用DeepSeek与网页聊天
本教程将向你展示如何使用Python和DeepSeek构建一个简单的聊天机器人,它可以读取任何网页并回答关于该网页的问题。

你是否曾经想向网页提出特定问题而不必手动搜索其内容?本教程将向你展示如何使用Python和DeepSeek构建一个简单的聊天机器人,它可以读取任何网页并回答关于该网页的问题。
只需提供一个URL,机器人就会获取页面的内容,并允许你像与网络个人助手交互一样与其互动。
让我们跳入其中看看它是如何工作的!
💡 注意: DeepSeek需要API资金才能运行。价格非常实惠——5美元就足够开始使用它了。在运行脚本之前,请务必检查你的DeepSeek余额,否则可能会遇到错误!
0、完整脚本
别担心,我们会为你分解它。
from openai import OpenAI # 允许我们与DeepSeek的API进行交互
import requests # 启用抓取网页内容
from bs4 import BeautifulSoup # 解析和提取HTML中的可读文本
# 初始化DeepSeek客户端
client = OpenAI(
api_key="YOUR_DEEPSEEK_API_KEY", # 替换为你的DeepSeek API密钥
base_url="https://api.deepseek.com/v1", # DeepSeek API基本URL
)
def get_text_from_url(url):
"""
从给定的URL抓取并提取文本内容。
"""
try:
response = requests.get(url)
response.raise_for_status() # 对HTTP错误引发异常
except requests.exceptions.RequestException as e:
print(f"抓取URL时出错: {e}")
return None
# 解析HTML内容
soup = BeautifulSoup(response.content, 'html.parser')
# 删除脚本和样式元素
for script_or_style in soup(['script', 'style']):
script_or_style.decompose()
# 提取并清理文本
text = soup.get_text(separator='\n')
lines = [line.strip() for line in text.splitlines()]
text = '\n'.join(line for line in lines if line)
return text
def ask_question_about_content(content, question):
"""
根据提供的内容提问。
"""
try:
response = client.chat.completions.create(
model="deepseek-chat", # 使用DeepSeek-V3模型
messages=[
{"role": "system", "content": "你是一个基于提供的内容回答问题的助手。"},
{"role": "user", "content": f"内容:\n{content}"},
{"role": "user", "content": f"根据上述内容,请回答以下问题:\n\n{question}"}
],
temperature=0.7, # 控制随机性(0 = 确定性,1 = 创造性)
)
answer = response.choices[0].message.content.strip()
return answer
except Exception as e:
print(f"处理问题时出错: {e}")
return None
def main():
"""
运行聊天机器人的主函数。
"""
url = input('请输入网页的URL: ')
print('正在从URL抓取内容...')
content = get_text_from_url(url)
if content is None:
print('未能检索到内容。退出。')
return
print('你现在可以询问关于内容的问题。')
while True:
question = input('问题(或输入“exit”退出): ')
if question.lower() in ['exit', 'quit']:
print('再见!')
break
answer = ask_question_about_content(content, question)
if answer:
print('答案:', answer)
else:
print('未能获得答案。')
if __name__ == '__main__':
main()
1、获取你的DeepSeek API密钥
- 注册或登录到DeepSeek
- 前往https://platform.deepseek.com/api_keys 获取你的API密钥
- 确保有足够的资金:DeepSeek的价格相当实惠,你可以仅用2美元测试,但根据你的使用情况请确保增加这个金额。
2、安装所需的库
pip install openai requests beautifulsoup4
openai:允许我们与DeepSeek的API进行交互requests:抓取网页内容beautifulsoup4:解析和提取HTML中的可读文本
3、提取网页文本
在我们可以提问之前,我们需要抓取并清理网页的内容。下面的函数会删除不必要的元素,如脚本和样式,只留下可读的文本。
def get_text_from_url(url):
"""
从给定的URL抓取并提取文本内容。
"""
try:
response = requests.get(url)
response.raise_for_status() # 对HTTP错误引发异常
except requests.exceptions.RequestException as e:
print(f"抓取URL时出错: {e}")
return None
# 解析HTML内容
soup = BeautifulSoup(response.content, 'html.parser')
# 删除脚本和样式元素
for script_or_style in soup(['script', 'style']):
script_or_style.decompose()
# 提取并清理文本
text = soup.get_text(separator='\n')
lines = [line.strip() for line in text.splitlines()]
text = '\n'.join(line for line in lines if line)
return text
4、询问关于网页的问题
现在我们已经提取了文本,我们可以使用DeepSeek的AI根据这些内容回答问题。
def ask_question_about_content(content, question):
"""
根据提供的内容提问。
"""
try:
response = client.chat.completions.create(
model="deepseek-chat", # 使用DeepSeek-V3模型
messages=[
{"role": "system", "content": "你是一个基于提供的内容回答问题的助手。"},
{"role": "user", "content": f"内容:\n{content}"},
{"role": "user", "content": f"根据上述内容,请回答以下问题:\n\n{question}"}
],
temperature=0.7, # 控制随机性(0 = 确定性,1 = 创造性)
)
answer = response.choices[0].message.content.strip()
return answer
except Exception as e:
print(f"处理问题时出错: {e}")
return None
5、运行聊天机器人
在终端中运行脚本
python chatbot.py
6、示例交互

我输入了一个URL,这是这篇新闻文章,并要求它总结成一段话。
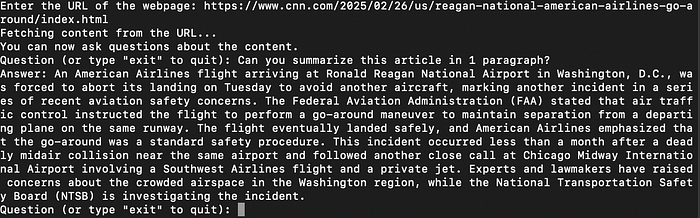
答案:美国航空公司的一架航班于周二在华盛顿特区罗纳德·里根国家机场着陆时,因避免另一架飞机而被迫中断降落,这标志着最近一系列航空安全问题中的又一起事件。联邦航空管理局(FAA)表示,空中交通管制指示该航班执行绕飞机动以保持与其他在同一跑道上起飞的飞机的安全距离。该航班最终安全着陆,美国航空公司强调绕飞是一种标准的安全程序。这一事件发生在不到一个月前同一机场附近发生致命空难之后,以及芝加哥中途国际机场涉及西南航空公司航班和一架私人飞机的另一起险情之后。专家和立法者对华盛顿地区拥挤的空域表示担忧,而国家运输安全委员会(NTSB)正在调查这一事件。
你可以尝试任何网页,包括维基百科页面或其他文章!
7、结束语
通过这个简单的DeepSeek驱动的聊天机器人,你可以立即从任何网页提取信息。试试看,并告诉我们你构建了什么!
原文链接:How I Chat with Any Webpage Using DeepSeek and Python
汇智网翻译整理,转载请标明出处
