CLIP模型微调简明教程
CLIP 是一种流行的多模态嵌入模型,它使用对比学习在大量图像-标题对语料库上进行训练。 CLIP可以解锁零样本能力,例如图像分类、搜索和字幕。
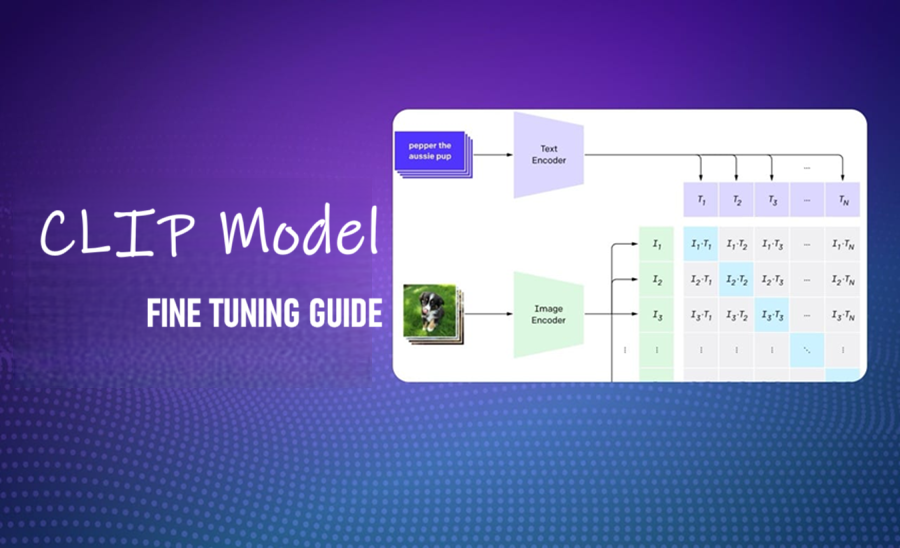
这是关于多模态 AI 的大型系列文章中的第 4 篇。在上一篇文章中,我们讨论了多模态 RAG 系统,它可以从不同的数据模态(例如文本、图像、音频)中检索和合成信息。在那里,我们看到了如何使用 CLIP 实现这样的系统。然而,这种方法的一个问题是,通用嵌入模型(如 CLIP)的向量搜索结果在特定领域的用例中可能表现不佳。
在本文中,我将讨论如何通过微调多模态嵌入模型来缓解这些问题。
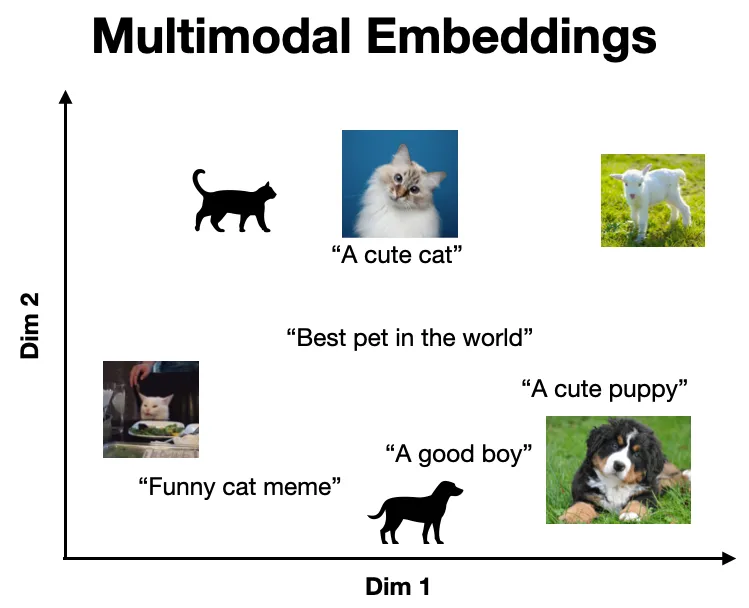
多模态嵌入表示同一向量空间中的多种数据模态,因此相似的概念位于同一位置。下面显示了一个直观的示例,其中语义相似的项目(例如狗的图片及其对应的标题)很接近,而不相似的项目(例如猫的图片和描述狗的标题)相距很远。
CLIP 是一种流行的多模态嵌入模型,它使用对比学习在大量图像-标题对语料库上进行训练。 CLIP 的关键见解是,这种模型可以解锁零样本能力,例如图像分类、搜索和字幕 [1]。
这里的其中一个限制是 CLIP 的零样本能力可能无法很好地转移到涉及专业信息的领域,例如建筑图纸、医学成像和技术术语。在这种情况下,我们可以通过微调来提高 CLIP 的性能。
1、CLIP微调概述
微调涉及通过额外的训练将模型调整到特定用例。这很强大,因为它使我们能够在现有的最先进模型的基础上构建功能强大的专用模型,并且数据量相对较小。
我们可以通过以下关键步骤使用 CLIP 实现此目的。
- 收集文本-图像训练对
- 预处理训练数据
- 定义评估
- 微调模型
- 评估模型
我将在具体示例中讨论每个步骤。
2、用YouTube标题和缩略图微调 CLIP
在这里,我将针对我的 YouTube 频道中的标题和缩略图微调 CLIP。最终,我们将得到一个模型,该模型可以获取标题-缩略图对并返回相似度得分。这可用于实际应用,例如将标题创意与现有缩略图匹配或对缩略图库进行搜索。
示例代码、数据集和微调模型分别在 GitHub 和 Hugging Face Hub 上免费提供。你可以使用此代码和数据来训练自己的模型。如果你最终使用此数据集发布任何作品,请引用原始来源 :)
2.1 收集文本-图像训练对
任何微调过程的第一步(也是最重要的一步)都是数据收集。在这里,我通过两步流程从我的频道中提取了标题-缩略图对。
首先,我使用 YouTube 的搜索 API 提取我频道上所有视频的视频 ID。其次,我使用 YouTube 的视频 API 提取每个长视频(即时长超过 3 分钟)的标题和缩略图 URL。
channel_id = 'UCa9gErQ9AE5jT2DZLjXBIdA' # my YouTube channel ID
page_token = None # initialize page token
url = 'https://www.googleapis.com/youtube/v3/search' # YouTube search API
# extract video data across multiple search result pages
video_id_list = []
while page_token != 0:
params = {
"key": my_key,
'channelId': channel_id,
'part': ["snippet","id"],
'order': "date",
'maxResults':50,
'pageToken': page_token
}
response = requests.get(url, params=params)
for raw_item in dict(response.json())['items']:
# only execute for youtube videos
if raw_item['id']['kind'] != "youtube#video":
continue
# grab video ids
video_id_list.append(raw_item['id']['videoId'])
try:
# grab next page token
page_token = dict(response.json())['nextPageToken']
except:
# if no next page token kill while loop
page_token = 0请注意,你需要一个 YouTube API 密钥来运行上述 Python 代码,可以使用 Google Cloud Console 创建该密钥。要使其适应你的频道,只需更改 channel_id 变量。
# extract video titles and thumbnails
url = "https://www.googleapis.com/youtube/v3/videos"
video_data_list = []
for video_id in video_id_list:
params = {
"part": ["snippet","contentDetails"],
"id": video_id,
"key": my_key,
}
response = requests.get(url, params=params)
raw_dict = dict(response.json())['items'][0]
# only process videos longer than 3 minutes
iso_duration = raw_dict['contentDetails']["duration"]
if parse_duration(iso_duration).total_seconds() < 180:
continue
# extract video data
video_data = {}
video_data['video_id'] = video_id
video_data['title'] = raw_dict['snippet']['title']
video_data['thumbnail_url'] = raw_dict['snippet']['thumbnails']['high']['url']
# append data to list
video_data_list.append(video_data)作为附加步骤,我创建了负缩略图标题对。我们可以在训练过程中使用这些对,不仅可以为模型提供哪些嵌入应该靠近(即正对)的示例,还可以为哪些嵌入应该远离(即负对)的示例。
为此,我使用句子转换器库计算了所有可能的标题对之间的相似性。然后,对于每个正对,我将最不相似的标题匹配为负示例(确保没有重复)。
# store data in dataframe
df = pd.DataFrame(video_data_list)
# Load the model
model = SentenceTransformer("all-mpnet-base-v2")
# Encode all titles
embeddings = model.encode(df['title'].to_list())
# compute similarities
similarities = model.similarity(embeddings, embeddings)
# match least JDs least similar to positive match as the negative match
similarities_argsorted = np.argsort(similarities.numpy(), axis=1)
negative_pair_index_list = []
for i in range(len(similarities)):
# Start with the smallest similarity index for the current row
j = 0
index = int(similarities_argsorted[i][j])
# Ensure the index is unique
while index in negative_pair_index_list:
j += 1 # Move to the next smallest index
index = int(similarities_argsorted[i][j]) # Fetch next smallest index
negative_pair_index_list.append(index)
# add negative pairs to df
df['title_neg'] = df['title'].iloc[negative_pair_index_list].values最后,我创建了一个训练-有效-测试分割并将数据集推送到 Hugging Face Hub。
# Shuffle the dataset
df = df.sample(frac=1, random_state=42).reset_index(drop=True)
# Split into train, validation, and test sets
train_frac = 0.7
valid_frac = 0.15
test_frac = 0.15
# define train and validation size
train_size = int(train_frac * len(df))
valid_size = int(valid_frac * len(df))
# create train, validation, and test datasets
df_train = df[:train_size]
df_valid = df[train_size:train_size + valid_size]
df_test = df[train_size + valid_size:]
# Convert the pandas DataFrames back to Hugging Face Datasets
train_ds = Dataset.from_pandas(df_train)
valid_ds = Dataset.from_pandas(df_valid)
test_ds = Dataset.from_pandas(df_test)
# Combine into a DatasetDict
dataset_dict = DatasetDict({
'train': train_ds,
'valid': valid_ds,
'test': test_ds
})# push data to hub
dataset_dict.push_to_hub("shawhin/yt-title-thumbnail-pairs")2.2 预处理训练对
虽然我们拥有微调所需的所有数据,但它仍然不是适合训练的格式。更具体地说,我们需要将图像 URL 转换为 PIL 图像对象,并将数据组织成(锚点、正、负)三元组,即缩略图、其对应的标题和负标题。
我们可以使用 Hugging Face Datasets 库以以下方式处理所有三个数据分割(即训练、验证和测试)。
from PIL import Image
# load dataset
dataset = load_dataset("shawhin/yt-title-thumbnail-pairs")
# define preprocessing function
def preprocess(batch):
"""
Preprocessing data without augmentations for test set
"""
# get images from urls
image_list = [Image.open(requests.get(url, stream=True).raw)
for url in batch["thumbnail_url"]]
# return columns with standard names
return {
"anchor": image_list,
"positive": batch["title"],
"negative": batch["title_neg"]
}
# remove columns not relevant to training
columns_to_remove = [col for col in dataset['train'].column_names
if col not in ['anchor', 'positive', 'negative']]
# apply transformations
dataset = dataset.map(preprocess, batched=True,
remove_columns=columns_to_remove)我们将列按(锚点、正值、负值)三元组排序很重要,因为这是我们在训练期间将使用的损失函数所期望的格式(这是我从痛苦中学到的)。
2.3 定义评估
训练涉及优化模型的参数以最小化损失函数。然而,这个值(即对比损失)很少有助于评估模型在下游任务(例如将标题与缩略图匹配)上的表现。
在这种情况下,一个更有洞察力的量是模型在多个候选中正确匹配给定缩略图与正确标题的能力。这表示为 Recall@1。
我们可以实现一个与 Sentence Transformers 库兼容的评估器来计算这个指标。由于代码很长,我不会在这里粘贴它,但好奇的读者可以在这个笔记本的第 12 单元中找到它。
# function to create new evaluator given data split
def create_recall_evaluator(set_name, k=1):
"""
Create triplet evaluator for "train", "valid", or "test" split
"""
return ImageTextRetrievalEvaluator(
images=dataset[f"{set_name}"]["anchor"],
texts=dataset[f"{set_name}"]["positive"],
name=f"yt-title-thumbnail-{set_name}",
k=k
)
# Create new evaluator with Recall@k
evaluator_recall_train = create_recall_evaluator("train", k=1)
evaluator_recall_valid = create_recall_evaluator("valid", k=1)
print("Train:", evaluator_recall_train(model))
print("Valid:", evaluator_recall_valid(model))
# >> Train: {'yt-title-thumbnail-train_Recall@1': 0.660377358490566}
# >> Valid: {'yt-title-thumbnail-valid_Recall@1': 0.6363636363636364}我们可以看到,该模型开箱即用,性能不错,66% 的时间匹配正确的标题。
2.4 微调模型
在训练模型之前,我们必须做 3 件关键的事情。即,选择要训练的参数、选择损失函数和设置超参数。
- 可训练参数
该项目的主要限制是我只发布了 76 个 YouTube 视频(截至撰写本文时)。通过验证和测试拆分,只剩下 53 个示例可供训练。
由于我们的训练样本非常少,限制训练参数的数量是个好主意。在本例中,我只训练模型的最终投影层,该层将文本和图像嵌入映射到共享向量空间中。总共约有 1M 个参数。
# import model
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/clip-ViT-L-14")
# pick specific layers to train (note: you can add more layers to this list)
trainable_layers_list = ['projection']
# Apply freezing configuration
for name, param in model.named_parameters():
# freeze all params
param.requires_grad = False
# unfreeze layers in trainable_layers_list
if any(layer in name for layer in trainable_layers_list):
param.requires_grad = True# Count total and trainable parameters
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total parameters: {total_params:,}")
print(f"Trainable parameters: {trainable_params:,}")
print(f"% of trainable parameters: {100*trainable_params/total_params:.2f}%")
# >> Total parameters: 427,616,513
# >> Trainable parameters: 1,376,256
# >> % of trainable parameters: 0.32%- 损失函数
在这里,我使用 Sentence Transformers 库中的多负排序损失(在本例中,它适用于单个负样本)。它的工作原理是最大化正样本对之间的相似性,同时最小化负样本对之间的相似性。以下是单个负样本情况的损失函数 [2]。

from sentence_transformers.losses import MultipleNegativesRankingLoss
# define loss
loss = MultipleNegativesRankingLoss(model)- 超参数
对于超参数,我手动尝试了一些选择,并选择了验证损失和 Recall@1 性能最佳的选择。以下是最终的选择。
from sentence_transformers import SentenceTransformerTrainingArguments
# hyperparameters
num_epochs = 2
batch_size = 16
lr = 1e-4
finetuned_model_name = "clip-title-thumbnail-embeddings"
train_args = SentenceTransformerTrainingArguments(
output_dir=f"models/{finetuned_model_name}",
num_train_epochs=num_epochs,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
learning_rate=lr,
# Evaluation settings
eval_strategy="epoch",
eval_steps=1,
logging_steps=1,
)定义好损失和超参数后,我们可以使用 SentenceTransformersTrainer() 来训练模型。
from sentence_transformers import SentenceTransformerTrainer
trainer = SentenceTransformerTrainer(
model=model,
args=train_args,
train_dataset=dataset["train"],
eval_dataset=dataset["valid"],
loss=loss,
evaluator=[evaluator_recall_train, evaluator_recall_valid],
)
trainer.train()模型训练是一个迭代过程,你可以在其中探索数十种模型,以选择不同的可训练参数、损失函数和超参数。
然而,我强烈建议尽可能简化这些实验。如果你发现自己花了太多时间调整训练参数以使模型收敛,那么你的数据可能存在根本性错误(经验之谈😅)。
2.5 评估模型
最后一步,我们可以评估模型在测试集上的 Recall@1 分数。这些数据未用于训练或超参数调整,因此它为我们提供了对模型的公正评估。
evaluator_recall_test = create_recall_evaluator("test")
print("Train:", evaluator_recall_train(model))
print("Valid:", evaluator_recall_valid(model))
print("Test:", evaluator_recall_test(model))
# >> Train: {'yt-title-thumbnail-train_Recall@1': 0.8490566037735849}
# >> Valid: {'yt-title-thumbnail-valid_Recall@1': 0.9090909090909091}
# >> Test: {'yt-title-thumbnail-test_Recall@1': 0.75}我们看到模型在所有三个数据集上表现良好,测试集上的 Recall@1 为 75%。换句话说,75% 的时间里,该模型能够正确地将给定的缩略图与其原始标题匹配。此外,验证数据集的召回率也增加了 27%!
3、接下来是什么?
多模态嵌入模型(如 CLIP)解锁了无数 0-shot 用例,例如图像分类和检索。在这里,我们看到了如何微调这样的模型以使其适应专门的领域(即我的 YouTube 标题和缩略图)。
虽然 CLIP 按照今天的标准来说是一个小模型(约 5 亿个参数),而且我们的训练数据集很小,但最终模型仍然在这个任务上表现出色。这凸显了微调的威力。
原文链接:Fine-tuning Multimodal Embedding Models
汇智网翻译整理,转载请标明出处
