高效构建多模态数据集
本文介绍一个生成多模态数据集的管道。该管道的主要目标是无需人工标注即可工作。

在解决深度学习问题时,通常会本能地修改现有架构以适应任务,甚至考虑从头开始设计一个新架构。
正如在 AI 模型中的“它”是数据集中所强调的那样,改进深度学习模型的最重要杠杆依赖于训练数据而不是架构本身。拥有适合特定用例的数据可以显著提高该用例的模型性能。
因此,要问的第一个问题是“我的模型将有哪些应用案例?”。
例如,在自然语言处理 (NLP) 中,确定使用的语言至关重要。从这些指标中我们可以看出,用英语训练的模型不一定在其他语言中是最有效的。这是这篇文章中描述的领域适应的一个例子。
评估用英语训练的模型在其他语言应用中的性能通常会产生比直接用该其他语言进行训练更差的结果。
此外,拥有与你的应用程序相同领域的高质量数据有利于使用微调或 LoRA 专门化模型。
基于这一观察,建议通过明确定义应用案例来开始解决问题,以便构建自己的数据集。
构建自己的数据集不是太耗时吗?
事实上,创建数据集可能很繁琐、耗时且成本高昂。例如,数据通常需要手动注释。
为了应对标注挑战,有一个解决方案:合成数据。
这个想法是使用自动生成数据或标签的外部模型。
通过将 Python(或您首选的编程语言)提供的工具与来自预先存在的模型 API 的工具相结合,可以自动为各种任务创建数据集。
本文的目标
我们在此介绍一个生成多模态数据集的管道。该管道的主要目标是无需人工标注即可工作。
为了说明此流程,本文建议自动为英语以外的语言幻灯片创建用于视觉信息检索和文档视觉问答 (DocVQA) 的数据集。
可以是法语或其他语言,在本例中,我们将使用西班牙语。
我们的目标是借助合成数据创建特定用例的数据集。主要目标是使用自动协议来创建它。因此,只要有足够的资源,就可以创建所需大小的数据集。
- 任务定义:什么是视觉信息检索和 DocVQA?
- 数据集构建:我们的数据集示例的结构是什么。
- 代码:如何构建我们的数据集。
- 性能:将此方法与人工标注进行比较
所有脚本和数据均可在 github.com/AlexMY1/dataset 上找到。
1、任务定义
我们的目标是建立一个西班牙语幻灯片数据集,以训练和评估文档视觉问答和视觉信息检索模型。
文档视觉问答是基于视觉文档(pdf、幻灯片等)回答问题的任务。
我们输入图像和问题,输出答案。因此,我们的数据集必须包含幻灯片图像以及问答功能。
视觉信息检索是从大量文档和问题中识别哪些文档可以回答问题的任务。
2、数据集构建
为了构建合适的数据集,我们提出了以下流程:
- 选择西班牙语幻灯片的来源并检索原始数据。
- 使用文本/图像模型(Gemini、Claude、ChatGPT 等)的 API 生成问题/答案。
- 将收集和合成的数据组织成可共享的格式。
- 过滤数据以删除低质量样本。
我们使用无版权的演示幻灯片网站(如 Slideshare.net)作为数据源。可以选择演示文稿中使用的语言,使其完美地适合我们的问题。
2.1 合成数据挑战
通过结合两个元素,可以实现此过程的自动化:通过抓取方法自动收集数据和通过 VLM(可视化大模型)自动生成数据。
这些合成数据是构建数据集的资产,因为它们提供:
- 节省时间:模型 API 自动生成问题/答案。
- 节省资金:无需人工注释数据。
论文 ChatGPT 在文本标注任务方面的表现优于众包工作者 重点介绍了这一挑战。
2.2 数据集组织
演示文稿由一张或多张幻灯片组成。在分析每张幻灯片演示文稿的可用数据后,我们对数据集进行了分析,使其包含以下特征:
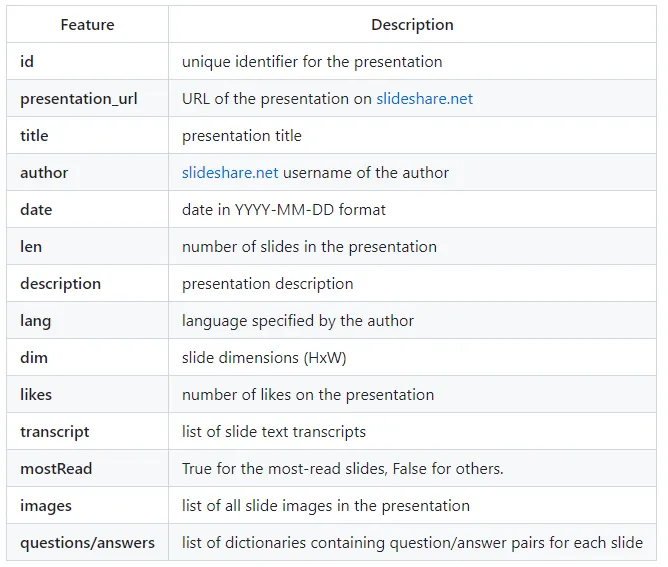
此列表包含每张幻灯片的问题/答案对(一张幻灯片可能有多个问题/答案对)。
3、代码
例如,我们将收集和标注一百份文档,但代码可以轻松通过延长运行时间,很容易地扩大规模以处理数千个文档。
我们使用 3 个 Python 笔记本和一个 Python 脚本,可在 github/AlexandreMyara 上找到。
代码组织如下:
scrap.ipynb:此笔记本检索不同演示文稿的下载链接,然后逐张下载每张幻灯片。generate_qa.ipynb:此笔记本为每个下载的幻灯片生成一个或多个问答对。filter.ipynb:此笔记本加载数据集并删除太短的问答对或幻灯片太少的演示文稿。
最后, dataset.py 以 HuggingFace 的数据集格式生成数据集。
3.1 抓取
使用 Python 模块,我们向演示文稿网站发出请求。我们检索包含关键字“西班牙语”的各种演示文稿的 URL。
收集这些 URL 后,下载幻灯片。
每个幻灯片演示文稿都存储在一个文件夹中,其中包含该演示文稿的所有幻灯片。
我们还保存了一个包含演示文稿元数据(标题、作者、ID 等)的 .json 文件。

3.2 问题/答案生成
现在我们生成合成数据,特别是每张幻灯片的问题/答案对。
为此,我们选择一个带有可免费访问 API 的 VLM。
例如,我们可以使用 Claude 或 Gemini API。
选择模型后,我们输入幻灯片以及提示,例如:
prompt = “Generate a question-answer pair in the format {question:, answer:}. The question should be based on the slide and be instructive, using visual elements to form the question and answer.”``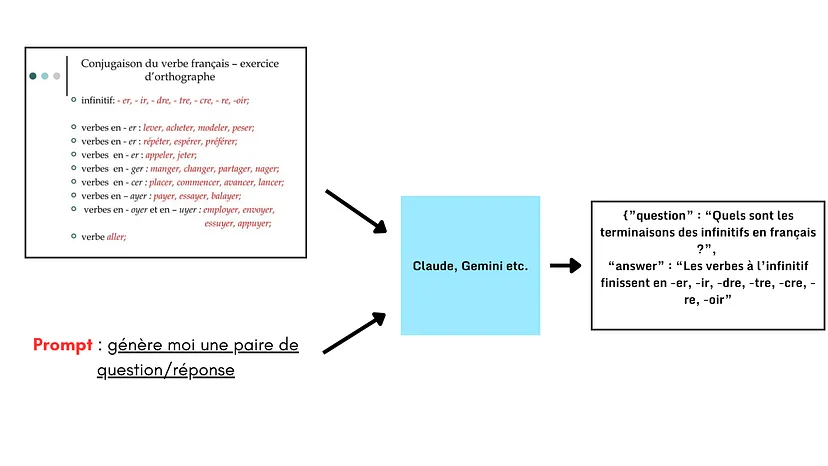
为了满足视觉信息检索的需求,生成的问题/答案(合成数据)必须关注幻灯片的特定或独特元素。
我们验证每个问题/答案对是否清楚地标识了相应的幻灯片。
对于每个演示文稿,我们将问题/答案对列表以 .json 格式存储在与演示文稿关联的文件夹中。
3.3 数据集格式
收集数据后,我们将以 Dataset 格式生成数据集并保存在 parquet 文件中。
为此,我们使用带有 Python Generator 的脚本来生成 HuggingFace 数据集。
数据集示例可以从这里获得。
然后可以使用 HuggingFace 的 load_dataset 函数加载数据集并用于模型评估等。
3.4 数据过滤
为了提高数据质量,可能需要检查合成数据的相关性。
我们手动检查几个问题/答案对,并检查它们与相应幻灯片的一致性。
接下来,我们排除以下任何演示文稿:
- 问题或答案少于 10 个字符。
- 幻灯片少于 3 张。
此时,我们的数据集质量更高。
4、性能
让我们讨论一下这种方法的性能以及使用合成数据的相关性。
4.1 抓取时间
幻灯片是使用 HTTP 请求检索的。使用 Python,可以在 12 分钟内检索 10 个演示文稿,每个演示文稿有 20 张幻灯片,以及它们的 .json 格式的元数据。这个时间包括暂停,以避免网站被请求淹没。

由于需要组织元数据,手动下载将花费更长时间。因此,这种方法提供了第一个节省时间的优势。
4.2 问答生成时间
这种方法的最大优势在于使用合成数据。
通常,数据标注需要为更机械的任务支付众包工人的费用。
基于 Amazon Mechanical Turk 或 Appen 等平台,我们可以估计人工标注至少需要 0.50 美元。
因此,对于 10 个包含 20 张幻灯片的演示文稿,成本约为 100 美元。
相比之下,使用 Claude 3.5 Sonnet API 对 10 个包含 20 张幻灯片的演示文稿进行合成标注需要花费我们 0.50 美元。
对于 200 对合成问题/答案,Gemini API 需要 4 分钟,这很可能比人工标注更快。


为了提高生成问题/答案的时间性能,我们可以在生成问答之前对演示长度进行数据过滤。
5、结束语
我们已经成功地使用合成数据为文档视觉问答和视觉信息检索的特定应用生成了一个数据集。
以下是性能摘要:
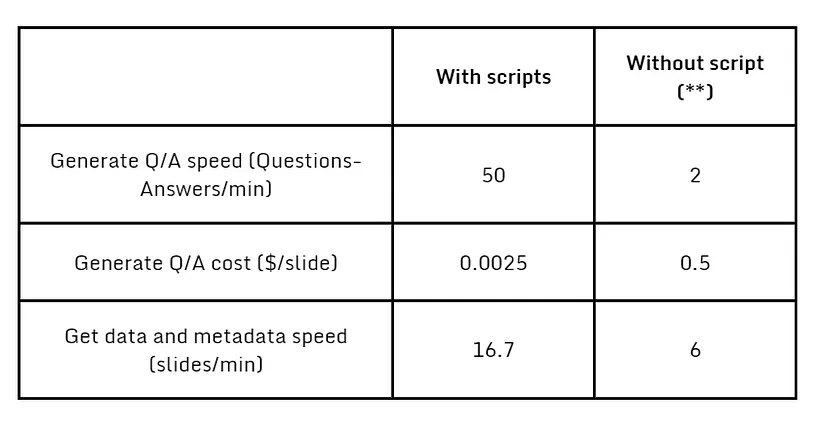
我们在 3k 张幻灯片时停止了算法,但只要有足够的时间,我们仍然可以在我们的数据集中获得更多示例。
除了由于自动化而节省的时间外,我们还注意到财务成本,这有利于合成数据。为了评估该方法的性能,我们最终生成了一个包含 3,000 张幻灯片的数据集。合成数据的质量使我们能够在根据返回响应的长度进行过滤后,保留 77% 的生成数据。
如果数据检索和合成生成时间增加,此协议可以构建更大的数据集。
该数据集与现实世界的应用非常相似,将优化我们模型的评估。
原文链接:How to construct multimodal dataset efficiently ?
汇智网翻译整理,转载请标明出处
