ComfyUI自定义节点开发

ComfyUI 是 Stable Diffusion 的强大而灵活的用户界面,允许用户通过基于节点的系统创建复杂的图像生成工作流程。虽然 ComfyUI 带有各种内置节点,但其真正的优势在于可扩展性。自定义节点使用户能够添加新功能、集成外部服务并根据其特定需求进行定制。
在这篇博文中,我们将介绍使用 ComfyUI 创建用于图像字幕的自定义节点的过程。此节点将以图像作为输入,并使用外部 API 返回生成的字幕。
我们将使用 Google Gemini API 生成图像的字幕。
1、自定义节点的完整代码
这是使用 Gemini API 执行 ImageCaptioning 的完整代码。
你可以将以下代码复制到 ComfyUI 中 custom_nodes 文件夹下的任何文件中,我将我的文件命名为 gemini-caption.py :
生成图像标题的完整代码:
import numpy as np
from PIL import Image
import requests
import io
import base64
class ImageCaptioningNode:
@classmethod
def INPUT_TYPES(s):
return {
"required": {"image": ("IMAGE",), "api_key": ("STRING", {"default": ""})}
}
RETURN_TYPES = ("STRING",)
FUNCTION = "caption_image"
CATEGORY = "image"
OUTPUT_NODE = True
def caption_image(self, image, api_key):
# Convert the image tensor to a PIL Image
image = Image.fromarray(
np.clip(255.0 * image.cpu().numpy().squeeze(), 0, 255).astype(np.uint8)
)
# Convert the image to base64
buffered = io.BytesIO()
image.save(buffered, format="PNG")
img_str = base64.b64encode(buffered.getvalue()).decode()
api_url = f"https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent?key={api_key}"
payload = {
"contents": [
{
"parts": [
{
"text": "Generate a caption for this image in as detail as possible. Don't send anything else apart from the caption."
},
{"inline_data": {"mime_type": "image/png", "data": img_str}},
]
}
]
}
# Send the request to the Gemini API
try:
response = requests.post(api_url, json=payload)
response.raise_for_status()
caption = response.json()["candidates"][0]["content"]["parts"][0]["text"]
except requests.exceptions.RequestException as e:
caption = f"Error: Unable to generate caption. {str(e)}"
print(caption)
return (caption,)
NODE_CLASS_MAPPINGS = {"ImageCaptioningNode": ImageCaptioningNode}
节点在 UI 上的外观如下:
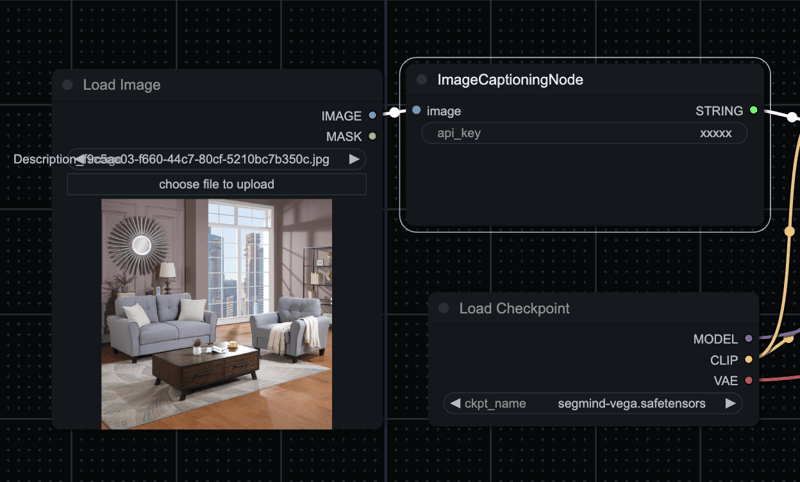
让我们逐行查看,了解如何为你的用例创建类似的节点。首先,无论你要创建什么节点,都将其作为函数,这样你就可以在 ComfyUI 中以相同的方式调用它,就像我在这里对 caption_image 函数所做的那样。
2、导入所需的必要库
import numpy as np
from PIL import Image
import requests
import io
import base64这些行导入我的图像字幕节点所需的库:
- numpy 用于数值运算
- PIL(Python 图像库)用于图像处理
- requests 用于向 Gemini API 发出 HTTP 请求
- io 用于处理字节流
- base64 用于编码图像
3、为 ComfyUI 节点定义 ClassName
class ImageCaptioningNode:
@classmethod
def INPUT_TYPES(s):
return {
"required": {"image": ("IMAGE",), "api_key": ("STRING", {"default": ""})}
}
在我的例子中,我将其命名为 ImageCaptioningNode,因为它的作用与它所说的一样。
类方法定义我们节点的输入类型:
- “IMAGE”类型的“image”输入
- “STRING”类型的“api_key”输入,默认为空值,用于向 Gemini API 发送 API 请求。
RETURN_TYPES = ("STRING",)
FUNCTION = "caption_image"
CATEGORY = "image"
OUTPUT_NODE = True这些类变量定义:
- 返回类型(字符串)
- 要调用的主要函数(“caption_image”)
- 节点在 ComfyUI 中出现的类别
- 此节点可以是输出节点
def caption_image(self, image, api_key):
# Convert the image tensor to a PIL Image
image = Image.fromarray(
np.clip(255.0 * image.cpu().numpy().squeeze(), 0, 255).astype(np.uint8)
)
# Convert the image to base64
buffered = io.BytesIO()
image.save(buffered, format="PNG")
img_str = base64.b64encode(buffered.getvalue()).decode()
api_url = f"https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent?key={api_key}"
# Prepare the request payload
payload = {
"contents": [
{
"parts": [
{
"text": "Generate a caption for this image in as detail as possible. Don't send anything else apart from the caption."
},
{"inline_data": {"mime_type": "image/png", "data": img_str}},
]
}
]
}
try:
response = requests.post(api_url, json=payload)
response.raise_for_status()
caption = response.json()["candidates"][0]["content"]["parts"][0]["text"]
except requests.exceptions.RequestException as e:
caption = f"Error: Unable to generate caption. {str(e)}"
print(caption)
return (caption,)这是我编写的一个独立函数,它将图像作为输入,并使用 API 密钥将其发送到 Gemini API。代码很简单,我们只是进行 base64 编码,以便通过 API 发送图像。我们指示 Gemini 使用提示为图像添加详细的标题。API 的响应被解析,并打印在控制台中并作为元组返回(ComfyUI 需要)。
NODE_CLASS_MAPPINGS = {"ImageCaptioningNode": ImageCaptioningNode}此字典将类名映射到类本身,ComfyUI 使用它来注册自定义节点。
为了结束关于创建自定义 ComfyUI 节点的文章,你可以总结要点并提供一些最后的想法。以下是建议的结论:
4、结束语
为 ComfyUI 创建自定义节点为扩展和增强图像生成工作流程开辟了无限的可能性。在本文中,我们介绍了构建自定义图像字幕节点的过程,并演示了如何:
- 定义输入和输出类型
- 与外部 API 集成(在本例中为用于图像字幕的 Gemini API)
通过遵循这些步骤,你可以创建自己的自定义节点,以向 ComfyUI 添加几乎任何你需要的功能。无论你是集成新的 LLM 模型、添加专门的图像处理技术,还是为常见任务创建快捷方式,自定义节点都允许你根据特定要求定制 ComfyUI。
请记住,虽然我们在此示例中专注于图像字幕,但可以应用相同的原则来为各种任务创建节点。关键是要了解 ComfyUI 节点的结构以及如何与预期的输入和输出进行交互。
原文链接:How to create custom nodes in ComfyUI
汇智网翻译整理,转载请标明出处
