研究代理
这是一个带有使用GraphRAG模式结合全文和图形搜索的工具的代理LangChain应用程序演示。
该示例代表了一个投资研究代理,可用于查找关于公司、投资者、竞争对手、合作伙伴和行业的最新新闻。它由导入到Neo4j中的diffbot知识图谱提供动力。它通过基本实体集之间的关系捕捉领域的复杂性。
示例的代码可以在这个存储库中找到。
5、探索公共图形数据集
数据集是一个关于公司、相关行业、在公司工作或投资的人员以及报道这些公司的文章的图形。
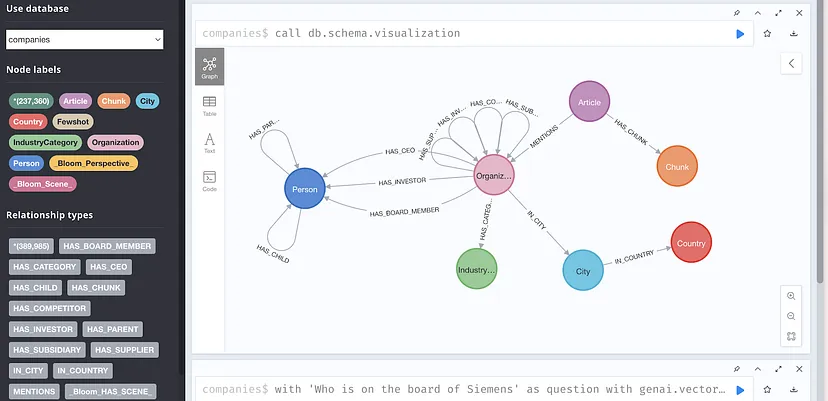
新闻文章被分块,块也存储在图形中。
数据库是公开可用的,具有只读用户,您可以通过以下URL探索数据:https://demo.neo4jlabs.com:7473/browser/
- URI: neo4j+s://demo.neo4jlabs.com
- 用户: companies
- 密码: companies
- 公司: companies
在我们的配置中,我们提供了利用全文索引以及获取以下附加信息的图形检索查询:
- 文章的父块(聚合单篇文章的所有块)
- 提到的组织
- 组织的行业类别
- 与组织相关的人员及其角色(例如,投资者、董事长、CEO)
我们利用了与Vertex AI的代理LangChain集成,这允许我们将注册的工具自动传递给LLM进行调用。我们将利用混合搜索以及GraphRAG检索器。
6、将我们的代理连接到工具箱
我们现在可以使用LangChain与Vertex AI Gemini 2.0 Flash模型,并将我们的工具定义传递给该模型并进行快速测试。我们可以遵循工具箱文档中的快速入门示例。
import asyncio
import os
from langgraph.prebuilt import create_react_agent
from langchain_google_vertexai import ChatVertexAI
from langgraph.checkpoint.memory import MemorySaver
from toolbox_langchain import ToolboxClient
prompt = """
你是一个有帮助的投资研究助手。
你可以使用提供的工具来搜索公司、公司里的人、行业以及2023年的新闻文章。
不要向用户请求确认。
用户:
"""
queries = [
"哪些行业涉及计算机制造?",
"列出5家计算机制造行业的公司及其描述。",
]
def main():
model = ChatVertexAI(model_name="gemini-1.5-pro")
client = ToolboxClient("http://127.0.0.1:5000")
tools = client.load_toolset()
agent = create_react_agent(model, tools, checkpointer=MemorySaver())
config = {"configurable": {"thread_id": "thread-1"}}
for query in queries:
inputs = {"messages": [("user", prompt + query)]}
response = agent.invoke(inputs, stream_mode="values", config=config)
print(response["messages"][-1].content)
main()
处理计算机制造的行业包括:计算机硬件公司、电子产品制造商和计算机存储公司。
以下是计算机硬件行业中五家公司及其描述:
1. **微软埃及分公司:** 微软在埃及的分公司
2. **Apigee:** 总部位于美国加利福尼亚州圣何塞的软件公司,由谷歌所有
3. **Microsemi:** 通信公司
4. **Intermec:** 美国电子制造公司
5. **精英集团电脑系统:** 没有摘要可用
7、示例对话
为代理提供工具以检查数据的不同方面,使其能够回答甚至复杂和后续的问题,如我们在下面的例子中所示。
2023年1月在新闻中提到的公司有哪些具有积极情绪?
这个问题需要调用多个工具并正确转换参数。我们提供了部分日期“2023年1月”,必须将其转换为yyyy-mm-dd格式才能调用工具。代理必须理解“良好情绪”指的是数值评分,并且需要对文章结果进行后过滤。然后这些文章需要分别输入到companies_in_article工具中以检索公司。
这是2023年1月具有积极情绪评分的文章,以及它们提到的公司:
Mozilla的Pocket应用刚刚获得重大更新(0.838, 0.83): Mozilla
Onapsis宣布与Wipro合作以消除安全作为数字转型障碍(0.804, 0.735): Onapsis, Wipro, SAP
……
谁在那里担任董事会成员?
这里我们引用了上一个问题中提到的公司,并且对API调用选择的要求也很模糊。代理需要多次调用people_at_company端点,使用之前在代理内存中检索到的公司ID,然后汇总和过滤信息以形成响应。
我没有能够获取所有公司的董事会成员信息。这是找到的信息:
Wipro:
- Azim Premji (BOARD_MEMBER)
- Rishad Premji (BOARD_MEMBER)
SAP:
- Hasso Plattner (BOARD_MEMBER)
- Jennifer Morgan (BOARD_MEMBER)
…
8、结束语
在这篇文章中,我们展示了如何构建可以轻松集成基于数据库的工具的自主应用程序。虽然我们专注于Neo4j知识图谱的GraphRAG用例,但可以在同一个自主应用程序中结合不同的数据源和类型的数据库。
由于Toolbox与不同的代理框架集成,你可以定义一次工具并在多个用例中重用。Neo4j发现贡献于Toolbox很容易,我们希望您会利用反馈和讨论机制添加自己的数据源并提供反馈和改进。
原文链接:Building AI Agents with Google’s Gen AI Toolbox and Neo4j Knowledge Graphs
汇智网翻译整理,转载请标明出处
