4个OCR库的对比工具
我偶然发现了一个huggingface 空间,它允许你比较四种 OCR开发库之间的文本识别结果。

你可能知道有很多开放且可免费使用的光学字符识别引擎。但要了解它们之间的性能关系并不容易跟踪或测试。我曾见过类似的说法:
- 在 CPU 上使用 Tesseract,但如果有 GPU 可用,请使用 EasyOCR
- Tesseract 在单个字符上表现出色,而 EasyOCR 在完整单词上效果最佳。
这是真的吗?我会向你展示一个工具来帮助你找出答案。
我偶然发现了这个由 Laurence Dewaele 制作的 huggingface 空间,它允许你比较这四种 OCR 方法之间的文本识别结果:
- Tesseract OCR。Tesseract OCR 是一款免费的开源光学字符识别引擎,由惠普开发,后来由谷歌维护,于 2014 年发布了一次重大更新(Tesseract 3.0),并于 2018 年发布了另一次更新(Tesseract 4.0)。
- EasyOCR。EasyOCR 由 Jaided AI 开发,这是一支专门开发计算机视觉和机器学习应用程序的软件工程师团队。EasyOCR 的第一个版本于 2019 年 8 月发布,从那时起,它在使用 OCR 技术的开发人员、研究人员和学生中广受欢迎。
- MMocr。MMOCR(多模态光学字符识别)是由 OpenMMLab 开发的开源 OCR(光学字符识别)项目。它于 2020 年首次发布,由于其在识别图像和视频中的文本方面具有很高的准确性而广受欢迎。
- PaddleOCR (PPOCR)。基于 PaddlePaddle 的多语言 OCR 工具包(实用的超轻量级 OCR 系统,支持 80 多种语言识别,提供数据注释和合成工具,支持在服务器、移动、嵌入式和物联网设备之间进行训练和部署)
我从 FUNSD 数据集上传了一个测试图像。该过程分为两个阶段。首先,每个 OCR 解决方案都会对页面进行文本检测。这将返回带有它发现的单词/片段位置的边界框。虽然它们都支持多种语言,但我在这里只测试英语。我将超参数保留为默认值,(徒劳地)希望开发人员已经找到了最常见场景的最佳设置。
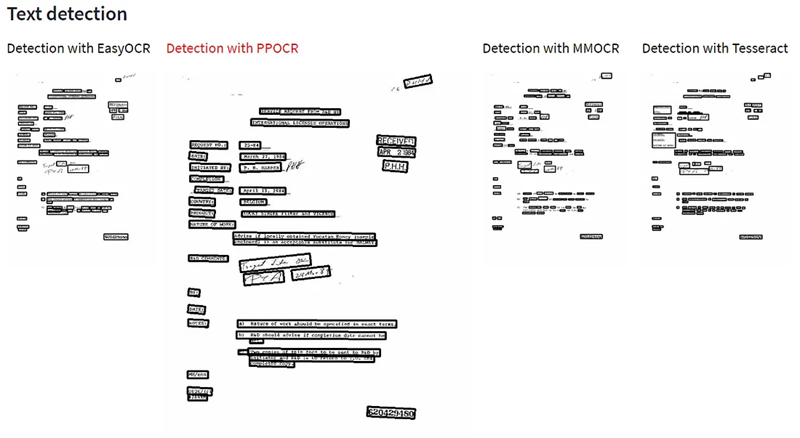
然后向你展示文本检测的结果。你能发现差异吗?
让我们详细了解一下:




观察:
Tesseract 似乎遗漏了文本,并破坏了一些属于不同框的单词。在较小程度上,MMOCR 也存在同样的问题。我认为 EasyOCR 和 PPOCR 在这方面不相上下,但我喜欢 PPOCR 是唯一一个有倾斜(而不是直)框的。
为什么文本检测很重要?因为 OCR 解决方案不是对整个页面进行识别,而是对发现文本的这些框进行识别。布局感知对获得更准确的 OCR 结果有很大帮助。下一步是选择我们将使用四种文本检测中的哪一种来将这些结果提供给实际识别步骤。我选择了 Paddle OCR,同样对每个 OCR 实现使用默认参数。
以下是一些结果:
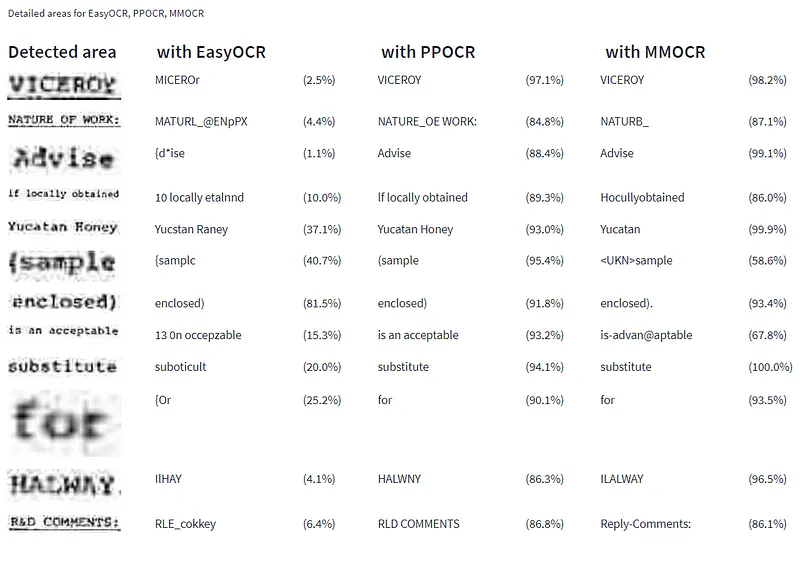
在这种情况下,PPOCR 似乎胜出。单词下面的线条对于 OCR 来说可能非常困难。在最后一个例子中,MMOCR似乎编造了单词,例如“回复”而不是“研发”。也许它默认使用字典。
Tesseract OCR 需要使用自己的检测,因此不幸的是,结果不能完全一对一地进行比较。下面的结果出奇地糟糕。
结论:
很难比较 OCR 解决方案,因为它们在不断发展,而且远不止我在这里谈论的四种。我尝试的上述文档只是一个样本,使用默认参数。所以对这些结果持保留态度。(或持保留态度)我必须提到,这也取决于 OCR 应用程序。一种解决方案可能更适合文档,而另一种解决方案更适合读取车牌等内容。Laurence Dewaele 的 🤗 空间在这方面确实有所帮助。试试吧!
原文链接:OCR comparison: Tesseract versus EasyOCR vs PaddleOCR vs MMOCR
汇智网翻译整理,转载请标明出处
