与ChatGPT合作开发软件
本文继续探索使用 ChatGPT 进行软件开发。它说明了人类与人工智能之间的协作如何改进和加速解决问题。

本文继续探索使用 ChatGPT 进行软件开发。它说明了人类与人工智能之间的协作如何改进和加速解决问题。今天的报告强调了一种迭代交互风格,融合了探索、选择性改进响应和同行评审解决方案。这种方法考虑了 Yehonathan Sharvit 关于认知跨度(记忆、注意力和结构)的假设,这些对于理解和操纵代码至关重要。这些“大脑跨度”是与生成式AI进行有效协作的镜头,其中明确的上下文管理和清晰度至关重要。
这种混合问题解决方法平衡了人类直觉与AI的结构化推理,尊重编程的认知需求并反映了讲故事的艺术——故事在合作者之间流动。
1、协作软件项目
不久前,我写了一篇关于协作在生成式AI软件开发中的重要性的文章。在概述中,我解释了代码生成练习可以……
……说明人机协作的重要性,强调人类专业知识增强AI效率时所取得的协同作用。通过提供有针对性的知识和背景,可以更好地引导模型的输出走向实用解决方案。这种协作动态展示了人类直觉和AI辅助如何有效地相互补充。
与“糟糕的科幻小说”协作软件项目进展相关的文章和链接位于此 GitHub。正如原文所述,该项目之所以如此命名,是因为它的目标是开发一种专门用于科幻小说的故事分析工具——一种与生成式AI合作开发的工具。
这篇文章是一份撸起袖子的报告——一个深入研究并完成工作的机会。它还具有探索性交互风格,我会从响应中进行选择性选择。虽然这样做需要领域知识,但它更快、更高效。配对设计和编程具有优势,尤其是使用人工智能时——无论你根据需要加入还是退出,都可以保持高效运行。
1、新的 Windows GUI 和其他改进
我与 ChatGPT 的持续软件合作仍然非常有效。正如我之前提到的,我们合作的关键动态是互动:我提出许多问题,挑选引起共鸣的想法,改进它们,然后重复这个过程。这种方法与依赖一些大型、详细的提示形成鲜明对比。
这里展示了迭代解决问题的力量。我从一个想要实现的想法开始,但其执行是通过改进、反馈,甚至是错误的开始形成的。在这次合作中,我使用 ChatGPT 来帮助我充实一个想法,然后探索和改进一种方法。
这次,我自己承担了更多的实施工作。软件和项目变得越来越复杂,使得有效的提示更具挑战性,因为它需要更有选择性的背景。当下一个任务很简单时,我经常发现卷起袖子“直接做”更容易。但是,正如后面所讨论的,要求人工智能对重要的选择进行同行评审是值得的。
下面的提示是我想要做的事情的开场想法。它代表了对 ChatGPT 的重大要求。这是我们会议的起点。我们剩下的时间都花在深入研究、调整和将结果映射到实现中:
Can you extend the following source code from a Visual Studio C++ Windows GUI application to display the following
1. A basic text editor.
2. A row of drop-down menus along the top of the display.
3. A drop-down menu labeled "Get Text"
4. A sub-menu option under "Get Text" called "From Clipboard"
5. A sub-menu option under "Get Text" called "From File"
6. A drop-down menu labeled "Process"
7. A sub-menu option under "Process" called "Sentiment anchors"
I would like the following behaviors to be implemented:
1. If the user selects the "Get Text" > "From Clipboard" sub-menu
then the client application will obtain the contents of the Windows
clipboard and display it in its text display.
2. If the user selects the "Get Text" > "From File" sub-menu then
the client application will allow the user to browse the file system
to select a text file for display in the application's text display.
3. If the user selects the "Process" > "Sentiment anchors" sub-menu then
the client application will process the text contents of the text
display calling the sentiment_main()
function from the SentimentAnchors.cpp and passing
in the clipboard text or the file path.
(code removed)翻译:
你可以从 Visual Studio C++ Windows GUI 应用程序扩展以下源代码以显示以下内容吗?
- 基本文本编辑器。
- 显示屏顶部的一排下拉菜单。
- 标有“获取文本”的下拉菜单
- “获取文本”下名为“来自剪贴板”的子菜单选项
- “获取文本”下名为“来自文件”的子菜单选项
- 标有“进程”的下拉菜单
- “进程”下名为“情感锚点”的子菜单选项
我希望实现以下行为:
- 如果用户选择“获取文本”>“来自剪贴板”子菜单,则客户端应用程序将获取 Windows剪贴板的内容并将其显示在其文本显示中。
- 如果用户选择“获取文本”>“来自文件”子菜单,则客户端应用程序将允许用户浏览文件系统以选择要在应用程序的文本显示中显示的文本文件。
- 如果用户选择“处理”>“情绪锚点”子菜单,则客户端应用程序将处理文本显示的文本内容,调用 SentimentAnchors.cpp 中的 sentiment_main()函数并传入剪贴板文本或文件路径。
(代码已删除)
对于本文中描述的代码相关交互,我在几个长时间运行的会话中使用了 ChatGPT o1-preview。对于 LaTeX 交互,我使用了 ChatGPT 4o。
ChatGPT 在我们的交互过程中提供了出色的编码帮助,但在我的 Microsoft Visual Studio 配置的一些细节中表现出差距。
ChatGPT 的大多数配置失误可能都是由于目标冲突造成的。我最初要求它将我现有的 Visual Studio 控制台应用程序转换为 Windows GUI 应用程序。但是,它的指示反复假设我会创建一个新的 Windows GUI 项目。最终,我听从了它的建议,手动创建了新项目。
创建完新项目后,我要求 ChatGPT 根据原始提示(上文)更新其代码。图 2 列出了系统的软件项目。BSF-AnchorClient 是(现已弃用的)Windows 控制台应用程序,由新的 BSF-WindowsAnchorClient 取代。
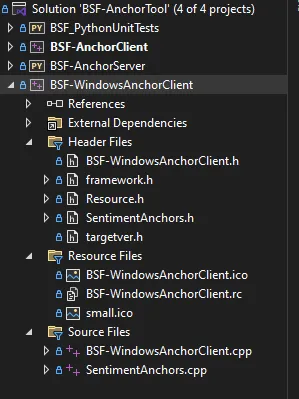
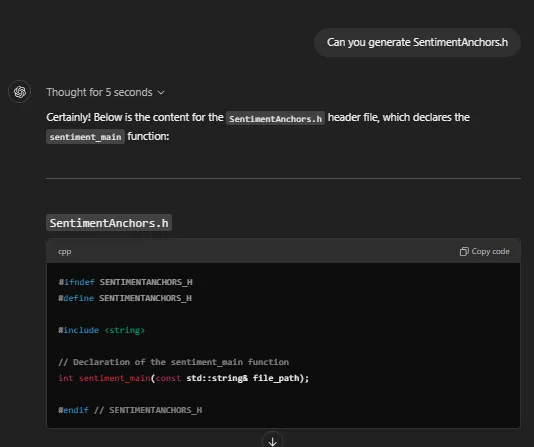
ChatGPT 的代码修订在 Windows GUI/Visual Studio 环境中完美构建,除了一个未解决的问题外,无需进行任何更正:缺少样板头文件。ChatGPT 修改了我的一个源文件以导入一个不存在的头文件(见图 3)。
在屈服于 ChatGPT 明显偏向于让我从新的 MSVC++ Windows GUI 项目开始之前,我明确要求它提供将我现有的 MSVC++ 控制台应用程序转换为 C++ Windows GUI 项目的步骤。我按照它的步骤操作,但遇到了困难。经过大约 15 分钟的故障排除后,我决定坚持 ChatGPT 的偏好,即我手动重新创建项目。
我怀疑 ChatGPT 偏爱在训练过程中遇到更多示例的方法。虽然可以引导它采用替代方法,但由于训练示例较少,这些路径可能会带来更大的风险。
以下是该工具的主要软件功能:
- 文本预处理:Python 情感服务器通过删除停用词和标记文本来预处理文本窗口和情感锚点,以提高分析准确性。
- OpenAI 嵌入:服务器使用 OpenAI 嵌入来计算文本窗口和情感锚点之间的语义相似性,确保准确的情感分配。
- 输出图表:通过 HTTP 以图像形式输出。它还将原始数据以 CSV 格式输出到文件中。
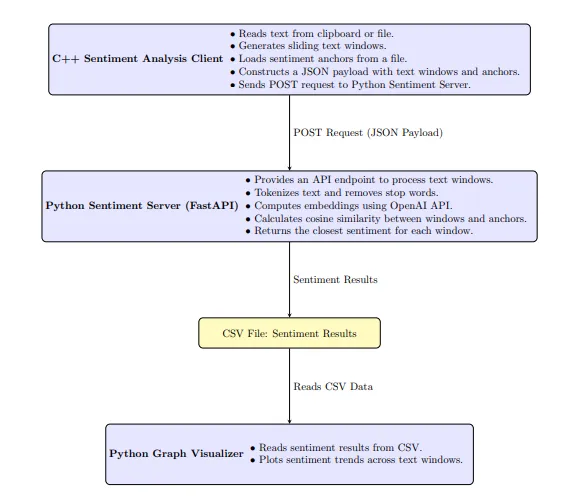
图 4 是整个系统的更新架构图。它由 ChatGPT o1 以 LaTex 格式生成 — 来自源代码(附录)和架构图的先前版本。有三个主要软件组件:C++ 客户端、Python 服务器和 Python 可视化工具。
更新的 Windows GUI 客户端取代了以前的控制台版本。它可以从 Windows 剪贴板检索输入的文本数据,并允许用户使用 Windows API 浏览文件系统中的文件。图 5 展示了在 Visual Studio IDE 中运行的 Windows GUI 客户端。

在创建新的 Windows GUI 客户端项目并使用 ChatGPT 的更新源(源代码可在附录 A 中找到)更新其代码后,我测试了完整的应用程序/系统。在此测试期间,出现了一个问题:
Temporary file path: C:\Users\natha\AppData\Local\Temp\temp_text.txt
Temporary file written.
Calling sentiment_main.
Exception thrown at 0x00007FFE8A32FA4C in BSF-WindowsAnchorClient.exe: Microsoft C++ exception: std::runtime_error at memory location 0x0000008F14D4DE28.
sentiment_main finished.
The thread 19168 has exited with code 0 (0x0).输出没有提供太多信息。我与 ChatGPT 分享了错误和源代码,并征求意见。它回复了一份可能性列表——一份它认为我应该查看的内容的清单。主要建议确定了实际原因:无法读取内部数据文件,因为其相对路径已损坏。
我通过要求 ChatGPT 增强调试输出来确认原因:
Can you update the following function so that it sign-posts its
progress to OutputDebugStringA?翻译:
你能否更新以下函数,以便它将其进度标记到 OutputDebugStringA?
我很困惑为什么之前运行的相对路径方案突然中断。然而,通过 ChatGPT 改进的调试输出,我很快就找到了根本原因。该错误是由新 Windows GUI 客户端中的行为怪癖引起的。每当我使用菜单下拉菜单选择输入文件时,它都会更改应用程序的工作目录位置。
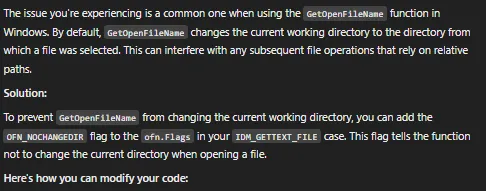
此时,我计划使用绝对路径重新实现系统中的所有相对路径。但是,我要求 ChatGPT 同行评审该问题以仔细检查我的方法。它根据对 Windows API 的深入了解提出了更好的解决方案。我使用的提示如下所示:
Below is the C++ code for my Windows Anchor Client GUI.
A problem that I have is that when I run the client and use the
file selector (menu option), it can change the working directory
to the last directory location the file selector visited.
This can break the use of relative pathing to specify the
anchors file: "./resources/sentiments.txt"
I don't want to switch to absolute pathing. Idea on how to address this?
(code removed)翻译:下面是我的 Windows Anchor Client GUI 的 C++ 代码。我遇到的一个问题是,当我运行客户端并使用文件选择器(菜单选项)时,它可以将工作目录更改为文件选择器访问的最后一个目录位置。
这可以打破使用相对路径来指定锚文件的规则:“./resources/sentiments.txt”
我不想切换到绝对路径。关于如何解决这个问题的想法?
(代码已删除)
图 6 描述了 ChatGPT 的解决方案,该解决方案涉及向 Windows API 调用添加 OFN_NOCHANGEDIR 标志。
通过进一步测试,我注意到系统性能不一致——有时,该工具运行得很快,而其他时候,它需要异常长的时间。我要求 ChatGPT 升级核心服务器功能中的日志记录,它无缝地完成了。这让我能够识别瓶颈:对 OpenAI API 的远程调用。有时,这些调用的延迟最小,但有时,它们的速度明显变慢。我要求 ChatGPT 添加日志记录以更好地记录问题,并询问它是否有任何想法:
Can you update the following to include high-level sign-posting -
output its progress when called. Any suggestions on improving
its performance when the connection to OpenAI is slow?
# Define the API endpoint for text analysis
@app.post("/analyze", response_model=AnalysisResult)
def analyze_text(data: AnalysisRequest):
(code removed)翻译:你能否更新以下内容以包含高级指示 - 调用时输出其进度。当与 OpenAI 的连接速度较慢时,有什么关于改善其性能的建议吗?
#定义用于文本分析的 API 端点
@app.post("/analyze", response_model=AnalysisResult)
def analyze_text(data: AnalysisRequest):
(代码已删除)
ChatGPT 提供了很好的建议。它建议对 OpenAI 的 API 进行批处理和缓存嵌入请求 - 我记得在 API 首次发布时读过这种策略,但后来忘记了。我抓住了这个选项。 ChatGPT 提供了代码更改:
# Step 6: Get embeddings for sentiment anchors and text windows
logging.info("Step 6: Obtaining embeddings for sentiment anchors and
text windows.")
# Cache for embeddings
embedding_cache = {}
# Combine anchors and windows for batch processing
texts_to_embed = preprocessed_anchors + preprocessed_windows
unique_texts = list(set(texts_to_embed))
# Batch embed unique texts
text_embeddings = embeddings.embed_documents(unique_texts)
logging.info(f"Obtained embeddings for {len(unique_texts)} unique texts.")
# Map texts to embeddings
for text, embedding in zip(unique_texts, text_embeddings):
embedding_cache[text] = embedding
# Retrieve embeddings from cache
anchor_embeddings = [embedding_cache[text] for text in preprocessed_anchors]
window_embeddings = [embedding_cache[text] for text in preprocessed_windows]
# Proceed with similarity calculations as before向 OpenAI API 添加批处理和缓存嵌入调用解决了这个问题。
该工具的最后一个重大改进是增加了为用户提供基于浏览器的数据可视化的功能。 Python 服务器组件已升级为一个实验性的 HTTP 端点 (/visualize),可以在浏览器中访问。 图 1 显示了输出的示例。 我正在探索以前生成 CSV 文件和使用 Python 可视化工具脚本的方法的替代方案。 使用的提示如下所示。 ChatGPT 实现了一个新的 REST 端点,我可以毫无问题地集成它:
Can you update the server with another endpoint.
I'd like to be able to obtain an image depicting the results
(as a graph) after an analysis. Cache the results of an analysis
and when /visualize is called, return a graph of the last analysis results.
Provide an HTTP endpoint.翻译:你可以使用另一个端点更新服务器吗?我希望能够在分析后获得一张描绘结果的图像(以图表形式)。缓存分析结果并在调用 /visualize 时返回最后分析结果的图表。提供 HTTP 端点。
2、讨论
与 ChatGPT 的持续合作代表了软件开发中不断发展的叙述,其中人类直觉与人工智能驱动的问题解决相结合。今天的更新侧重于迭代和探索性交互风格——融合有针对性的探索、选择性的响应细化和同行评审解决方案以增强结果。
我听到了 Yehonathan Sharvit 关于认知跨度(记忆、注意力和结构)的假设的回响。与人工智能的合作凸显了尊重这些跨度对于理解和操作代码至关重要。人类指导和人工智能协助之间的相互作用需要明确的上下文管理、清晰的沟通和适应性。
在这个过程中,编程具有讲故事的品质,因为合作者之间的无缝流动反映了叙述的节奏。考虑 Sharvit Yehonathan 的假设:
- 代码难以阅读的原因是它不尊重我们的大脑跨度。
- 记忆跨度。
- 注意力跨度。
- 结构跨度。
从这些传奇特性中,我们可以得出 Sharvit 的三个基本准则:
- 保持函数小巧。
- 使用单一抽象层。
- 为函数提供描述性名称。
对于 AI 反转,我会将“阅读”翻译为“理解和操作”,并强调高度交错的协作如何放大尊重 AI 边界和认知边缘的需要。用 Sharvit 的三个 AI 提示语言基本准则来解释:
- 在每个提示中将任务分解为小的功能块。
- 除非明确定义,否则避免依赖私有抽象或自定义术语。利用 LLM 可能从其培训中理解的广泛认可的抽象。
- 与 LLM 协作迭代以引入设计描述性名称和你使用的代码块中注释的准确性,以提高清晰度和共享理解。
使用生成式人工智能讲故事似乎也需要主动“倾听”。 如果模型始终倾向于特定的解决方案,则可能并不表明方法更好,而是反映了其训练——它对数据中这些模式的接触。 虽然可以将人工智能引向不太传统的方法,但这些路径可能会带来更高的风险——你应该为此做好准备——因为其训练中支持它们的示例较少。
通过平衡清晰的沟通、深思熟虑的迭代以及对人工智能和我们的局限性的认识,我们可以在这个混合问题解决过程中发现新的见解,该过程将人类直觉与 LLM 广泛而结构化的协作风格相结合。
有关更多详细信息,请访问此 GitHub 获取其他帖子和文章的链接。
原文链接:Software Development with ChatGPT o1-preview: A Brain-Spans Approach
汇智网翻译整理,转载请标明出处
