用代理和工具构建个人助理
使用代理和工具,我们可以在聊天界面 从自己的文档中检索数据、阅读/发送电子邮件、与内部数据库交互等。

你有了你最喜欢的聊天机器人,你把它用于日常工作以提高你的工作效率。它可以翻译文本、写有趣的电子邮件、讲笑话等。然后有一天,你的同事来找你问:
“你知道美元和欧元之间的当前汇率吗?我想知道我是否应该卖掉我的欧元……”
你问你最喜欢的聊天机器人,答案是:
很抱歉,我无法满足这个要求。
我无法访问实时信息,包括汇率等财务数据。
这里的问题是什么?
问题是你偶然发现了 LLM 的一个缺点。大型语言模型 (LLM) 能够有效解决许多类型的问题,例如问题解决、文本摘要、生成等。
然而,它们受到以下限制:
- 它们在训练后被冻结,导致知识陈旧。
- 它们无法查询或修改外部数据。
就像我们每天使用搜索引擎、阅读书籍和文档或查询数据库一样,我们理想情况下希望将这些知识提供给我们的 LLM,以使其更有效率。
幸运的是,有一种方法可以做到这一点:工具和代理。
基础模型尽管具有令人印象深刻的文本和图像生成功能,但仍受到无法与外界交互的限制。工具弥补了这一差距,使代理能够与外部数据和服务交互,同时解锁了超出底层模型范围的更广泛的操作。(来源:Google Agents 白皮书)
使用代理和工具,我们可以在聊天界面:
- 从我们自己的文档中检索数据
- 阅读/发送电子邮件
- 与内部数据库交互
- 执行实时 Google 搜索
- 等等。
1、什么是代理、工具和链?
代理(Agent)是一种应用程序,它试图通过拥有一组工具并根据对环境的观察做出决策来实现目标(或任务)。
例如,你就是一个代理的很好例子:如果你需要计算复杂的数学运算(目标),则可以使用计算器(工具 1)或编程语言(工具 2)。也许你会选择计算器进行简单的加法运算,但对于更复杂的算法,则选择工具 2。
因此,代理由以下部分组成:
- 模型:代理中的大脑是 LLM。它将理解查询(目标),并浏览可用的工具以选择最佳工具。
- 一个或多个工具:这些是负责执行特定操作的函数或 API(即:检索美元兑欧元的当前汇率、添加数字等)。
- 编排过程:这是模型在被要求解决任务时的行为方式。这是一个认知过程,它定义了模型如何分析问题、改进输入、选择工具等。此类过程的示例包括 ReAct、CoT(思维链)、ToT(思维树)
下面是工作流程说明:
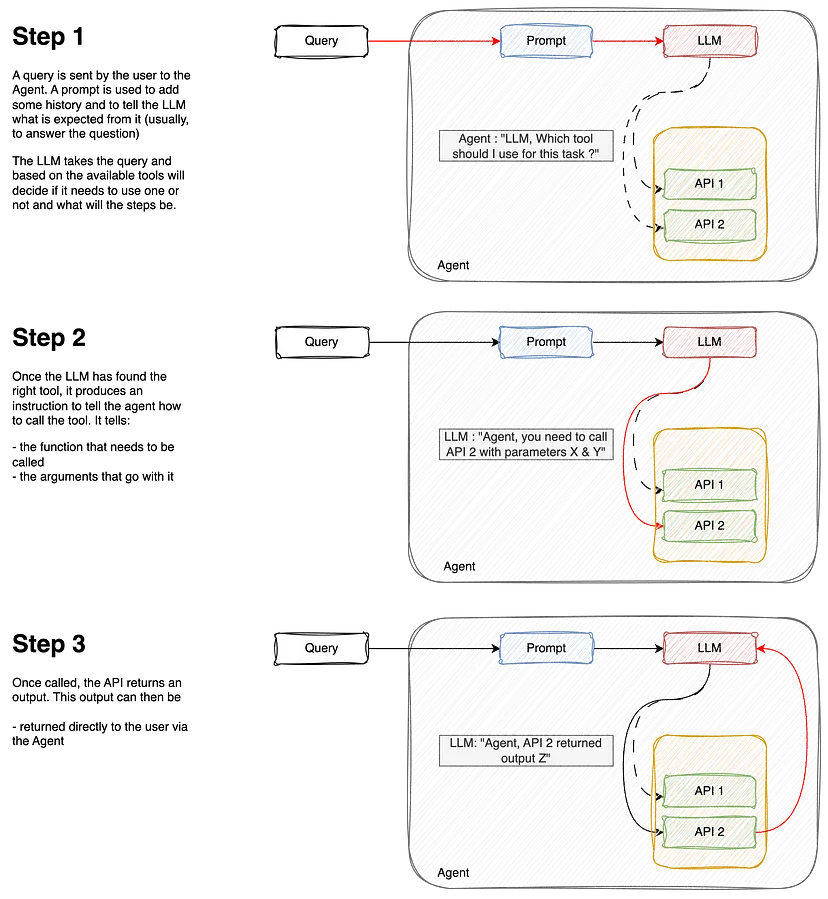
链(Chain)有些不同。虽然代理可以自己“决定”做什么和采取哪些步骤,但链只是一系列预定义的步骤。不过,它们仍然可以依赖工具,这意味着它们可以包括一个需要从可用工具中进行选择的步骤。我们稍后会介绍这一点。
2、创建没有工具的简单聊天
为了说明我们的观点,我们首先将看看我们的 LLM 在没有任何帮助的情况下的表现如何。
让我们安装所需的库:
vertexai==1.65.0
langchain==0.2.16
langchain-community==0.2.16
langchain-core==0.2.38
langchain-google-community==1.0.8
langchain-google-vertexai==1.0.6并使用 Google 的 Gemini LLM 创建非常简单的聊天:
from vertexai.generative_models import (
GenerativeModel,
GenerationConfig,
Part
)
gemini_model = GenerativeModel(
"gemini-1.5-flash",
generation_config=GenerationConfig(temperature=0),
)
chat = gemini_model.start_chat()如果运行这个简单的聊天并询问有关当前汇率的问题,可能会得到类似的答案:
response = chat.send_message("What is the current exchange rate for USD vs EUR ?")
answer = response.candidates[0].content.parts[0].text
--- OUTPUT ---
"I am sorry, I cannot fulfill this request. I do not have access to real-time information, including financial data like exchange rates."让我们为此添加一个工具。我们的工具将是调用 API 来实时检索汇率数据的小函数。
def get_exchange_rate_from_api(params):
url = f"https://api.frankfurter.app/latest?from={params['currency_from']}&to={params['currency_to']}"
print(url)
api_response = requests.get(url)
return api_response.text
# Try it out !
get_exchange_rate_from_api({'currency_from': 'USD', 'currency_to': 'EUR'})
---
'{"amount":1.0,"base":"USD","date":"2024-11-20","rates":{"EUR":0.94679}}'现在我们知道了我们的工具是如何工作的,我们想告诉我们的聊天 LLM 使用这个函数来回答我们的问题。因此,我们将创建一个单一工具代理。为此,我们有几个选项,我将在此列出:
- 使用 Google 的 Gemini 聊天 API 和函数调用
- 使用 LangChain 的 API 和代理和工具
两者各有优缺点。本文的目的也是展示各种可能性,让你决定自己更喜欢哪一种。
3、向聊天添加工具:Google 的函数调用
从函数创建工具基本上有两种方法。
第一种是“字典”方法,你可以在其中指定工具中的输入和函数描述。重要的参数是:
- 函数名称(明确)
- 描述:这里要详细,因为详尽的描述将有助于 LLM 选择正确的工具
- 参数:这是你指定参数(类型和描述)的地方。再次强调,在参数描述中要详细说明,以帮助 LLM 了解如何将值传递给你的函数
import requests
from vertexai.generative_models import FunctionDeclaration
get_exchange_rate_func = FunctionDeclaration(
name="get_exchange_rate",
description="Get the exchange rate for currencies between countries",
parameters={
"type": "object",
"properties": {
"currency_from": {
"type": "string",
"description": "The currency to convert from in ISO 4217 format"
},
"currency_to": {
"type": "string",
"description": "The currency to convert to in ISO 4217 format"
}
},
"required": [
"currency_from",
"currency_to",
]
},
)使用 Google SDK 添加工具的第二种方法是使用 from_func 实例。这需要编辑我们的原始函数,使其更加明确,并添加文档字符串等。我们不是冗长地创建工具,而是冗长地创建函数:
# Edit our function
def get_exchange_rate_from_api(currency_from: str, currency_to: str):
"""
Get the exchange rate for currencies
Args:
currency_from (str): The currency to convert from in ISO 4217 format
currency_to (str): The currency to convert to in ISO 4217 format
"""
url = f"https://api.frankfurter.app/latest?from={currency_from}&to={currency_to}"
api_response = requests.get(url)
return api_response.text
# Create the tool
get_exchange_rate_func = FunctionDeclaration.from_func(
get_exchange_rate_from_api
)下一步实际上是创建工具。为此,我们将 FunctionDeclaration 添加到列表中以创建 Tool 对象:
from vertexai.generative_models import Tool as VertexTool
tool = VertexTool(
function_declarations=[
get_exchange_rate_func,
# add more functions here !
]
)现在让我们将其传递给聊天,看看它现在是否可以回答我们关于汇率的查询!请记住,如果没有工具,我们的聊天会回答:

让我们尝试 Google 的函数调用工具,看看这是否有帮助!首先,让我们将查询发送到聊天:
from vertexai.generative_models import GenerativeModel
gemini_model = GenerativeModel(
"gemini-1.5-flash",
generation_config=GenerationConfig(temperature=0),
tools=[tool] #We add the tool here !
)
chat = gemini_model.start_chat()
response = chat.send_message(prompt)
# Extract the function call response
response.candidates[0].content.parts[0].function_call
--- OUTPUT ---
"""
name: "get_exchange_rate"
args {
fields {
key: "currency_to"
value {
string_value: "EUR"
}
}
fields {
key: "currency_from"
value {
string_value: "USD"
}
}
fields {
key: "currency_date"
value {
string_value: "latest"
}
}
}"""LLM 正确猜测到需要使用 get_exchange_rate 函数,也正确猜测到 2 个参数是 USD 和 EUR 。
但这还不够。我们现在想要的是实际运行这个函数来得到结果!
# mapping dictionnary to map function names and function
function_handler = {
"get_exchange_rate": get_exchange_rate_from_api,
}
# Extract the function call name
function_name = function_call.name
print("#### Predicted function name")
print(function_name, "\n")
# Extract the function call parameters
params = {key: value for key, value in function_call.args.items()}
print("#### Predicted function parameters")
print(params, "\n")
function_api_response = function_handler[function_name](params)
print("#### API response")
print(function_api_response)
response = chat.send_message(
Part.from_function_response(
name=function_name,
response={"content": function_api_response},
),
)
print("\n#### Final Answer")
print(response.candidates[0].content.parts[0].text)
--- OUTPUT ---
"""
#### Predicted function name
get_exchange_rate
#### Predicted function parameters
{'currency_from': 'USD', 'currency_date': 'latest', 'currency_to': 'EUR'}
#### API response
{"amount":1.0,"base":"USD","date":"2024-11-20","rates":{"EUR":0.94679}}
#### Final Answer
The current exchange rate for USD vs EUR is 0.94679. This means that 1 USD is equal to 0.94679 EUR.
"""我们现在可以看到我们的聊天能够回答我们的问题!它:
- 正确猜测要调用的函数
get_exchange_rate - 正确分配调用函数的参数
{‘currency_from’: ‘USD’, ‘currency_to’: ‘EUR’} - 从 API 获得结果
- 并将答案格式化为人类可读!
现在让我们看看使用 LangChain 的另一种方式。
4、向聊天添加工具:使用 Langchain代理
LangChain 是一个使用 LLM 构建的可组合框架。它是可控制代理工作流的编排框架。
与我们之前使用“Google”方式所做的类似,我们将以 Langchain 方式构建工具。让我们从定义函数开始。与 Google 一样,我们需要在文档字符串中详尽而详细:
from langchain_core.tools import tool
@tool
def get_exchange_rate_from_api(currency_from: str, currency_to: str) -> str:
"""
Return the exchange rate between currencies
Args:
currency_from: str
currency_to: str
"""
url = f"https://api.frankfurter.app/latest?from={currency_from}&to={currency_to}"
api_response = requests.get(url)
return api_response.text为了增加趣味性,我将添加另一个可以列出 BigQuery 数据集中的表格的工具。代码如下:
@tool
def list_tables(project: str, dataset_id: str) -> list:
"""
Return a list of Bigquery tables
Args:
project: GCP project id
dataset_id: ID of the dataset
"""
client = bigquery.Client(project=project)
try:
response = client.list_tables(dataset_id)
return [table.table_id for table in response]
except Exception as e:
return f"The dataset {params['dataset_id']} is not found in the {params['project']} project, please specify the dataset and project"添加完成后,我们将函数添加到 LangChain 工具箱中!
langchain_tool = [
list_tables,
get_exchange_rate_from_api
]为了构建我们的代理,我们将使用 LangChain 中的 AgentExecutorobject。这个对象基本上包含 3 个组件,也就是我们之前定义的组件:
- LLM
- 提示
- 和工具。
首先,我们选择我们的 LLM:
gemini_llm = ChatVertexAI(model="gemini-1.5-flash")然后,我们创建一个提示来管理对话:
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful assistant"),
("human", "{input}"),
# Placeholders fill up a **list** of messages
("placeholder", "{agent_scratchpad}"),
]
)最后,我们创建 AgentExecutor 并运行查询:
agent = create_tool_calling_agent(gemini_llm, langchain_tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=langchain_tools)
agent_executor.invoke({
"input": "Which tables are available in the thelook_ecommerce dataset ?"
})
--- OUTPUT ---
"""
{'input': 'Which tables are available in the thelook_ecommerce dataset ?',
'output': 'The dataset `thelook_ecommerce` is not found in the `gcp-project-id` project.
Please specify the correct dataset and project. \n'}
"""嗯。似乎代理缺少一个参数,或者至少要求提供更多信息……让我们通过提供以下信息来回复:
agent_executor.invoke({"input": f"Project id is bigquery-public-data"})
--- OUPTUT ---
"""
{'input': 'Project id is bigquery-public-data',
'output': 'OK. What else can I do for you? \n'}
"""好吧,似乎我们又回到了原点。 LLM 已被告知项目 ID,但忘记了问题。我们的代理似乎缺乏记忆来记住以前的问题和答案。也许我们应该考虑……
5、为我们的代理添加内存
内存是代理中的另一个概念,它基本上可以帮助系统记住对话历史并避免像上面那样的无限循环。将内存想象成一个记事本,LLM 在其中跟踪以前的问题和答案以围绕对话构建上下文。
我们将修改模型中的提示(指令)以包含内存:
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
# Different types of memory can be found in Langchain
memory = InMemoryChatMessageHistory(session_id="foo")
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful assistant."),
# First put the history
("placeholder", "{chat_history}"),
# Then the new input
("human", "{input}"),
# Finally the scratchpad
("placeholder", "{agent_scratchpad}"),
]
)
# Remains unchanged
agent = create_tool_calling_agent(gemini_llm, langchain_tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=langchain_tools)
# We add the memory part and the chat history
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: memory, #<-- NEW
input_messages_key="input",
history_messages_key="chat_history", #<-- NEW
)
config = {"configurable": {"session_id": "foo"}}我们现在从头开始重新运行查询:
agent_with_chat_history.invoke({
"input": "Which tables are available in the thelook_ecommerce dataset ?"
},
config
)
--- OUTPUT ---
"""
{'input': 'Which tables are available in the thelook_ecommerce dataset ?',
'chat_history': [],
'output': 'The dataset `thelook_ecommerce` is not found in the `gcp-project-id` project. Please specify the correct dataset and project. \n'}
"""聊天记录为空时,模型仍会要求输入项目 ID。与我们之前使用的无记忆代理非常一致。让我们回复代理并添加缺失的信息:
reply = "Project id is bigquery-public-data"
agent_with_chat_history.invoke({"input": reply}, config)
--- OUTPUT ---
"""
{'input': 'Project id is bigquery-public-data',
'chat_history': [HumanMessage(content='Which tables are available in the thelook_ecommerce dataset ?'),
AIMessage(content='The dataset `thelook_ecommerce` is not found in the `gcp-project-id` project. Please specify the correct dataset and project. \n')],
'output': 'The following tables are available in the `thelook_ecommerce` dataset:\n- distribution_centers\n- events\n- inventory_items\n- order_items\n- orders\n- products\n- users \n'}
"""请注意输出中的内容:
- 聊天历史记录 跟踪之前的问答
- 输出现在返回表格列表!
'output': 'The following tables are available in the `thelook_ecommerce` dataset:\n- distribution_centers\n- events\n- inventory_items\n- order_items\n- orders\n- products\n- users \n'}但是,在某些用例中,某些操作可能因其性质而需要特别注意(例如删除数据库中的条目、编辑信息、发送电子邮件等)。完全自动化而不受控制可能会导致代理做出错误决定并造成损害的情况。
保护我们工作流程的一种方法是添加人机交互步骤。
6、创建具有人工验证步骤的链
链与代理有所不同。代理可以决定使用或不使用工具,而链则更为静态。它是一系列步骤,我们仍然可以在其中添加一个步骤,LLM 将从一组工具中进行选择。
要在 LangChain 中构建链,我们使用 LCEL。
LangChain 表达式语言 (LCEL) 是一种声明性方式,可轻松组合链。 LangChain 中的链使用管道 |步骤 1 | 步骤 2 | 步骤 3 等。与代理的不同之处在于,链将始终遵循这些步骤,而代理可以自行“决定”,并在决策过程中保持自主。
在我们的例子中,我们将按如下方式构建一个简单的 prompt | llm 链:
# define the prompt with memory
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful assistant."),
# First put the history
("placeholder", "{chat_history}"),
# Then the new input
("human", "{input}"),
# Finally the scratchpad
("placeholder", "{agent_scratchpad}"),
]
)
# bind the tools to the LLM
gemini_with_tools = gemini_llm.bind_tools(langchain_tool)
# build the chain
chain = prompt | gemini_with_tools还记得我们在上一步中将代理传递给我们的 RunnableWithMessageHistory 吗?好吧,我们在这里做同样的事情,但是...
# With AgentExecutor
# agent = create_tool_calling_agent(gemini_llm, langchain_tool, prompt)
# agent_executor = AgentExecutor(agent=agent, tools=langchain_tool)
# agent_with_chat_history = RunnableWithMessageHistory(
# agent_executor,
# lambda session_id: memory,
# input_messages_key="input",
# history_messages_key="chat_history",
# )
config = {"configurable": {"session_id": "foo"}}
# With Chains
memory = InMemoryChatMessageHistory(session_id="foo")
chain_with_history = RunnableWithMessageHistory(
chain,
lambda session_id: memory,
input_messages_key="input",
history_messages_key="chat_history",
)
response = chain_with_history.invoke(
{"input": "What is the current CHF EUR exchange rate ?"}, config)
--- OUTPUT
"""
content='',
additional_kwargs={
'function_call': {
'name': 'get_exchange_rate_from_api',
'arguments': '{"currency_from": "CHF", "currency_to": "EUR"}'
}
}
"""与代理不同,除非我们告诉它,否则链不会提供答案。在我们的例子中,它停止在 LLM 返回需要调用的函数的步骤。
我们需要添加一个额外的步骤来实际调用该工具。让我们添加另一个函数来调用工具:
from langchain_core.messages import AIMessage
def call_tools(msg: AIMessage) -> list[dict]:
"""Simple sequential tool calling helper."""
tool_map = {tool.name: tool for tool in langchain_tool}
tool_calls = msg.tool_calls.copy()
for tool_call in tool_calls:
tool_call["output"] = tool_map[tool_call["name"]].invoke(tool_call["args"])
return tool_calls
chain = prompt | gemini_with_tools | call_tools #<-- Extra step
chain_with_history = RunnableWithMessageHistory(
chain,
lambda session_id: memory,
input_messages_key="input",
history_messages_key="chat_history",
)
# Rerun the chain
chain_with_history.invoke({"input": "What is the current CHF EUR exchange rate ?"}, config)我们现在得到以下输出,显示 API 已成功调用:
[{'name': 'get_exchange_rate_from_api',
'args': {'currency_from': 'CHF', 'currency_to': 'EUR'},
'id': '81bc85ea-dfd4-4c01-85e8-f3ca592fff5b',
'type': 'tool_call',
'output': '{"amount":1.0,"base":"USD","date":"2024-11-20","rates":{"EUR":0.94679}}'
}]现在我们了解了如何链接步骤,让我们添加人机交互步骤!我们希望这一步检查 LLM 是否理解了我们的请求并将正确调用 API。如果 LLM 误解了请求或错误地使用了该功能,我们可以决定中断该过程:
def human_approval(msg: AIMessage) -> AIMessage:
"""Responsible for passing through its input or raising an exception.
Args:
msg: output from the chat model
Returns:
msg: original output from the msg
"""
for tool_call in msg.tool_calls:
print(f"I want to use function [{tool_call.get('name')}] with the following parameters :")
for k,v in tool_call.get('args').items():
print(" {} = {}".format(k, v))
print("")
input_msg = (
f"Do you approve (Y|y)?\n\n"
">>>"
)
resp = input(input_msg)
if resp.lower() not in ("yes", "y"):
raise NotApproved(f"Tool invocations not approved:\n\n{tool_strs}")
return msg接下来,在函数调用之前将此步骤添加到链中:
chain = prompt | gemini_with_tools | human_approval | call_tools
memory = InMemoryChatMessageHistory(session_id="foo")
chain_with_history = RunnableWithMessageHistory(
chain,
lambda session_id: memory,
input_messages_key="input",
history_messages_key="chat_history",
)
chain_with_history.invoke({"input": "What is the current CHF EUR exchange rate ?"}, config)然后,系统会要求你确认 LLM 是否正确理解:

此人机交互步骤对于关键工作流程非常有用,因为 LLM 的误解可能会产生严重后果。
7、使用搜索工具
搜索引擎是实时检索信息最方便的工具之一。一种方法是使用 GoogleSerperAPIWrapper(你需要注册以获取 API 密钥才能使用它),它提供了一个不错的界面来查询 Google 搜索并快速获得结果。
幸运的是,LangChain 已经为你提供了一个工具,因此我们不必自己编写该函数。
因此,让我们尝试就昨天的活动(11 月 20 日)提出一个问题,看看我们的代理是否可以回答。我们的问题是关于拉斐尔·纳达尔的最后一场正式比赛(他输给了范德赞德舒尔普):
agent_with_chat_history.invoke(
{"input": "What was the result of Rafael Nadal's latest game ?"}, config)
--- OUTPUT ---
"""
{'input': "What was the result of Rafael Nadal's latest game ?",
'chat_history': [],
'output': "I do not have access to real-time information, including sports results. To get the latest information on Rafael Nadal's game, I recommend checking a reliable sports website or news source. \n"}
"""如果无法访问 Google 搜索,我们的模型无法回答,因为在训练时无法获得这些信息。
现在让我们将 Serper 工具添加到我们的工具箱中,看看我们的模型是否可以使用 Google 搜索来查找信息:
from langchain_community.utilities import GoogleSerperAPIWrapper
# Create our new search tool here
search = GoogleSerperAPIWrapper(serper_api_key="...")
@tool
def google_search(query: str):
"""
Perform a search on Google
Args:
query: the information to be retrieved with google search
"""
return search.run(query)
# Add it to our existing tools
langchain_tool = [
list_datasets,
list_tables,
get_exchange_rate_from_api,
google_search
]
# Create agent
agent = create_tool_calling_agent(gemini_llm, langchain_tool, prompt)
agent_executor = AgentExecutor(agent=agent, tools=langchain_tool)
# Add memory
memory = InMemoryChatMessageHistory()
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: memory,
input_messages_key="input",
history_messages_key="chat_history",
)并重新运行我们的查询:
agent_with_chat_history.invoke({"input": "What was the result of Rafael Nadal's latest game ?"}, config)
--- OUTPUT ---
"""
{'input': "What was the result of Rafael Nadal's latest game ?",
'chat_history': [],
'output': "Rafael Nadal's last match was a loss to Botic van de Zandschulp in the Davis Cup. Spain was eliminated by the Netherlands. \n"}
"""8、结束语
当涉及到使用个人、公司、私人或真实数据时,LLM 本身往往会遇到障碍。事实上,这些信息通常在训练时不可用。代理和工具是增强这些模型的有效方法,允许它们与系统和 API 交互,并协调工作流程以提高生产力。
原文链接:Build your Personal Assistant with Agents and Tools
汇智网翻译整理,转载请标明出处
