构建你的第一个AI代理
在我构建第一个商业AI代理三个月后,在客户演示中一切崩溃了。那次失败改变了我的方法,并成为我解释这些系统的基石。

在我构建第一个商业AI代理三个月后,在客户演示中一切崩溃了。
原本应该是一个无缝自主的工作流程,却变成了尴尬的重复澄清请求和不一致决策的循环。客户虽然保持礼貌,但明显表现出失望。
他们离开后,我花了几个小时分析失败原因,发现我从根本上误解了代理架构——我建立了一个过于复杂、边界模糊且没有明确推理路径的系统。
那次失败改变了我的方法,并成为我解释这些系统的基石。一旦理解了核心原理,构建有效的代理变得出乎意料地简单。
1、AI代理概述
我讨厌人们把这东西搞得太复杂,所以让我们保持简单。
AI代理是这样的系统:(1)逐步思考问题,(2)在需要时连接外部工具,(3)从其行为中学习以随着时间改进。
与仅响应提示的聊天机器人不同,代理主动采取行动并自行完成任务。它们的区别在于有人回答你的数据问题和有人真正为你分析数据之间的差异。
1.1 从模型到代理
在代理之前,我们构建AI解决方案时采用的是分离、独立的组件——一个模型用于理解文本,另一个生成代码,还有一个处理图像。
这种碎片化方法(1)迫使用户手动管理工作流,(2)在不同系统之间移动时导致上下文丢失,以及(3)为每个过程步骤构建定制集成。
代理改变了这一范式。
与传统模型处理孤立任务不同,代理管理各种能力的同时保持对整个任务的整体理解。
代理不仅仅是遵循指令——它们根据过程中学到的内容适应并智能地决定下一步,类似于人类的操作方式。
1.2 AI代理的核心优势
让我们通过一个具体任务来了解代理的能力:分析Medium上的文章。
传统AI将其分解为孤立的步骤——总结、提取关键词、分类内容和生成见解,每个步骤都需要显式的人类协调。
问题不仅在于模型单独工作,还在于你必须手动安排整个流程,显式管理各步骤之间的知识转移,并基于中间结果独立确定需要哪些额外操作。
相比之下,基于代理的方法能够自主执行每个步骤而不失去对整体目标的关注。
1.3 代理智能的构建模块
AI代理基于三个基本原则:
- 状态管理:代理的工作记忆跟踪它学到的内容和目标
- 决策制定:代理根据当前知识确定哪种方法有意义
- 工具使用:代理知道哪个工具解决每个特定问题
1.4 使用LangGraph构建AI代理
现在你已经了解了什么是AI代理以及为什么它们重要,让我们使用LangGraph——LangChain的一个框架来构建健壮的AI代理。
我真的很喜欢LangGraph的一点是,它允许你将代理的思维和行动映射为图。每个节点代表一种能力(如搜索网络或编写代码),节点之间的连接(边)控制信息流。
当我开始构建代理时,这种方法对我很有意义,因为我可以实际可视化代理的思维过程。
2、你的第一个代理:Medium文章分析器
让我们看看如何使用LangGraph创建一个文本分析代理。
这个代理将阅读文章、弄清楚它们的主题、提取重要内容并提供简洁的摘要——本质上就是你的个人研究助手。
2.1 设置环境
首先,你需要设置开发环境。
步骤1——创建项目目录:
mkdir ai_agent_project cd ai_agent_project
步骤2——创建并激活虚拟环境:
# 在Windows上
python -m venv agent_env agent_env\Scripts\activate
# 在macOS/Linux上
python3 -m venv agent_env source agent_env/bin/activate
步骤3——安装必要包:
pip install langgraph langchain langchain-openai python-dotenv
步骤4——设置你的OpenAI API:
我使用GPT-4o mini作为代理的大脑,但你可以替换为你喜欢的任何LLM。如果你没有API密钥:
- 在OpenAI注册账户
- 导航到API密钥部分
- 点击“创建新的秘密密钥”
- 复制你的API密钥
步骤5——创建一个.env文件:
# 在Windows上
echo OPENAI_API_KEY=your-api-key-here > .env
# 在macOS/Linux上
echo "OPENAI_API_KEY=your-api-key-here" > .env
将‘your-api-key-here’替换为你的OpenAI API密钥。
步骤6——创建一个名为test_setup.py的测试文件:
python
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
# 加载环境变量
load_dotenv()
# 初始化ChatOpenAI实例
llm = ChatOpenAI(model="gpt-4o-mini")
# 测试设置
response = llm.invoke("Hello! Are you working?") print(response.content)
步骤7——运行测试:
python test_setup.py
如果收到响应,恭喜,你的环境已准备好构建代理!
2.2 创建我们的第一个代理
首先导入必要的库:
import os
from typing import TypedDict, List
from langgraph.graph import StateGraph, END
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage
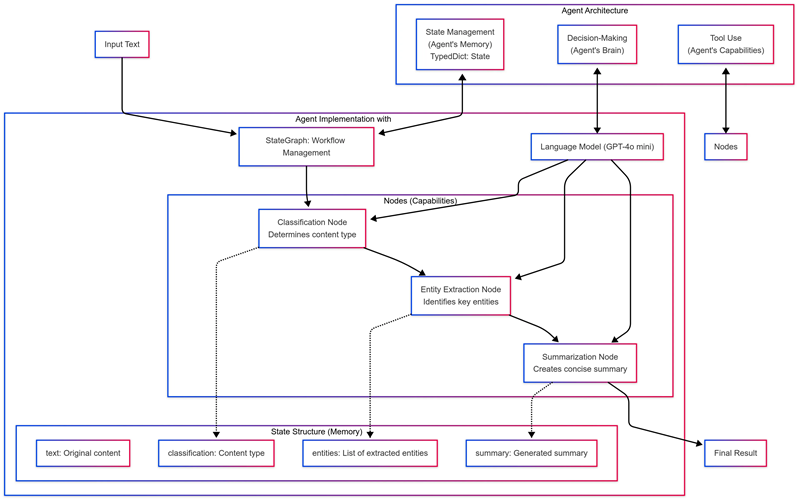
StateGraph管理代理组件之间的信息流。PromptTemplate创建一致的指令,而ChatOpenAI连接到OpenAI的字符模型以驱动代理的思维。
2.3 创建代理的记忆
我们的代理需要记忆来跟踪其进度,我们可以用TypedDict创建这个:
# 原始问题或任务
class State(TypedDict): text:
# 跟踪代理的思考和决策
str classification:
# 存储工具的中间结果
str entities: List[str] summary: str
这种结构让我们的代理记住你的请求,跟踪其推理,存储工具数据,并准备最终答案。使用TypeDict提供了类型安全,警告我们存储错误的数据类型,这简化了调试。
现在我们的代理有了记忆,让我们给它一些思考能力!
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
将Temperature设置为0确保我们的代理始终选择最可能的响应——这对于遵循特定推理模式的代理至关重要。作为复习,温度对于LLMs来说就像“创造力旋钮”:
- Temperature=0: 集中、确定性的响应
- Temperature=1: 更多变化、创造性的输出
- Temperature=2: 奇异、有时不连贯的想法
如果你的代理做出奇怪的决定,请先检查你的温度设置!
2.4 添加代理的能力
现在我们将为我们的代理构建专门的工具,每个工具处理特定的任务类型。
首先,我们的分类能力:
def classification_node(state: State):
"""
将文本分类为预定义的类别之一。
参数:
state (State): 当前包含要分类文本的状态字典
返回:
dict: 包含分类结果的字典
类别:
- 新闻: 对当前事件的事实性报道
- 博客: 个人或非正式的网络写作
- 研究: 学术或科学内容
- 其他: 不属于上述类别的内容
"""
# 定义一个提示模板,要求模型分类给定的文本
prompt = PromptTemplate(
input_variables=["text"],
template="将以下文本分类为以下类别之一: 新闻、博客、研究或其它。\n\n文本:{text}\n\n类别:"
)
# 根据状态中的输入文本格式化提示
message = HumanMessage(content=prompt.format(text=state["text"]))
# 根据提示调用语言模型来分类文本
classification = llm.invoke([message]).content.strip()
# 以字典形式返回分类结果
return {"classification": classification}
此函数使用提示模板向我们的 AI 模型提供明确的指示。该函数获取我们的当前状态(包含我们正在分析的文本)并返回其分类。
接下来,我们的实体提取函数:
def entity_extraction_node(state: State):
# Function to identify and extract named entities from text
# Organized by category (Person, Organization, Location)
# Create template for entity extraction prompt
# Specifies what entities to look for and format (comma-separated)
prompt = PromptTemplate(
input_variables=["text"],
template="Extract all the entities (Person, Organization, Location) from the following text. Provide the result as a comma-separated list.\n\nText:{text}\n\nEntities:"
)
# Format the prompt with text from state and wrap in HumanMessage
message = HumanMessage(content=prompt.format(text=state["text"]))
# Send to language model, get response, clean whitespace, split into list
entities = llm.invoke([message]).content.strip().split(", ")
# Return dictionary with entities list to be merged into agent state
return {"entities": entities}此函数处理文档并返回关键实体的列表,如重要名称、组织和地点。
最后是我们的摘要能力:
def summarize_text(state):
# Create a template for the summarization prompt
# This tells the model to summarize the input text in one sentence
summarization_prompt = PromptTemplate.from_template(
"""Summarize the following text in one short sentence.
Text: {input}
Summary:"""
)
# Create a chain by connecting the prompt template to the language model
# The "|" operator pipes the output of the prompt into the model
chain = summarization_prompt | llm
# Execute the chain with the input text from the state dictionary
# This passes the text to be summarized to the model
response = chain.invoke({"input": state["input"]})
# Return a dictionary with the summary extracted from the model's response
# This will be merged into the agent's state
return {"summary": response.content}此函数将文档提炼为其中主要观点的简洁摘要。
结合这些技能,使我们的代理能够理解内容类型,识别关键信息,并创建可消化的摘要——每个功能都遵循从当前状态开始,处理它,并返回有用的信息供下一个功能使用的模式。
2.5 最终确定代理结构
现在我们将这些能力整合成一个协调的工作流程:
workflow = StateGraph(State)
# Add nodes to the graph
workflow.add_node("classification_node", classification_node)
workflow.add_node("entity_extraction", entity_extraction_node)
workflow.add_node("summarization", summarization_node)
# Add edges to the graph
workflow.set_entry_point("classification_node") # Set the entry point of the graph
workflow.add_edge("classification_node", "entity_extraction")
workflow.add_edge("entity_extraction", "summarization")
workflow.add_edge("summarization", END)
# Compile the graph
app = workflow.compile()恭喜!
您已经构建了一个从分类到实体提取再到摘要的流程,使代理能够理解文本类型,识别重要实体,创建摘要,然后完成整个过程。
3、代理的实际应用
现在让我们使用示例文本测试我们的代理:
# Define a sample text about Anthropic's MCP to test our agent
sample_text = """
Anthropic's MCP (Model Context Protocol) is an open-source powerhouse that lets your applications interact effortlessly with APIs across various systems.
"""
# Create the initial state with our sample text
state_input = {"text": sample_text}
# Run the agent's full workflow on our sample text
result = app.invoke(state_input)
# Print each component of the result:
# - The classification category (News, Blog, Research, or Other)
print("Classification:", result["classification"])
# - The extracted entities (People, Organizations, Locations)
print("\nEntities:", result["entities"])
# - The generated summary of the text
print("\nSummary:", result["summary"])运行此代码会通过每个能力处理文本:
- 分类:技术
- 实体:['Anthropic','MCP','模型上下文协议']
- 摘要:Anthropic的MCP是一个开源协议,使应用程序能够与各种API系统无缝交互。
令人印象深刻之处不仅在于最终结果,还在于每个阶段如何建立在前一个阶段的基础上。这反映了我们自己的阅读过程:首先确定内容类型,然后识别重要的名称和概念,最后创建连接一切的思维摘要。
这种代理构建方法远远超出了我们的技术示例。您可以使用类似的设置来处理其他内容:
- 个人发展文章——分类成长领域,提取可操作建议,并总结关键见解
- 创业者故事——识别商业模式、融资模式和增长策略
- 产品评论——识别特性、品牌和推荐
4、AI代理的局限性
我们的代理在其设计的固定框架内运作。
这种可预测性限制了其适应性。与人类不同,代理遵循固定的路径,无法在面对意外情况时灵活应对。
上下文理解也是另一个局限。这个代理可以处理文本,但缺乏人类自然掌握的更广泛的知识和文化细微差别。代理在其提供的文本范围内运作,尽管增加互联网搜索可以帮助补充其知识。
黑盒问题也存在于代理系统中。我们看到输入和输出,但看不到内部决策过程。像GPT-o1或DeepSeek R1这样的推理模型通过显示其思考过程提供了更多透明度,尽管我们仍然无法完全控制其内部发生的事情。
最后,这些系统不是完全自主的,需要人工监督,尤其是在验证输出和确保准确性方面。与其他任何AI系统一样,最佳结果来自于将AI能力与人为监督相结合。
理解这些局限性有助于我们构建更好的系统,并知道何时需要人类介入。最佳结果来自于将AI能力与人类专业知识相结合。
5、代理演示失败带来的痛苦教训
回顾那次尴尬的客户演示失败,我现在认识到理解代理的局限性对于成功至关重要。由于忽略了代理架构的基本约束,我过于复杂的系统崩溃了。
通过接受代理:(1) 需要清晰的框架,(2) 在定义的路径内运行,(3) 作为部分黑盒运行,以及(4) 需要人工监督,我已经构建了实际交付结果而不是无尽澄清循环的系统。
那次痛苦的演示教会了我在AI开发中最宝贵的一课:有时构建非凡事物的道路始于理解AI不能做什么。
理解这些局限性并不会削弱代理技术——而是使其真正有用。这就是演示崩溃与解决方案交付结果之间的区别。
原文链接:The Complete Guide to Building Your First AI Agent (It’s Easier Than You Think)
汇智网翻译整理,转载请标明出处
