用Deepseek-R1蒸馏自己的模型
在今天的文章中,我将介绍如何通过创建本地版本的Deepseek-R1、定制LLM,并将其无缝集成到你的Python脚本中来实现这一点。

我不认为有必要介绍生成式人工智能的能力,自从2018年GPT-1发布以来,大型语言模型(LLMs)已经越来越多地融入我们的日常生活。我们大多数人都通过网页或应用界面与它们互动,可以在聊天界面中提问并获得答案。这种方法在你需要解决代码中的错误或获取意大利面博洛尼亚酱的食谱时非常有效,但在尝试将自定义LLMs集成到自动化管道并在数据集上运行操作时则不太适用。在今天的文章中,我将介绍如何通过创建本地版本的Deepseek-R1、定制LLM,并将其无缝集成到你的Python脚本中来实现这一点。
上个月,Deepseek发布了其最新的LLM产品,引起了极大的兴奋,震撼了科技界。除了Deepseek-R1,团队还发布了几个不同大小的精馏模型变体。由于模型蒸馏过程将知识从较大的LLM转移到较小的容器化模型中;开发人员可以更高效和硬件无关的方式利用LLMs进行本地化,并享受其推理能力带来的好处。拥有本地版本的一个重要优势是数据隐私。因为你不需要像服务那样通过API调用来发送和接收消息,所以你的流程会在本地运行并与Deepseek模型的本地实例交互。这意味着这种方法具有增强的隐私性(并且可以完全离线运行)。
首先,你需要将Ollama安装到你的本地机器上。这可以通过导航到www.ollama.com并点击下载按钮轻松完成。接下来的屏幕会提供给你选择最符合你系统的安装程序的选项,然后只需按照该下载过程进行操作即可。
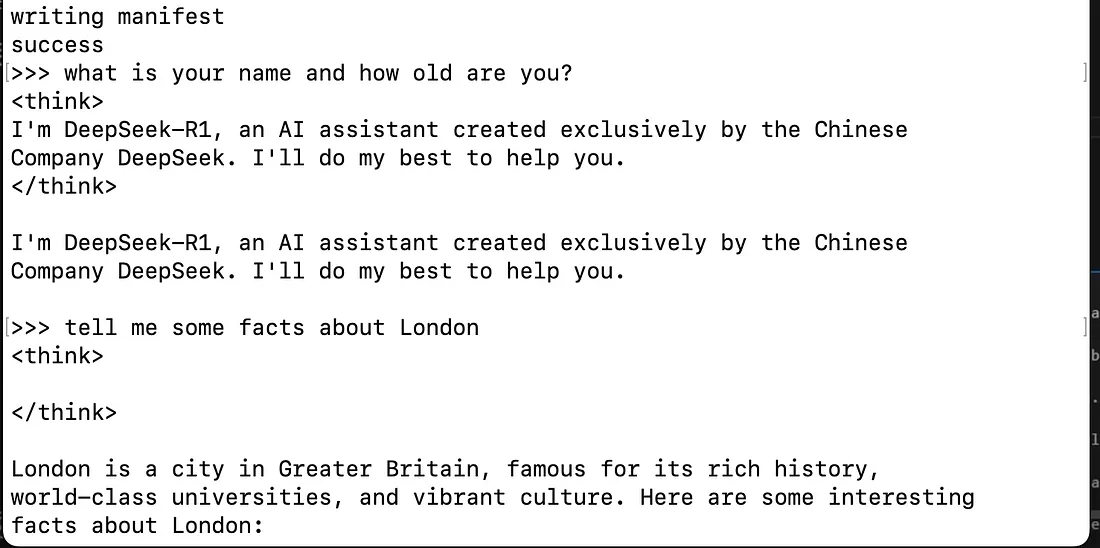
完成后(假设你使用的是Macbook),通过“command + 空格”打开终端,输入Terminal以打开一个新的shell窗口,并简单地指示Ollama上传你所需的精馏Deepseek-R1模型。由于我的用例并不复杂,我选择了最小的模型,即DeepSeek-R1-Distill-Qwen-1.5B。一旦执行“ollama run deepseek-r1:1.5b”命令,你会看到正在上传到你的机器上的拉取过程。

安装本地实例的deepseek-r1:1.5b模型。确保指定正确的模型。我的第一次下载不是正确的那个,需要通过使用command+c来终止。
令人难以置信的是,一旦上传完成,你可以立即在终端窗口中开始与模型互动。只需在>>>后面直接写入你的提示,就可以开始与你的模型的本地版本互动。
因为我们希望在Python脚本中使用这个模型,现在我们需要上传Ollama Python库,该库提供了许多与已安装模型交互的辅助函数。理想情况下,在你的工作虚拟环境中(或全局安装在你的机器上),通过使用命令‘pip install ollama’下载该库。
如果库已经在你的工作环境中安装,你会看到‘Requirement already satisfied:’如上所示。否则,pip将继续安装库。
现在让我们确保我们可以通过VSCode中的笔记本与模型交互,就像我们在终端中一样。导航到VSCode,打开一个新笔记本,并双检查你选择用于运行笔记本的内核是否是包含所有已安装库的正确实例。
from ollama import chat
from ollama import ChatResponse
response: ChatResponse = chat(model="deepseek-r1:1.5b", messages=[
{
"role": "user",
"content": "what is ketchup made out of?"
}
])
print(response['message']['content'])
上述代码的作用是通过字典定义角色和提示问题向你的模型发送消息。我们可以看到基于我对“番茄酱是由什么制成的?”这个问题的回答,Deepseek模型的对话性质。
<think>
好的,用户问的是番茄酱是由什么制成的。我知道番茄酱是一种常见的调味品,所以可能是由番茄制成的。但也许还有更多内容。
我记得番茄在植物学中被分类为红色或黄色。这可能会影响酱料的类型。让我想想——红色番茄通常用于番茄酱等番茄基酱料,因为它们的皮较软,风味也不同。
而且我认为番茄酱是一种甜的调料。所以可能不仅仅是番茄,还含有糖或其他成分,如蜂蜜,以制成这种酱料。
等等,我在想是否有其他常见的调味品也是由番茄制成的。也许是洋葱或大蒜?或者醋或其他酸性物质参与其中?
不,番茄酱听起来并不是用苹果醋之类的酸性物质制成的。那听起来更酸,不符合甜味。所以我认为它主要是番茄基的,特别是红色番茄。
我也应该考虑其他蔬菜,但在这里可能不相关,因为问题是关于番茄酱的。也许只是添加一些细节关于它是如何制作的——比如加入盐和胡椒,或许加些糖或蜂蜜以增强风味。
所以综合起来:番茄酱来自红色番茄,这些番茄通常是软的且风味丰富。它通过溶解番茄汁制成一种甜味、略带酸性的调料,可以热吃也可以冷吃。
</think>
番茄酱通常由红色番茄制成,这些番茄在美国南部很常见。这种酱汁浓郁、酸甜可口,因为它的番茄汁含有甜味和轻微的酸味。番茄酱通过溶解番茄汁制成一种可以热吃也可以冷吃的调料。它常被用作许多菜肴的蘸料,在全世界都很受欢迎。
我们可以看到,模型的响应结构可以分为两部分,思维链被包含在 | 之间,而实际的响应则位于输出字符串的后半部分。
我真希望能看到一部更新版的《深海猎人》系列,结合今天的技术,这将唤起我心中的孩子气。
我是在黑白电视上长大的,《深海猎人》和《枪烟》是我的每周英雄。
我希望《深海猎人》能重新归来,我们需要改变一下电视节目的节奏,这部剧适合讲述水下冒险的故事。
顺便说一句,感谢你们提供这样一个平台,让我可以看到很多关于电视和电影的观点。
所以无论如何,我想我已经说出了我想说的话。如果能读到更多关于《深海猎人》的优点就更好了。
如果我的诗有十行,你会让我提交吗?还是让我感到怀疑并放弃?如果是这样,那我就必须走了,让我们这样做吧。
为了展示模型如何在Python脚本中使用,我在网上找到了一个包含对电影的长篇评论的数据集;上面显示的就是数据集中捕获的一个意见示例。为了举例说明,我希望模型能够遍历我的数据集,理解每个意见的情感,并从-5到5对每个意见进行排名,并将其添加到新的列中。我希望利用模型响应的两个部分,对于数据集中每个意见字符串,我还希望添加一个列,提供模型关于为什么给出特定分数的思考。
import re
import pandas as pd
import openpyxl
def ask_deepseek(input_context, system_prompt, deep_think = True, print_log = True):
response: ChatResponse = chat(model="deepseek-r1:1.5b", messages=[
#我们发送的提示由两部分组成,系统和输入
{"role": "system", "content": system_prompt},
{"role": "user", "content": input_context}
])
response_text = response['message']['content']
if print_log: print(response_text)
# 提取<think>...</think>之间的所有内容 - 这是深度思考
think_texts = re.findall(r'<think>(.*?)</think>', response_text, flags=re.DOTALL)
# 如果存在多个<think>部分,则连接提取的部分
think_texts = "\n\n".join(think_texts).strip()
# 排除深度思考,返回响应
clean_response= re.sub(r'<think>.*?</think>', '', response_text, flags=re.DOTALL).strip()
# 返回上下文,或者返回包含上下文和深度思考的元组
return clean_response if not deep_think else (clean_response, think_texts)
#从我的本地机器检索我的电影意见数据集并转换为DataFrame
file_path = '/Users/assel/Downloads/facts_opinions.csv'
df = pd.read_csv(file_path)
#截断DataFrame以使其更适合提示工程
df = df[:30]
#生成要提供给模型的任务提示
system_prompt_sentiment = '''你将获得一个包含对电影评论的数据集。
用户对电影给出了他们的意见,你需要根据用户的意见对每条评论进行评分。
情感评分范围为-5(非常负面)到5(非常正面)。
请仅回答评分,不要在评分前后添加任何其他单词或解释。
如果评分是正数,不要在输出中包括'+'符号,但如果评分是负数,请包括'-'符号。
'''
#要求模型根据逻辑对每个意见进行排名,并将结果添加到新的列中
df[['LLM_SENTIMENT', 'LLM_DEEP_THINK']] = df['Text'].apply(lambda opinion: ask_deepseek(opinion, system_prompt_sentiment)).apply(pd.Series)
在上述代码对我的代码中的30个样本运行之后,下面是模型给出的响应示例:
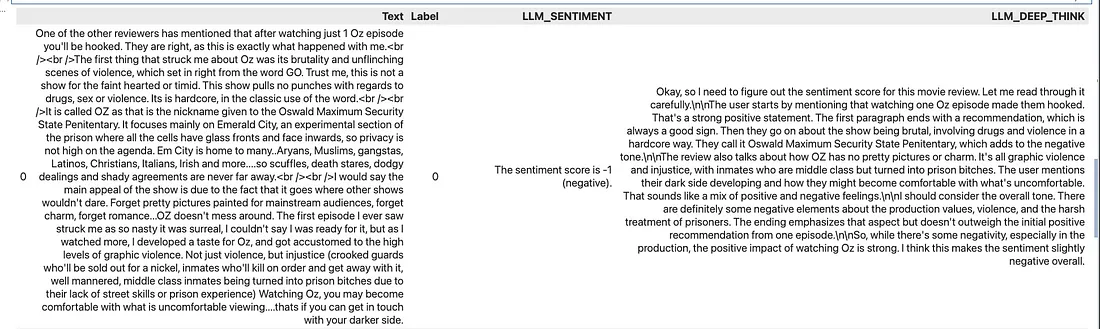
通过使用pandas的apply()函数,我可以使用上述指定的函数针对数据框中的所有行运行模型,并结合辅助系统提示来帮助指导模型产生正确的输出。
阅读这些评分,它们似乎合理,逻辑链也非常全面。为了处理30条意见文本,模型用了5.09分钟来执行。通过一些提示工程,我相信还可以改进模型的延迟和输出质量,然而提示优化是一个广泛的和复杂的艺术形式,最好留待另一篇文章讨论。
总之,上述指南为你提供了一个简单的方法来创建最新精馏Deepseek-R1模型的本地私有实例,并展示了如何创建自定义提示以在自己的数据上以可扩展的方式运行。虽然我使用模型进行了情感分析,但还有许多其他应用,如提取、翻译和其他推理形式都可以使用上述演示的过程来实现。
汇智网翻译整理,转载请标明出处
