打造人工智能忏悔室
本文分享我们如何构建我们的 LLM 语音应用程序并将其集成到忏悔室的交互式展台中。

虽然 OpenAI 推迟了 ChatGPT 高级语音模式的发布,但我想分享我们如何构建我们的 LLM 语音应用程序并将其集成到忏悔室的交互式展台中。
1、与丛林中的人工智能交谈
2 月底,巴厘岛举办了 Lampu 节,根据著名的火人节的原则安排。根据传统,参与者可以创建自己的装置和艺术品。
我和 Camp 19:19 的朋友受到天主教忏悔室的想法和当前 LLM 的能力的启发,提出了建立我们自己的人工智能忏悔室的想法,任何人都可以与人工智能交谈。
以下是我们最初的设想:
- 当用户进入展台时,我们确定需要开始新的会话。
- 用户提出问题,人工智能倾听并回答。我们希望创造一个信任和私密的环境,每个人都可以公开讨论他们的想法和经历。
- 当用户离开房间时,系统会结束会话并忘记所有对话细节。这对于保持所有对话的私密性是必要的。
2、概念验证
为了测试这个概念并开始尝试 LLM 的提示,我在一个晚上创建了一个基本的实现:
- 听麦克风。
- 使用语音转文本 (STT) 模型识别用户语音。
- 通过 LLM 生成响应。
- 使用文本转语音 (TTS) 模型合成语音响应。
- 向用户回放响应。
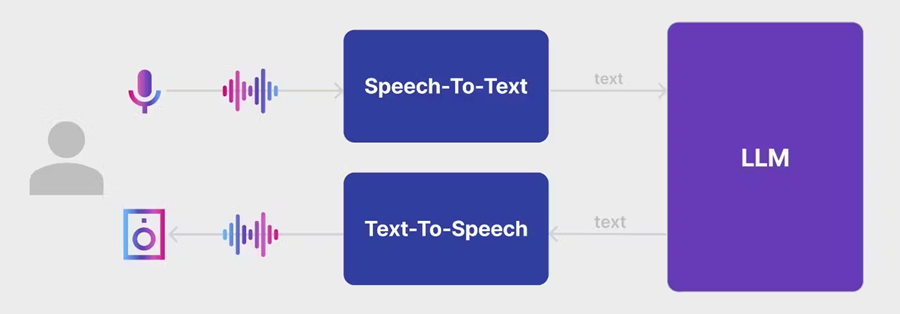
为了实现这个演示,我完全依赖 OpenAI 的云模型:Whisper、GPT-4 和 TTS。多亏了优秀的speech_recognition语音识别库,我只用了几十行代码就构建了这个演示。
import os
import asyncio
from dotenv import load_dotenv
from io import BytesIO
from openai import AsyncOpenAI
from soundfile import SoundFile
import sounddevice as sd
import speech_recognition as sr
load_dotenv()
aiclient = AsyncOpenAI(
api_key=os.environ.get("OPENAI_API_KEY")
)
SYSTEM_PROMPT = """
You are helpfull assistant.
"""
async def listen_mic(recognizer: sr.Recognizer, microphone: sr.Microphone):
audio_data = recognizer.listen(microphone)
wav_data = BytesIO(audio_data.get_wav_data())
wav_data.name = "SpeechRecognition_audio.wav"
return wav_data
async def say(text: str):
res = await aiclient.audio.speech.create(
model="tts-1",
voice="alloy",
response_format="opus",
input=text
)
buffer = BytesIO()
for chunk in res.iter_bytes(chunk_size=4096):
buffer.write(chunk)
buffer.seek(0)
with SoundFile(buffer, 'r') as sound_file:
data = sound_file.read(dtype='int16')
sd.play(data, sound_file.samplerate)
sd.wait()
async def respond(text: str, history):
history.append({"role": "user", "content": text})
completion = await aiclient.chat.completions.create(
model="gpt-4",
temperature=0.5,
messages=history,
)
response = completion.choices[0].message.content
await say(response)
history.append({"role": "assistant", "content": response})
async def main() -> None:
m = sr.Microphone()
r = sr.Recognizer()
messages = [{"role": "system", "content": SYSTEM_PROMPT}]
with m as source:
r.adjust_for_ambient_noise(source)
while True:
wav_data = await listen_mic(r, source)
transcript = await aiclient.audio.transcriptions.create(
model="whisper-1",
temperature=0.5,
file=wav_data,
response_format="verbose_json",
)
if transcript.text == '' or transcript.text is None:
continue
await respond(transcript.text, messages)
if __name__ == '__main__':
asyncio.run(main())我们必须解决的问题在对该演示进行首次测试后,立即显现出以下问题:
- 响应延迟。在简单的实现中,用户提问和响应之间的延迟为 7-8 秒或更长时间。这并不好,但显然,有很多方法可以优化响应时间。
- 环境噪音。我们发现,在嘈杂的环境中,我们不能依靠麦克风自动检测用户何时开始和结束说话。识别短语的开始和结束(端点)并非易事。再加上音乐节的嘈杂环境,很明显需要一种概念上不同的方法。
- 模仿现场对话。我们希望让用户能够中断 AI。为了实现这一点,我们必须保持麦克风打开。但在这种情况下,我们不仅必须将用户的声音与背景声音分开,还必须将用户的声音与 AI 的声音分开。
- 反馈。由于响应延迟,有时我们觉得系统被冻结了。我们意识到我们需要告知用户响应需要多长时间处理
我们有一个解决这些问题的方法:寻找合适的工程或产品解决方案。
3、思考展台的用户体验
在我们开始编码之前,我们必须决定用户如何与展台互动:
- 我们应该决定如何检测展台中的新用户以重置过去的对话历史记录。
- 如何识别用户语音的开始和结束,以及如果他们想打断人工智能该怎么办。
- 当人工智能响应延迟时如何实现反馈。
为了检测展台中的新用户,我们考虑了几种选择:开门传感器、地板重量传感器、距离传感器和摄像头 + YOLO 模型。背后的距离传感器在我们看来是最可靠的,因为它排除了意外触发,例如当门关得不够紧时,并且不需要复杂的安装,不像重量传感器。
为了避免识别对话开始和结束的挑战,我们决定添加一个大红色按钮来控制麦克风。该解决方案还允许用户随时中断人工智能。
关于在处理请求时实现反馈,我们有很多不同的想法。我们决定采用一种屏幕选项,显示系统正在做什么:收听麦克风、处理问题或回答问题。
我们还考虑了使用旧固定电话的相当智能的选项。会话将在用户拿起电话时开始,系统将收听用户直到用户挂断电话。但是,我们认为,当用户通过展台“回答”而不是通过电话的声音时,它更真实。

最终的用户流程如下:
- 用户走进展台。 距离传感器在他背后触发,我们向他打招呼。
- 用户按下红色按钮开始对话。 按下按钮时,我们会收听麦克风。 当用户释放按钮时,我们开始处理请求并在屏幕上显示。
- 如果用户想在 AI 回答时提出新问题,他们可以再次按下按钮,AI 将立即停止回答。
- 当用户离开隔间时,距离传感器再次触发,我们清除对话历史记录。
4、架构
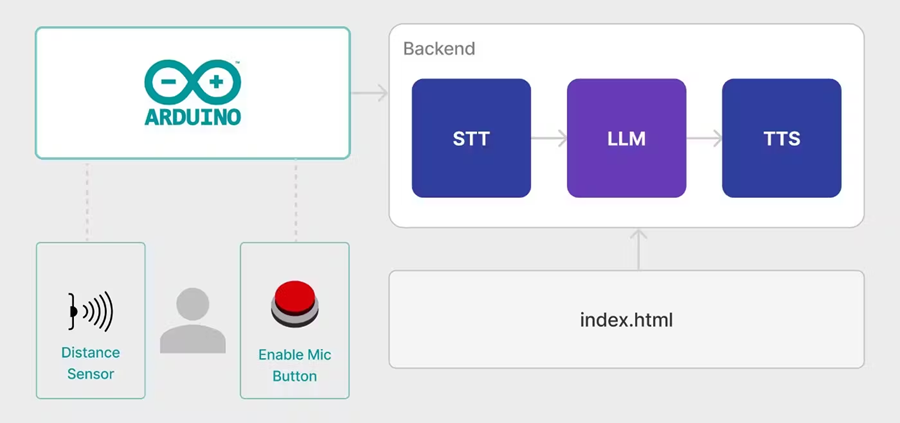
Arduino 监控距离传感器和红色按钮的状态。它通过 HTTP API 将所有更改发送到我们的后端,这使系统能够确定用户是否已进入或离开隔间,以及是否需要激活监听麦克风或开始生成响应。
Web UI 只是一个在浏览器中打开的网页,它不断从后端接收系统的当前状态并将其显示给用户。
后端控制麦克风,与所有必要的 AI 模型交互,并发出 LLM 响应的声音。它包含应用程序的核心逻辑。
5、硬件
如何为 Arduino 编写sketch,正确连接距离传感器和按钮,并在隔间中组装它们,这是一个单独的文章主题。让我们简要回顾一下我们得到的东西,而不涉及技术细节。
我们使用了 Arduino,更准确地说,是带有内置 Wi-Fi 模块的型号 ESP32。微控制器与运行后端的笔记本电脑连接到同一个 Wi-Fi 网络。

我们使用的硬件完整列表:
6、后端
管道的主要组件是语音转文本 (STT)、LLM 和文本转语音 (TTS)。对于每个任务,许多不同的模型都可以在本地和云端使用。

由于我们手头没有强大的 GPU,我们决定选择基于云的模型版本。这种方法的弱点是需要良好的互联网连接。尽管如此,经过所有优化后的交互速度还是可以接受的,即使在节日期间使用移动互联网也是如此。
现在,让我们仔细看看管道的每个组件。
6.1 语音识别
许多现代设备早已支持语音识别。例如,Apple Speech API 适用于 iOS 和 macOS,Web Speech API 适用于浏览器。
不幸的是,它们的质量远不如 Whisper 或 Deepgram,并且无法自动检测语言。
为了减少处理时间,最好的选择是在用户说话时实时识别语音。以下是一些项目及其实现示例:whisper_streaming、whisper.cpp
在我们的笔记本电脑上,使用这种方法的语音识别速度远非实时。经过几次实验,我们决定使用 OpenAI 的基于云的 Whisper 模型。
6.2 LLM 和 提示工程
上一步中的语音转文本模型的结果是我们发送给 LLM 的带有对话历史记录的文本。
在选择 LLM 时,我们比较了 GPT-3.5、GPT-4 和 Claude。结果发现关键因素与其说是具体的模型,不如说是它的配置。最终,我们选择了 GPT-4,我们更喜欢它的答案。
LLM 模型的提示定制已成为一种独立的艺术形式。互联网上有许多关于如何根据需要调整模型的指南:
我们必须对提示和温度设置进行广泛的实验,以使模型做出引人入胜、简洁和幽默的响应。
6.3 文本转语音
我们使用文本转语音模型将从 LLM 收到的响应语音化,并将其播放给用户。这一步是我们演示中延迟的主要来源。
LLM 需要很长时间才能做出响应。但是,它们支持以流式模式生成响应 - 逐个标记。我们可以使用此功能来优化等待时间,方法是在收到单个短语时将其发声,而无需等待 LLM 的完整响应。
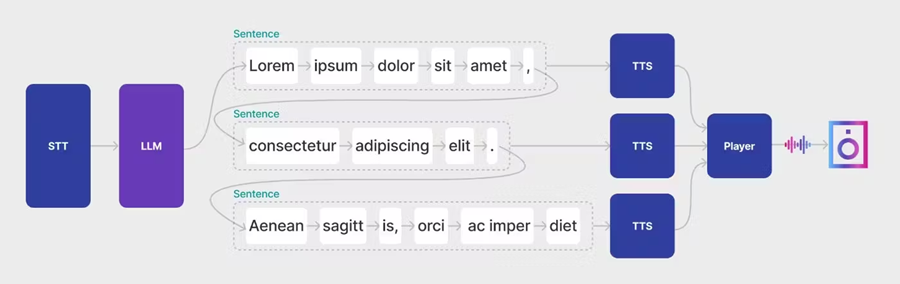
- 向 LLM 发出查询。
- 我们将响应逐个标记地累积在缓冲区中,直到得到一个长度最小的完整句子。最小长度参数非常重要,因为它会影响发声的语调和初始延迟时间。
- 将生成的句子发送到 TTS 模型,并将结果播放给用户。在此步骤中,必须确保播放顺序中没有竞争条件。
- 重复上一步,直到 LLM 响应结束
我们利用用户收听初始片段的时间来隐藏处理 LLM 响应剩余部分的延迟。由于采用了这种方法,响应延迟仅发生在开始时,大约为 3 秒。
async generateResponse(history) {
const completion = await this.ai.completion(history);
const chunks = new DialogChunks();
for await (const chunk of completion) {
const delta = chunk.choices[0]?.delta?.content;
if (delta) {
chunks.push(delta);
if (chunks.hasCompleteSentence()) {
const sentence = chunks.popSentence();
this.voice.ttsAndPlay(sentence);
}
}
}
const sentence = chunks.popSentence();
if (sentence) {
this.voice.say(sentence);
}
return chunks.text;
}
7、最后润色
即使我们进行了所有优化,3-4 秒的延迟仍然很严重。我们决定通过反馈来处理 UI,以免用户感觉响应被挂起。我们研究了几种方法:
- LED 指示灯。我们需要显示五种状态:空闲、等待、聆听、思考和说话。但我们无法想出如何用 LED 轻松理解的方式来做到这一点。
- 填充词,例如“让我想想”、“嗯”等,模仿现实生活中的言语。我们拒绝了此选项,因为填充词通常与模型响应的语气不匹配。
- 在展台上放置一个屏幕。并用动画显示不同的状态。
我们选择了最后一个选项,即一个简单的网页,该网页轮询后端并根据当前状态显示动画。

8、结束语
我们的 AI 忏悔室运行了四天,吸引了数百名与会者。我们在 OpenAI API 上只花了大约 50 美元。作为回报,我们收到了大量积极的反馈和宝贵的印象。
这个小实验表明,即使在资源有限和外部条件具有挑战性的情况下,也可以为 LLM 添加直观高效的语音界面。
顺便说一句,后端源代码可在 GitHub 上找到
原文链接:How Build Your Own AI Confessional: How to Add a Voice to the LLM
汇智网翻译整理,转载请标明出处
