打造自己的AI研究员
本文将解释如何创建自己的AI研究员,它可以从互联网上找到上下文相关的有用信息,并提供适当的答案。

最成功的“AI包装器”之一是AI知识引擎Perplexity。它使用户能够研究并找到相关信息,然后由大型语言模型对这些信息进行总结和解释,从而回答用户的查询。
本文将解释如何创建自己的AI研究人员,该研究人员可以从互联网上找到上下文相关的有用信息,并提供适当的答案。
1、技术栈
有很多工具可供选择,但这是我为本博客选择的技术栈:
- DSPy——一个内置提示优化的AI框架。它简单、模块化且易于使用。您可以在这里了解更多:这里。
- Exa——提供了一个易于使用的API,用于搜索网络、查找相关信息并将信息传递给LLM。
2、搜索API(如Exa)的作用是什么?
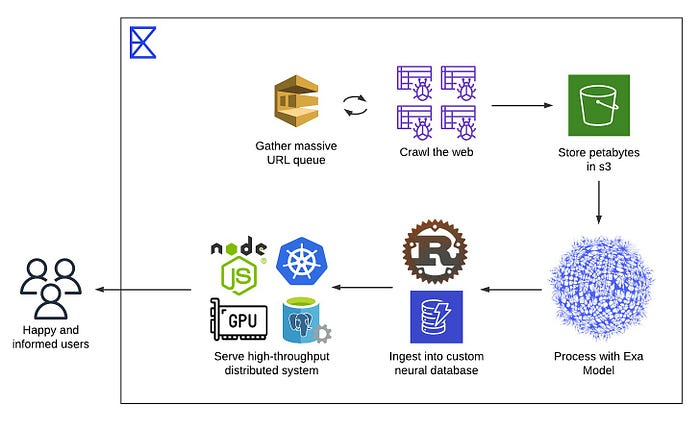
搜索API通过索引互联网工作。一个简单的理解方式是它们像检索器一样从网页和链接中提取信息。它们的区别在于索引的方式有多好。这是它们的主要“差异化因素”。例如,Perplexity API和Exa以不同的方式组织和访问网络内容。
以下是Exa底层索引和搜索技术的简化版本。
Exa是一个结合了神经搜索和基于关键词搜索的搜索引擎。它不完全依赖关键词匹配,而是使用嵌入(即文本的向量表示)来对其索引的网络内容进行语义搜索。这使得即使查询中的确切术语不存在,也能返回意义相关的搜索结果。
其核心是一种称为“下一个链接预测”的方法,其中模型根据查询和索引文档的语义内容预测哪些文档或链接最为相关。这对于模糊或探索性查询特别有用,因为用户可能不知道确切的术语。
然而,在需要精确匹配的情况下,比如专有名词、技术术语或已知关键词时,Exa也支持传统的关键词搜索。这两种搜索模式被整合到一个名为Auto Search的系统中,该系统使用轻量级分类器决定将查询路由到神经搜索引擎、关键词搜索引擎还是两者兼用。
这种混合设置帮助Exa处理各种类型的查询,平衡了语义相关性和精确性。
3、如何使用Exa的API
现在进入有趣的部分,你将了解如何使用此API从网络中搜索上下文相关的有用信息。搜索API有三个关键方法:
Exa通过嵌入式或Google风格的关键字搜索在Web上找到您要找的确切内容,具有以下三个核心功能:
搜索: 使用Exa的嵌入式或Google风格的关键字搜索查找网页。
from exa_py import Exa
exa = Exa('YOUR_EXA_API_KEY')
results = exa.search_and_contents(
"Find blogs by FireBirdTech",
type ="auto",# 可以根据您的偏好选择neural或keyword
numResults=30, # 返回的结果数量
)
print(results)
内容:获取来自Exa搜索结果的干净、最新的解析HTML。
from exa_py import Exa
exa = Exa('YOUR_EXA_API_KEY')
#crawls the web for the contents of the webpages specified
results = exa.get_contents(
urls=["https://firebird-technologies.com"],
text=True
)
print(results)
查找相似链接:根据链接,找到并返回在意义上相似的页面。
from exa_py import Exa
exa = Exa('YOUR_EXA_API_KEY')
contents of # the pages
results = exa.find_similar_and_contents(
url="www.firebird-technologies.com",
text=True
)
print(results)
搜索功能简单易用,如果您想全面了解API的所有功能,可以查看Exa的API参考这里
4、AI研究人员的设计
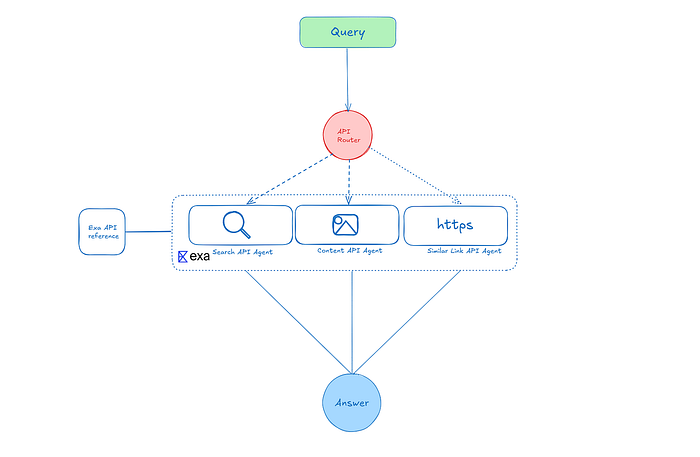
我设计了一个三步系统,这样研究人员可以同时使用多个API。以下是它的运作方式:
1. API路由器: 这一部分决定使用哪个API来回答查询。大多数查询只需要搜索API,但也有必要有选项来抓取内容或查找相似链接。
2. API代理: 有三个代理,每个代理都配备了最适合特定API的特殊提示。
3. 答案层: 这是所有内容汇聚的地方。系统汇总并分析信息,给出最终答案。
4.1 API路由器
以下是API路由器的提示
class api_router(dspy.Signature):
"""You are an intelligent router that decides which Exa API(s) to call to answer a user query. Choose the fewest number of APIs needed to produce a relevant and useful result.
There are three available APIs:
search: Use this to discover new documents based on a topic, keyword, or research question.
contents: Use this when the user provides one or more known URLs and wants full text, summary, or highlights.
findSimilar: Use this when the user gives a URL and wants to find related links.
You can also combine APIs in sequence if needed, but prefer the minimal number of calls.
Return your decision as a list of APIs with a short explanation for each.
Examples:
Query: Summarize this paper: https://arxiv.org/abs/2307.06435
api_selection:contents
selection_reason: Get the summary and highlights of the provided paper.
Query: What are the latest trends in scalable LLM training?
api_selection:search
Query: Find related blog posts to this article: [URL]
api_selection:findSimilar
selection_reason: Find related content based on the URL.
Query: Give me summaries of new papers on few-shot learning
api_selection:search,contents
selection_reason: The user wants summaries of new papers on few-shot learning
Only use findSimilar if a URL is provided and user wants to find related links.
"""
query = dspy.InputField(description="The search query the user wants to search for")
api_selection = dspy.OutputField(description="The API to use for the query - search,content or find_similar_link")
selection_reason = dspy.OutputField(description="The reason for the API selection")
# using chain of thought for better prompting
api_router_agent = dspy.ChainOfThought(api_router)
response = api_router_agent(query = "Find blog posts by FireBirdTech")程序响应

API路由器的响应,推理和选择原因用于更好的答案,但所需的输出是api_selection
4.2 API代理
所有三个API代理都有类似的结构,它们被喂入Exa的Python文档。
它们有一个输入(查询)和一个输出(API设置)
class search_api_agent(dspy.Signature):
"""
You are an intelligent API assistant that generates structured settings for calling the Exa `/search` endpoint.
Your role is to interpret a user's query and intent, and return a complete Python dictionary representing the JSON payload for the request.The `/search` endpoint parameters are:
**Basic Parameters**
Here's the information formatted into a **table** for better clarity:
| **Input Parameters** | **Type** | **Description** | **Default** |
|----------------------------|----------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------|
| `query` | `str` | The input query string. | Required |
| `text` | `Union[TextContentsOptions, Literal[True]]` | If provided, includes the full text of the content in the results. | None |
| `highlights` | `Union[HighlightsContentsOptions, Literal[True]]` | If provided, includes highlights of the content in the results. | None |
| `num_results` | `Optional[int]` | Number of search results to return. | 10 |
| `include_domains` | `Optional[List[str]]` | List of domains to include in the search. | None |
| `exclude_domains` | `Optional[List[str]]` | List of domains to exclude in the search. | None |
| `start_crawl_date` | `Optional[str]` | Results will only include links crawled after this date. | None |
| `end_crawl_date` | `Optional[str]` | Results will only include links crawled before this date. | None |
| `start_published_date` | `Optional[str]` | Results will only include links with a published date after this date. | None |
| `end_published_date` | `Optional[str]` | Results will only include links with a published date before this date. | None |
| `type` | `Optional[str]` | The type of search, either "keyword" or "neural". | "auto" |
| `category` | `Optional[str]` | A data category to focus on when searching (e.g., company, research paper, news, etc.). | None |
---
**Your Task:**
Given a user query and any known preferences (e.g. prefer research papers, want summaries only, exclude news, etc.), generate a JSON-compatible Python dictionary representing the body for a POST request to `/search`.
💡 Example Input:
> Query: "Latest developments in LLM capabilities"
✅ Example Output:
```python
{
"query": "Latest developments in LLM capabilities",
"type": "auto",
"category": "research paper",
"numResults": 25,
"contents": {
"text": True,
"summary": True,
"highlights": False,
"livecrawl": "fallback",
"livecrawlTimeout": 10000,
"subpages": 0,
"extras": {
"links": 0,
"imageLinks": 0
}
}
}
Unless specified otherwise, always keep summary True
"""
query = dspy.InputField(description="The search query the user wants to search for")
api_settings = dspy.OutputField(description="The settings for the search API in python dictionary format")
# ChainOfThought prompting for better responses
search_api_AI = dspy.ChainOfThought(search_api_agent)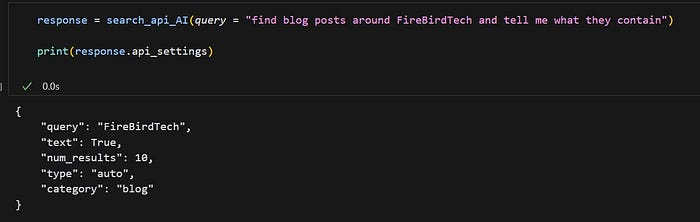
API代理返回用于API的设置,您可以将其作为字典传递给API以获取响应。
其他两个也是以相同方式构建的,唯一的区别是使用的API文档不同。
4.3 回答代理
class answer_summarize_analyze(dspy.Signature):
"""
You are a research assistant AI. Your task is to read through a list of website content and generate a helpful summary based on a user query.
### User Query:
{query}
### Source Data:
{web_data}
---
Instructions:
- Analyze all the web_data provided.
- Focus only on content relevant to the query.
- Provide a concise and informative summary of the findings.
- Group or list items clearly if multiple blog posts or sources are referenced.
- Do not include unrelated metadata (like ratings, loading GIFs, etc.).
- Provide links to the original posts when helpful.
- Be accurate, neutral, and professional in tone.
Respond only with the analysis, summarise and answer to the user query!
---
### 👇 Example with your provided input:
**Query:**
> Find blog posts around FireBirdTech and tell me what they contain.
**Resulting AI Response:**
Here are some recent blog posts related to FireBirdTech:
1. **[Jaybird 5.0.5 Released](https://www.firebirdnews.org/jaybird-5-0-5-released/)**
A new version of the Jaybird JDBC driver introduces bug fixes and minor feature enhancements:
- Fixed precision issues for `NUMERIC` and `DECIMAL` columns.
- Improved support for auto-increment columns and metadata queries.
- Added support for Firebird 5.0 features and updated Java compatibility.
2. **[Firebird Monitor Tool – Version 2](https://www.firebirdnews.org/real-time-firebird-monitor-for-firebird-server-2-5-3-0-4-0-5-0-2/)**
A real-time database monitoring tool with trace and audit capabilities. A 10% discount is offered until June 2024.
3. **[Database Workbench 6.5.0 Released](https://www.firebirdnews.org/database-workbench-6-5-0-released/)**
New features include Firebird 5, MySQL 8.3, and PostgreSQL 16 support. A new SQLite module has been introduced for enhanced compatibility.
4. **[DBD::Firebird Perl Extension v1.38](https://www.firebirdnews.org/perl-extension-dbdfirebird-version-1-38-is-released/)**
Updates include support for Firebird's BOOLEAN data type and improvements to compatibility with older Perl and Firebird versions.
5. **[Kotlin Multiplatform Firebird SQL Client Library](https://www.firebirdnews.org/firebird-sql-client-library-for-kotlin-multiplatform/)**
A client library for accessing Firebird databases from Kotlin Multiplatform environments, targeting JVM, Android, and native.
6. **[IBProvider v5.37 Released](https://www.firebirdnews.org/release-of-ibprovider-v5-37/)**
A Firebird database provider for C++ with updates including improved error message handling, ICU changes, and thread pool improvements.
7. **[Firebird Export Tool](https://www.firebirdnews.org/firebird-export/)**
Open-source tool to export Firebird databases to formats like CSV and JSON, supporting selective exports and blob data.
8. **[RedExpert 2024.04 Released](https://www.firebirdnews.org/redexpert-2024-04-has-been-released/)**
A new version of the RedExpert tool for managing and developing Firebird databases.
9. **[libpthread Compatibility Warning for Firebird 2.5](https://www.firebirdnews.org/libpthread-compatibility-problem-with-firebird-2-5/)**
Compatibility issues have been found between newer libpthread versions and Firebird 2.5 on Linux. Patching or upgrading is recommended.
10. **[Hopper Debugger v2.3 Released](https://www.firebirdnews.org/stored-routine-debugger-hopper-v2-3-released/)**
A debugging tool for stored routines with new Firebird 5 support and general bug fixes
"""
query = dspy.InputField(description="The query that the user wants to get the contents of")
web_data = dspy.InputField(description="The web data that the user wants to get the contents of")
answer = dspy.OutputField(description="The answer to the user query")
answer_summarize_analyze = dspy.ChainOfThought(answer_summarize_analyze)
response = answer_summarize_analyze(query = "find blog posts around FireBirdTech and tell me what they contain", web_data = result.results[1].text)
我们的AI研究人员生成的响应,附带了来源!
以下是使用相似链接API的系统:
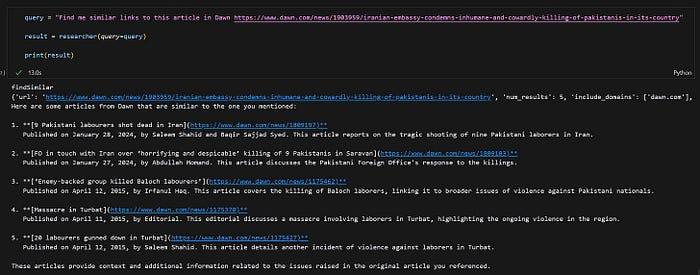
对于查找与提到的文章相似的文章的查询的响应。
原文链接:Creating an AI-Powered Researcher: A Step-by-Step Guide
汇智网翻译整理,转载请标明出处
