制作高质量的语音克隆数据集
本指南介绍了构建高质量的语音克隆数据集的全面过程,重点是提取有效语音克隆所必需的清晰准确的声音样本。

重要提示:本指南仅供符合道德规范的使用。请确保你拥有用于数据集创建的任何媒体的必要权限,并遵守适用的法律和准则。使用 YouTube-DL 等工具时,我们建议下载和处理你拥有所有权的内容(例如您自己的录音),以尊重他人的知识产权。语音克隆技术应始终以负责任的方式使用,并承诺保护隐私并尊重个人。
随着提供配音和类似人类对话声音的 AI 应用程序的兴起,人们对构建自定义文本转语音模型的兴趣日益浓厚。许多开发人员和公司试图通过微调自己的模型来避免付费配音服务的成本。然而,创建高质量文本转语音系统的第一步也是最关键的一步是获取丰富、准备充分的数据集。本指南介绍了构建此类数据集的全面过程,重点是提取有效语音克隆所必需的清晰准确的声音样本。
作为我项目的中间步骤,我正在努力建立一个可以无缝执行每个步骤的自动化管道。本指南提供了有关创建高质量数据集的详细演练,涵盖了从视频下载到音频转录的所有内容。最后,我将讨论在此过程中遇到的一些挑战。
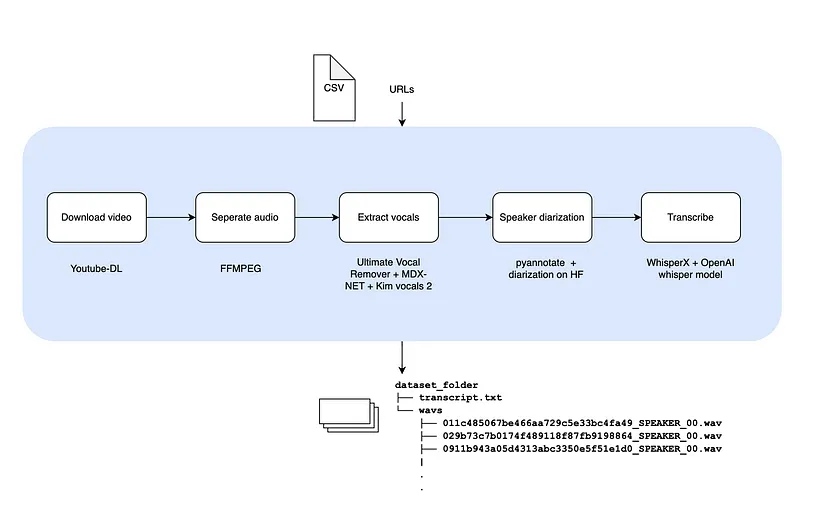
此工作流程使用 YouTube-DL、FFMPEG、WhisperX 等工具来确保提取的音频符合高质量机器学习模型的要求。让我们深入了解每个步骤以及帮助您入门的必要命令。
1、下载音频源
第一步是从 CSV 文件中提供的 URL 列表中下载视频。YouTube-DL 是一个简化此过程的命令行工具。它允许您下载高质量的视频并支持各种视频托管平台。
- 从 CSV 加载 URL:从 CSV 文件中提取 URL 列表。
- 运行 YouTube-DL:使用以下命令以最佳可用质量下载视频。
用法:
youtube-dl -f 'bestvideo[ext=mp4]+bestaudio[ext=m4a]/mp4' <URL>注意:从 2024 年 8 月开始,youtube-dl 要求你在从 AWS EC2 运行时使用 OAuth/Cookies 传递身份验证详细信息,因为 Google 对下载 T&C 非常严格,并将许多公共云提供商 IP 列入黑名单。
2、分离音视频
下载视频后,下一步是将音轨与视频文件分离。FFMPEG 是一个功能强大的工具,可以轻松提取和转换音频格式。将音频转换为 WAV 格式可确保与大多数机器学习框架兼容。
用法:
ffmpeg -i input_video.mp4 -q:a 0 -map a output_audio.wav在这里, -map a 隔离音轨, -q:a 0 保留音频质量。
3、提取人声
隔离音频后,下一步是专注于从音频中仅提取人声成分。背景音乐和噪音会干扰语音克隆。在从音轨中隔离人声方面,Ultimate Vocal Remover 是最佳选择之一。它利用先进的深度学习模型,包括 MDX-Net 和 Demucs,以最少的伪影实现高质量的人声分离。
Demucs 是 UVR 中强大的深度学习模型,使用卷积神经网络 (CNN) 实现跨各种音乐流派的准确和灵活的人声分离。MDX-Net 是一个可选模型,专门用于更精细的人声提取,在 Demucs 可能留下残留伪影的情况下提供更好的结果。UVR 还支持其他模型,例如 Ensemble 模式,您可以使用该模式组合多个模型以获得更好的质量结果。
使用:
UVR 的使用非常简单,它首先要求你选择以下任何一种处理方法:

然后在方法中选择任何特定的受支持模型。但是在使用之前,你必须从 UI 下载这些模型。以下是我按照有效语音提取的顺序推荐的方法+模型组合:
Ensemble -> Demucs-> MDX-Net + Kim vocals 2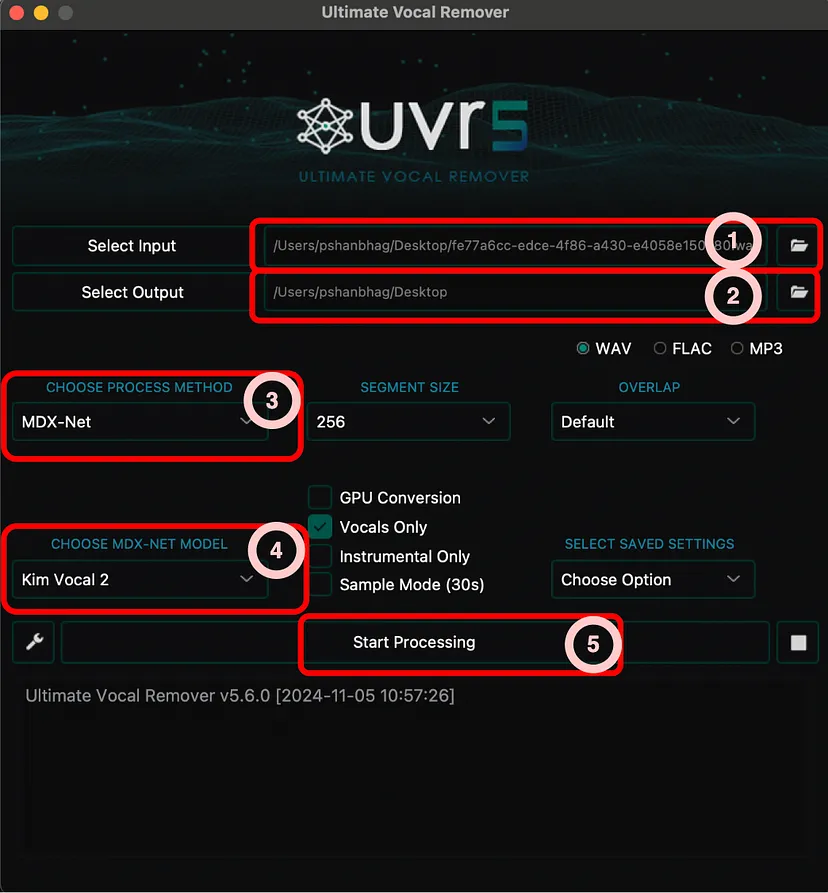
4、说话人分类
为了创建具有不同说话人标签的数据集,我们使用说话人分类。此过程按说话人识别和分割音频部分,这在处理多说话人数据时特别有用。 pyannotate.audio 在 Hugging face 上有高效的说话人分类模型,可以随时用于提取人声中的多个说话人。
用法:
from pyannote.audio import Pipeline
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization@2.1",
use_auth_token="ACCESS_TOKEN_GOES_HERE")
# apply the pipeline to an audio file
diarization = pipeline("audio.wav")
# dump the diarization output to disk using RTTM format
with open("audio.rttm", "w") as rttm:
diarization.write_rttm(rttm)请确保你生成 HF 访问令牌,并通过接受这个特定 repo 的 T&C 获得读取访问权限。如果没有这个,你将收到错误 此脚本将创建一个 .rttm 文件,其中包含每个说话者的时间段,稍后可用于按说话者标记音频片段。
或者,我们也可以使用 WhisperX 包装器中的 pyannotate 模型。我们还可以使用 WhisperX 准备音频文件的转录,如我们在下一步中看到的那样:
import whisperx
device = "cuda" # Use cpu if you are running on a GPU less machine
def convert_diarize_segments(diarize_segments_dict):
result = []
for segment in diarize_segments_dict:
result.append({
'start': segment["start"],
'end': segment["end"],
'label': segment["label"],
'speaker': segment["speaker"]
})
return result
def identify_speakers(audio_file:str, min_speakers=1, max_speakers=2):
device = "cuda" # Use cpu if you do not have GPU
audio = whisperx.load_audio(audio_file)
diarize_model = whisperx.DiarizationPipeline(
use_auth_token="ACCESS_TOKEN_GOES_HERE", device=device)
diarize_segments = diarize_model(
audio, min_speakers=min_speakers, max_speakers=max_speakers)
result_json = convert_diarize_segments(
diarize_segments.to_dict(orient='records')
return result_json
identify_speakers("<PATH_TO_AUDIO_WAV>", 1, 2)5、音频转录
最后,转录音频对于创建训练语音克隆模型所需的文本-音频对至关重要。WhisperX 建立在 OpenAI 的 Whisper 模型之上,即使对于具有挑战性的音频输入也能提供高质量的转录。您可以使用 large-v2 或 large-v3 模型来执行音频分析。
用法:
import whisperx
def get_transcript(audio_file):
device = os.environ.get("DEVICE")
batch_size = int(os.environ.get("BATCH_SIZE"))
compute_type = os.environ.get("COMPUTE_TYPE")
model_dir = os.environ.get("MODEL_DIR")
model = whisperx.load_model(
"large-v2", device, compute_type=compute_type, download_root=model_dir)
audio = whisperx.load_audio(audio_file)
transcript = model.transcribe(audio, batch_size=batch_size)
if os.environ.get("DELETE_MODEL_AFTER_USE"):
gc.collect()
torch.cuda.empty_cache()
del model
return transcript
get_transcript("<PATH_TO_AUDIO_WAV>")此转录本将包含每个转录的语音片段及其相应的时间戳。这对于将文本与音频片段配对至关重要。
6、最终输出:组织数据集
处理完所有文件后,我们可以将它们组织成一个结构化的数据集,然后可以将其传递给微调你自己的模型,例如 Coqui TTS。
dataset_folder/
├── transcript.txt
├── wavs/
│ ├── 011c485067be466aa729c5e33bc4fa49_SPEAKER_00.wav
│ ├── 029b73c7b0174f48911878fb9198864_SPEAKER_00.wav
│ └── 0911b943a05d4313abc3350e5f51e1d0_SPEAKER_00.wavwavs/包含每个说话者片段的单独音频文件,并标有唯一标识符。transcript.txt用作所有数据集数据的元数据
011c485067be466aa729c5e33bc4fa49_SPEAKER_00 | <transcripted text>
029b73c7b0174f48911878fb9198864_SPEAKER_00 | <transcripted text>
0911b943a05d4313abc3350e5f51e1d0_SPEAKER_00 | <transcripted text>
.
.7、大规模运行
虽然上述步骤可用于处理少量音频,但如果要提取大量音频文件,则需要构建一个可以处理大量文件的管道。以下是我在大规模执行此操作时遇到的一些挑战
- 访问 GPU — 虽然某些步骤 (1-2) 可以在普通 CPU 上运行,但要运行其他步骤,你需要获得 GPU。如果你有访问权限,可以在 RunPOD 上租用 GPU 或在 AWS 上生成 g4dn.* EC2 机器。最便宜的 EC2 机器每小时费用不到 1 美元。
- 环境设置 — 访问 GPU 是一回事,但配置机器以在上面运行又是另一回事。你需要首先安装兼容版本的 pytorch 和 Nvidia 驱动程序。然后获取适当的库和模型。如果你想快速进行一些 POC,RunPOD 机器可以提供帮助。RunPOD 上的一些配置随所有这些软件和驱动程序一起安装。关于 EC2 的说明,你可能需要提出特殊配额请求来生成 g4dn* 机器。默认情况下,它们是禁用的。
- 自定义 — 上述一些步骤涉及使用 UI(步骤 3)来完成任务。但是如果你想自动化它,那么需要在机器上运行原始模型。为此,你需要围绕此编写一些代码来设置管道。
8、结束语
通过遵循这些步骤,你可以创建一个适合语音克隆的结构化和高质量数据集。通过这种数据集准备方法,你将能够生成合成语音,
捕捉真实世界语音的细微差别,解锁个性化音频应用程序、虚拟助手等的可能性。
原文链接:Building High-Quality Voice Cloning Datasets for AI Applications
汇智网翻译整理,转载请标明出处
