用Scikit-learn文档构建RAG
你可能会认为这只是另一篇关于如何“简单”构建检索增强生成(RAG)系统的博客文章。希望不是这样:我们在这里提供了一个不同的视角,特别关注用户面临的问题,而不是仅仅聚焦于其他博客文章中已经讨论的技术和工程组件。
你可能会认为这只是另一篇关于如何“简单”构建检索增强生成(RAG)系统的博客文章。希望不是这样:我们在这里提供了一个不同的视角,特别关注用户面临的问题,而不是仅仅聚焦于其他博客文章中已经讨论的技术和工程组件。
让我们首先概述撰写这篇博客的动机。
1、动机
1.1 丰富的文档及其主要缺点
如果你是scikit-learn用户,你会每天与scikit-learn文档网站交互。scikit-learn的文档无疑是这个开源项目的一大优势。从项目开始,就特别注重文档编写,就像代码编写一样:重点是始终为技术或理论方面提供高层次的直觉和见解。因此,文档以多种形式呈现:应用程序编程接口(API)文档、深入叙述性文档以介绍数学和方法论方面,以及丰富的使用示例画廊。
然而,这种丰富的文档对scikit-learn用户,尤其是新用户来说,带来了挑战:找到所需信息变得危险且迅速令人不知所措。虽然解决这个问题的真正办法是对文档进行尽可能好的分类,但提供在文档内搜索的工具是一个有用的补充。实际上,生态系统中的所有科学Python包(NumPy、SciPy、Pandas等)在其网站上都包含一个搜索栏,用于此目的。
1.2 搜索栏:次优的用户体验
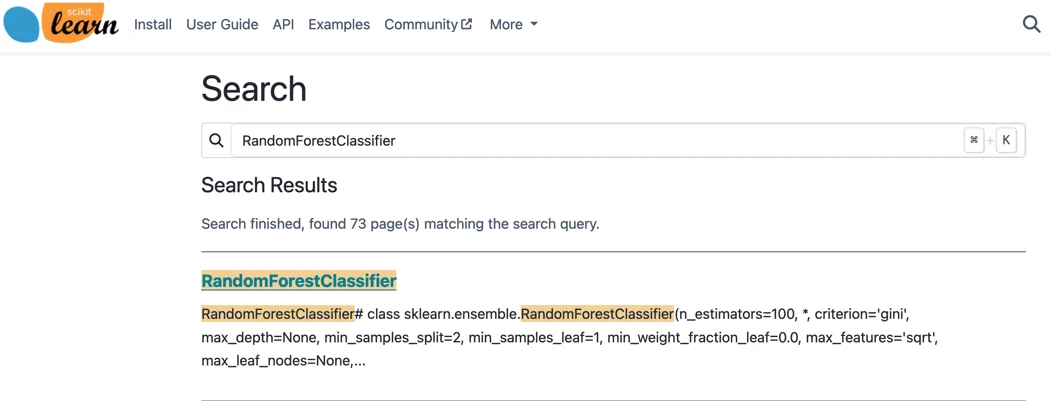
这一功能由Sphinx包启用,该包构建了一个索引,允许进行一些精确的搜索匹配。例如,我们可以搜索scikit-learn中关于随机森林分类器的信息。
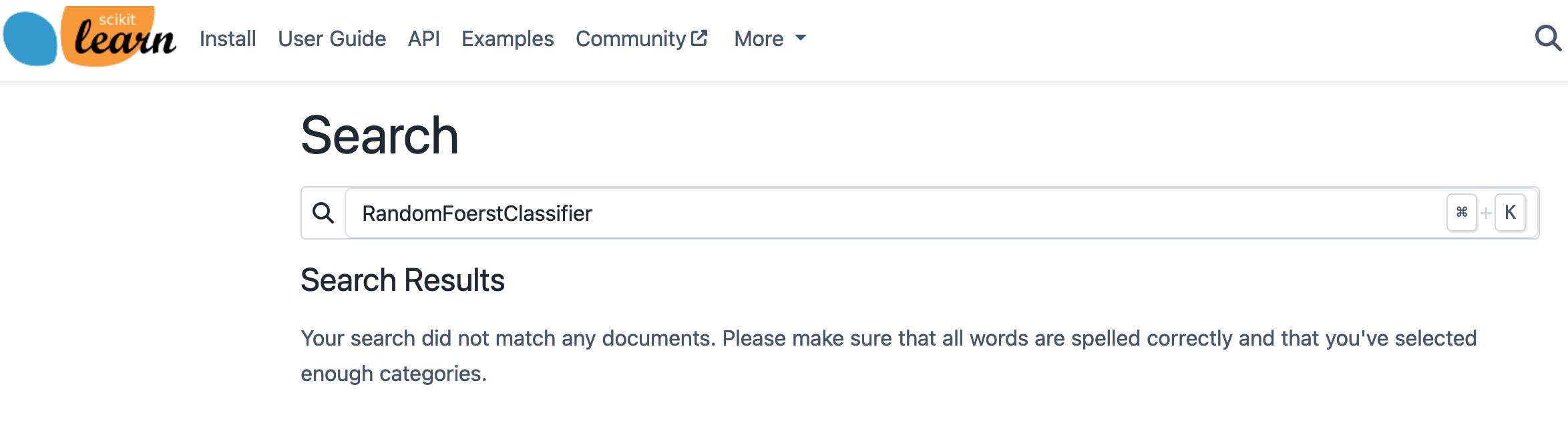
虽然这个功能已经有所帮助,但在以下情况下它会失效:(i) 它不能很好地处理拼写错误,(ii) 也不能很好地处理同义词,(iii) 它并不是为自然语言查询设计的。我们在以下示例中说明了这一点:
1.3 在社区约束下原型化RAG系统
2023年12月,我们采用了新的pydata-sphinx-theme,并对可能缓解上述问题的解决方案感兴趣。在同一时期,大型语言模型(LLMs)以及更具体地说,RAG系统变得非常流行。像任何热门技术一样,RAG系统当时被吹嘘为解决任何信息检索任务的灵丹妙药。因此,我们对原型化一个RAG系统来查询scikit-learn文档产生了兴趣,但受到我们开源社区工作的约束:
- 目前,在查询过程中不会收集用户的个人信息。即使这些信息可能不被视为敏感信息,我们也不想收集和管理任何用户的个人信息。
- 我们的RAG系统应该仅基于开源库和开放权重模型。如果我们通过API向第三方应用程序提供用户数据,我们将依赖他们的服务条款和潜在的未来变化。开源库和开放权重模型允许我们控制用户数据的使用。
- 作为一个基于社区的项目,我们在财务资源方面有限。因此,我们应该评估提供这项搜索服务的成本。
在本文的其余部分,我们首先解释什么是RAG系统。然后,我们将深入探讨实现每个RAG组件的见解。最后,我们将讨论这种方法在我们的特定开源社区背景下的不足之处。
2、RAG管道概述
2.1 改进的搜索栏
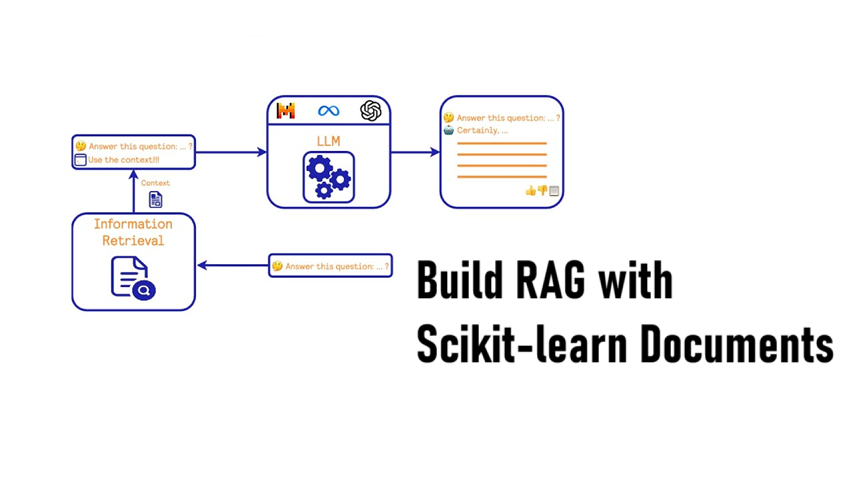
在详细介绍RAG管道之前,重要的是回顾一下在我们情境下的用户期望和体验。如前所述,我们将我们的提议视为“改进的搜索栏”,在这种情况下,我们可以将交互表示如下:
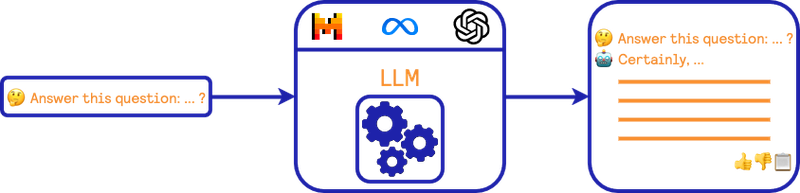
我们希望用户能够提出自然语言查询。这个查询会被提供给LLM模型(例如Mistral、Llama、GPT-4等),然后模型为用户提供答案。在这种情况下,我们不想提供来回对话代理。这种方式使用LLM也被称为“零样本提示”。
2.2 来源检查的不可能性
在这种零样本提示场景中,如果训练模型的数据允许其回答查询,那么LLM提供的答案可能是合理质量的。然而,获得支持答案的来源几乎是不可能的。在另一种更糟糕的情况下,即LLM未经过包含查询答案的数据训练时,模型可能会产生幻觉(注意,这种情况有时甚至会在训练良好的模型中发生)。由于没有提供来源以验证模型的答案,情况变得更加复杂。
2.3 带有可信来源的框架答案
减轻这个问题的一种潜在方法是在管道中添加一个可信的信息来源,这通常被称为RAG。我们以以下方式描绘RAG管道:
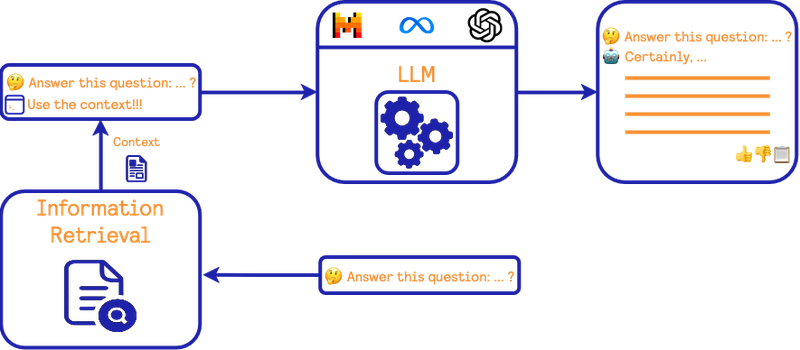
它与前面提到的零样本提示场景非常相似。然而,在查询回答过程上游增加了一个信息检索步骤。这个步骤的目标是从可信来源中找到与查询相关的信息,然后请求LLM使用这个可信信息(以及隐式的自身知识)回答用户的查询。这样的框架可能限制模型的幻觉,并为用户提供一些信息来源以验证答案。
3、深入分析RAG块
3.1 信息检索块
虽然LLM的零样本提示很简单,但RAG系统增加了信息检索步骤。这里我们更详细地讨论这个主题。信息检索在过去几十年里一直是研究和行业关注的重点。让我们在我们的上下文中讨论这个任务的原则:
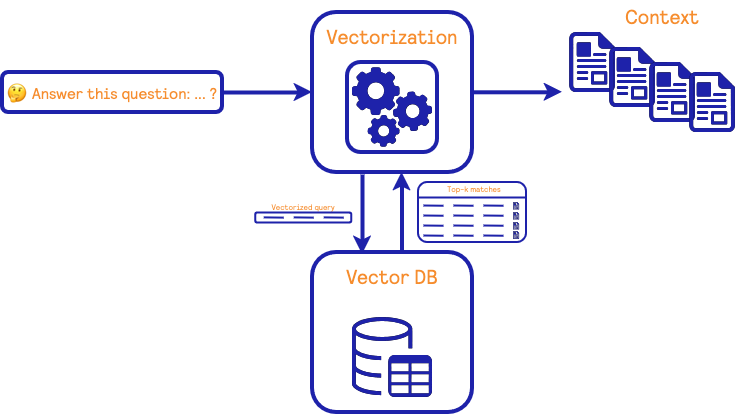
信息检索块有两个主要组成部分:(i) 将自然文本转换为数学向量表示的算法和(ii) 包含向量及其对应自然文本的数据库。该数据库还能够找到与给定查询向量最相似的向量。
在训练阶段,使用包含自然文本的源数据构建一组向量表示。这些向量用于填充数据库。在检索阶段,用户的查询被传递给算法以创建一个向量表示。然后在数据库中找到最相似的向量,并返回相应的自然文本。这些文档随后在RAG系统中用作LLM的上下文。
在更详细地讨论向量化和查找更接近向量的算法之前,我们首先需要深入了解我们上下文中“文档”的定义及其实际影响。
3.2 我们上下文中的文档
在我们的上下文中,我们定义文档为与回答用户查询相关的文档的一部分。这部分文档通常称为“片段”。需要注意的是,我们不能在整个文档页面作为LLM查询的上下文,因为根据构造,上下文的长度限制为一定数量的标记。在互联网上可以找到的一些教程中,基本的分块策略经常被宣传并如下图所示:

基本策略包括将文档分成重叠的片段。在信息检索上下文中,目标是找到与用户查询最相关的片段。这些片段随后提供给LLM以回答查询。然而,这种分块策略在处理不同类型的文档时往往不是最优的。
3.3 垃圾片段输入,垃圾答案输出
为了说明与分块策略相关的缺陷,让我们考虑DummyClassifier的API文档,如下所示:
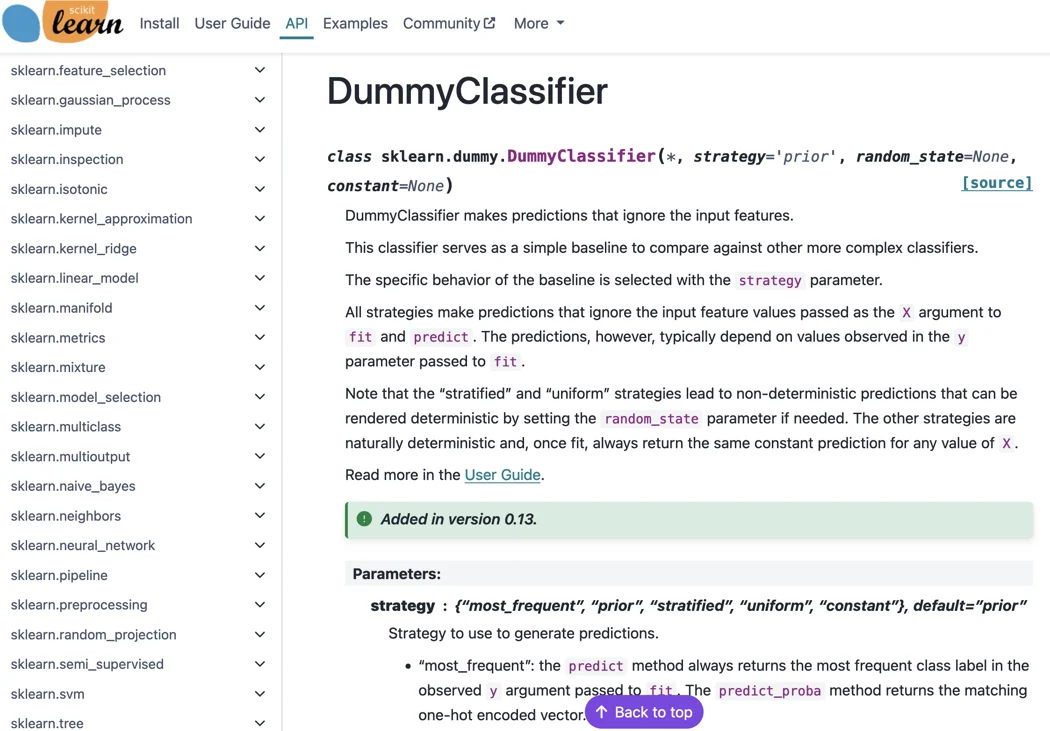
这种类型的文档可以用来回答有关参数、其可能值、类型等问题。例如,对于DummyClassifier,可以提出以下问题:“策略参数在虚拟分类器中的值是什么?"
对于这个查询,一个信息检索系统可能会得到以下片段。

所有片段都匹配“strategy”关键词,但不幸的是,该关键词也出现在多个scikit-learn估计器的文档中。使用基本的分块策略时,这些片段没有保留与估计器相关的上下文信息。向LLM提供这些片段会增加一层模糊性,并影响答案。例如,使用Mistral 7b模型回答此问题并结合上述上下文,结果如下:
"scikit-learn中的虚拟分类器并没有与生成预测相关的策略参数。相反,它具有处理拟合期间缺失值的参数(选项为"mean"、"median"、"most_frequent"或"constant")。因此,虚拟分类器中没有特定的策略参数值用于预测策略,如您在查询中提到的那样。"
显然,LLM的回答是错误的,但我们理解模型提供了上下文的摘要。这表明我们在创建分块时需要特别注意。在这个例子中,提供与参数相关的估计器名称有助于消除歧义。
3.4 分块策略
在本节中,我们将描述用于三种不同类型的文档的三种不同的分块策略。
API文档
API文档是从Python类和函数的docstring自动生成的。我们以scikit-learn代码库中的一个示例docstring为例,即extract_patches_2d函数的docstring。
def extract_patches_2d(image, patch_size):
"""Reshape a 2D image into a collection of patches.
The resulting patches are allocated in a dedicated array.
Read more in the :ref:`User Guide <image_feature_extraction>`.
Parameters
----------
image : ndarray of shape (image_height, image_width) or \
(image_height, image_width, n_channels)
The original image data. For color images, the last dimension specifies
the channel: a RGB image would have `n_channels=3`.
patch_size : tuple of int (patch_height, patch_width)
The dimensions of one patch.
Returns
-------
patches : array of shape (n_patches, patch_height, patch_width) or \
(n_patches, patch_height, patch_width, n_channels)
The collection of patches extracted from the image, where `n_patches`
is either `max_patches` or the total number of patches that can be
extracted.
Examples
--------
>>> from sklearn.datasets import load_sample_image
>>> from sklearn.feature_extraction import image
>>> # Use the array data from the first image in this dataset:
>>> one_image = load_sample_image("china.jpg")
>>> print('Image shape: {}'.format(one_image.shape))
Image shape: (427, 640, 3)
>>> patches = image.extract_patches_2d(one_image, (2, 2))
>>> print('Patches shape: {}'.format(patches.shape))
Patches shape: (272214, 2, 2, 3)
"""scikit-learn中的docstrings遵循numpydoc标准来指定参数、类型、示例等。好消息是,我们可以利用numpydoc,它实现了一个docstring解析器,可以返回一个结构化的Python字典,其中包含docstring中的信息。因此,我们可以识别参数及其关联的类型和描述等。
因此,我们制定了一项政策,将这些信息转换为自然语言句子,我们的LLM更擅长处理这些句子。我们提供了从extract_2d_patches的docstring自动生成的三个分块示例:
sklearn.feature_extraction.image.extract_patches_2d
The parameters of extract_patches_2d with their default values when known are:
image, patch_size.
The description of the extract_patches_2d is as follow.
Reshape a 2D image into a collection of patches.
The resulting patches are allocated in a dedicated array.
Read more in the :ref:`User Guide <image_feature_extraction>`.Parameter image of sklearn.feature_extraction.image.extract_patches_2d.
image is described as 'The original image data. For color images, the last dimension
specifies
the channel: a RGB image would have `n_channels=3`.' and has the following type(s):
ndarray of shape (image_height, image_width) or
(image_height, image_width, n_channels)sklearn.feature_extraction.image.extract_patches_2d
Here is a usage example of extract_patches_2d:
>>> from sklearn.datasets import load_sample_image
>>> from sklearn.feature_extraction import image
>>> # Use the array data from the first image in this dataset:
>>> one_image = load_sample_image("china.jpg")
>>> print('Image shape: {}'.format(one_image.shape))
Image shape: (427, 640, 3)
>>> patches = image.extract_patches_2d(one_image, (2, 2))
>>> print('Patches shape: {}'.format(patches.shape))
Patches shape: (272214, 2, 2, 3)
对于每个分块,我们添加了相关的Python模块或类,以解决我们之前展示的歧义问题。
示例文档
scikit-learn中的示例画廊依赖于另一个Python包:sphinx-gallery。同样地,我们利用了sphinx-gallery的示例抓取器。在scikit-learn中,我们有两种类型的示例:一些简单的用法示例和一些教程示例。
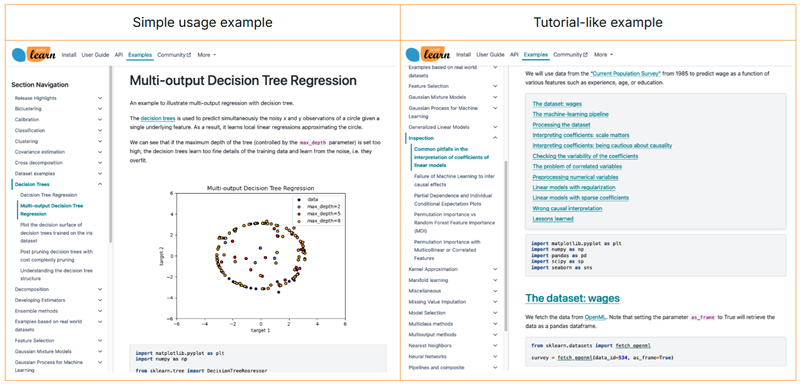
简单的用法示例(左图)由标题和相对较短的描述组成,随后是一个通常生成描述中讨论内容的代码片段。类似教程的示例(右图)更为复杂:它们被组织成分节,其中文本块和代码块交错。
因此,我们使用不同的策略来创建分块。对于用法示例,我们为文本创建一个块,为代码创建另一个块。然后,我们独立地对每个块进行分块。对于类似教程的示例,我们首先检测教程中的部分,这些部分包含文本和代码。由于同一部分内的文本和代码通常是相关的,我们不会拆分它们,而是只对整个块进行分块。
用户指南文档
最后,我们有用户指南文档。对于这种类型的文档,我们使用了朴素的分块方法。由于我们只是想做一个原型,这是一个很好的初步尝试。我们可以通过仅按章节分块并确保每个分块开头都回忆目录来改进分块策略,从而提供更多上下文。
3.5 信息检索搜索
到目前为止,我们主要关注的是我们希望用作LLM上下文的数据。在本节中,我们将详细介绍用于查找相关文档的方法,这些文档将作为LLM的上下文。如前所述,信息检索在研究和工业界都受到了广泛关注。简要总结一下,当前最先进的方法可以分为两类:基于术语频率的经典方法和基于神经网络的机器学习方法。Guo等人发表的这篇综述对当前最先进的方法进行了深入报告。在这里,我们简要介绍我们使用的两种方法。
经典基于术语的方法
在经典的基于术语的方法中,核心思想是计算文档中的词频。属于同一主题的文档预计具有相似的术语频率。这一领域的流行概念被称为Tf-IDF术语加权,一种利用这一概念查找相关文档的方法是BM25。下面,我们展示了使用此算法查找相似文档的过程。
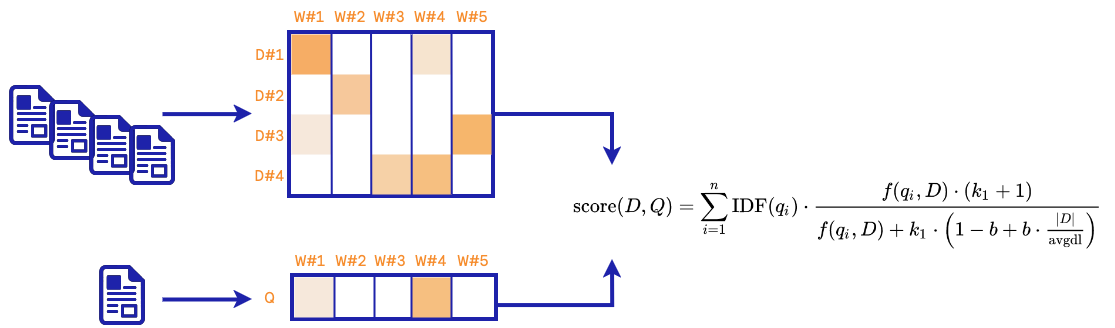
在训练阶段,基于从文档分块收集的术语频率创建一个稀疏矩阵。在检索阶段,使用相同的术语频率策略对查询进行向量化,并根据上述定义计算查询向量与每个文档向量之间的分数。选择前k个文档,这些文档应该是与查询最相关的。
如上所述的BM25方法不一定能掌握文档或查询中的语义。已经开发出多种方法来改进基于术语的方法的方向,例如查询或文档扩展或术语依赖性。在这里,我们不使用这些方法中的任何一种,而是将BM25与神经网络方法相结合。
基于神经网络的方法
在这里,我们使用预训练的Sentence-BERT模型。这类模型旨在学习语义。
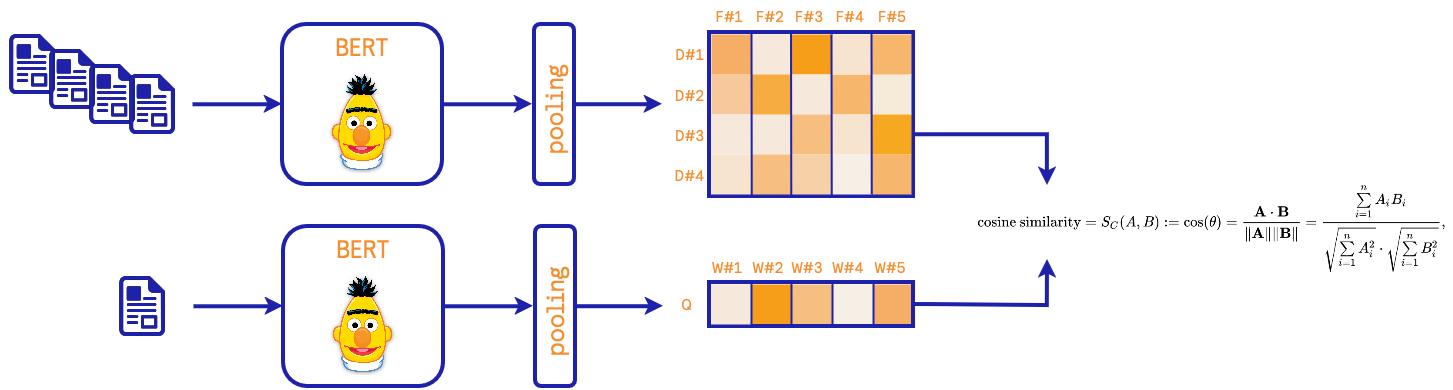
在模型训练过程中,与池化阶段结合的BERT模型针对相似/不相似文档的配对进行调整。池化策略和损失函数是每个模型实现细节的一部分。这种方法的一个后果是神经网络掌握了文档背后的语义。在检索阶段,查询通过BERT模型嵌入并通过池化处理,然后计算与训练文档的距离。通过近似最近邻算法找到前k个文档。
采用这种方法,需要注意的是我们需要选择一个预训练模型来嵌入文档。
实践中的检索器
在我们的原型中,我们同时使用了这两种方法。
3.7 文档重新排名
为了重新排列由不同模型找到的文档,我们使用了一个交叉编码器模型。其原理如下图所示:
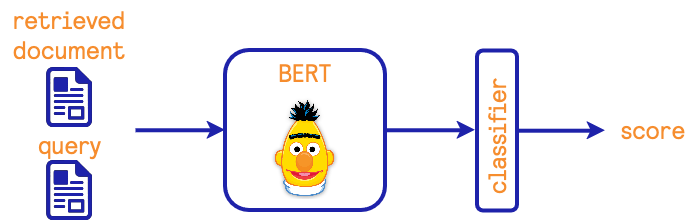
其想法是提供用户的查询和检索到的文档,并用BERT模型对其进行嵌入。BERT模型的输出向量被一个分类器使用,该分类器提供一个相似度分数,用于重新排列文档。
3.8 最后的亮点:与LLM合成
一旦我们检索到帮助回答用户查询的信息,我们就准备好向LLM请求合成。虽然大量工作致力于制作最佳提示,但在这里我们只创建了一个简单的提示:
prompt = (
"[INST] You are a scikit-learn expert that should be able to answer"
" machine-learning question.\n\nAnswer to the query below using the"
" additional provided content. The additional content is composed of"
" the HTML link to the source and the extracted contextual"
" information.\n\nBe succinct.\n\n"
"Make sure to use backticks whenever you refer to class, function, "
"method, or name that contains underscores.\n\n"
f"query: {query}\n\n{context_query} [/INST]."
)4、我们的RAG技术栈
在本节中,我们将总结实现我们的RAG系统的不同库和模型。我们可以将其描绘如下:
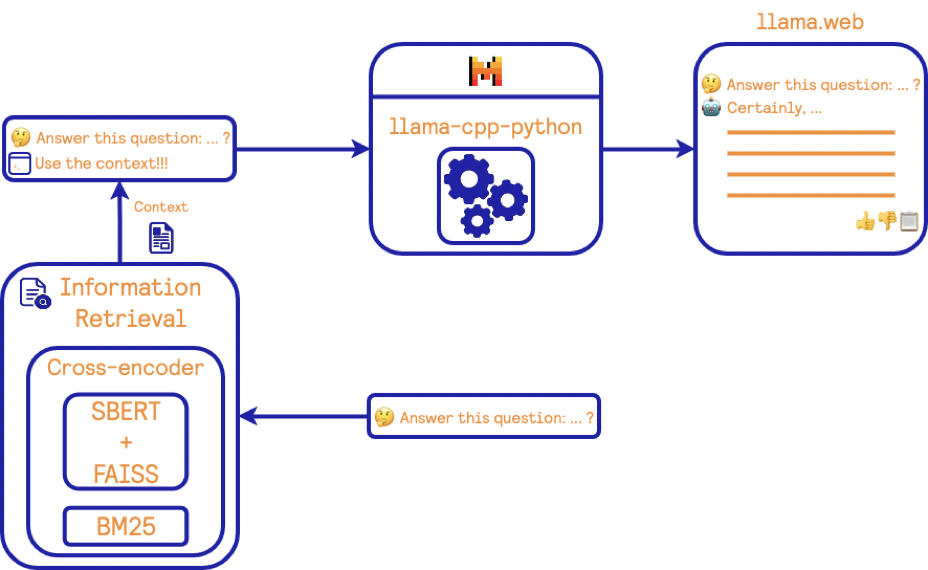
让我们为这个图中的每个块提供一些细节:
- 我们使用了我们自己的BM25算法实现BM25算法
- 双编码器和交叉编码器是在SBERT库中实现的。对于双编码器模型,我们使用的是通用文本嵌入的大版本(gte-large)。该模型在一般检索任务上表现良好。对于交叉编码器,我们使用的是ms-marco-MiniLM-L-6-v2模型。该模型经过训练以解决Bing引擎上的查询。
- 近似最近邻算法使用的是FAISS库。
- 对于LLM,我们使用的是Mistral 7b v0.2模型的量化版本。我们通过llama-cpp-python库进行接口。
- 作为聊天前端,我们修改了llama.web项目以拥有一个最小界面。
这里的一些选择是基于以下因素:
- 给定库的可用性和安装的便利性。
- 对于模型,权重在宽松许可下的可用性。
- 实现解决方案时尽量减少依赖项数量,并避免其他库的嵌套或包装代码。
在其他约束条件下,上述的一些选择可能会切换到更流行或性能更高的库或模型。我们只是想提供一个原型解决方案来探索RAG系统在查询scikit-learn文档方面的潜力。
5、ragger-duck:我们的可重复证明概念
在开发这个原型时,我们希望使其完全可重复。所有库的协调都被整合到一个名为ragger-duck的GitHub存储库中。
有关训练和启动前端的说明可以在此处找到这里。
关于前面提到的概念,您可以在以下文件中找到:
使用的不同类在ragger-duck的API文档中有记录。
6、关于缺点的最后几点
6.1 难以评估和微调
虽然预训练模型提供了快速构建这种RAG系统的能力,而无需在训练阶段遇到瓶颈,但代价转移到了评估和微调阶段。
在我们的背景下,由于我们添加了不收集数据的限制,我们无法评估我们的RAG或微调任何组件(检索模型)。互联网上的一些资源建议使用其他LLM来评估RAG提供的答案,或者作为扩展,使用这些LLM来创建用于调整RAG组件的数据集(例如,使用LoRA)。在我看来,这些方法在方法学上并不合理也不正确。通常用于评估或创建数据集的外部LLM是更大更强的模型。在这种情况下,认为这些强大的LLM提供了黄金标准是没有理由的;这些LLM同样也存在幻觉现象。
唯一可行的操作是让用户自愿向我们发送他们的搜索查询和对系统答案的满意度。这将是一个有趣的实验。
6.2 成本高昂的机器人?
最后,还有关于在生产环境中部署此系统以服务于用户的问题。首先,我们可以参考AnyScale的成本分析:类似描述的系统平均每次请求的成本估计为$0.0003。在scikit-learn的背景下,我们每月大约有1百万用户查看文档。如果每个用户开始每月进行10次请求,那么总成本将达到每月约$3,000。使用更强大的模型也会增加价格。快速查看像Scaleway这样的云提供商,配备8个GPU的机器每月价格约为$5,000。这样的资源可能需要提供良好的用户体验。这为我们社区部署此类系统提供了粗略的价格估算。在为这项服务融资方面,开源社区很难资助这样的努力。所以在考虑部署此类解决方案之前,这是需要记住的一点。
7、其他内容
这项工作在PyConDE & PyData Berlin 2024会议上进行了展示,您可以在这里找到视频。
原文链接:A RAG from scratch to query the scikit-learn documentation
汇智网翻译整理,转载请标明出处
