基于CrewAI的合成数据生成
本文介绍了一个使用 CrewAI 代理生成合成数据的综合框架。通过模拟基于代理的交互,CrewAI 使我们能够生成针对特定任务量身定制的真实数据集,从而显著提高机器学习模型的性能。

很多时候,在使用不同的 AI 代理框架时,我们对模型性能并不满意。通常,我们需要一个在特定领域或领域中工作的 AI 代理解决方案。模型本身也可能如此。
本文介绍了一个使用 CrewAI 代理生成合成数据的综合框架,以应对这些挑战。通过模拟基于代理的交互,CrewAI 使我们能够生成针对特定任务量身定制的真实数据集,从而显著提高机器学习模型的性能。本详细指南将引导你完成整个过程,从设置环境到生成和使用合成数据来微调模型。
开源模型(例如 Mistral、Llama 3、Phi-3 等)通过提供可以轻松针对特定任务进行微调的预训练模型,在 AI 民主化方面发挥了至关重要的作用。
然而,这些模型的性能高度依赖于训练数据的质量和相关性。在特定领域的数据集上对预训练模型进行微调已成为一种重要的技术,可使它们适应特定任务并提高其准确性(Radford 等人,2018 年)。传统的数据收集方法通常涉及手动标记和注释,这既耗时又昂贵,而且在场景多样性和覆盖范围方面也受到限制(Nikolenko,2019 年)。
如今,使用许多不同的框架(例如 Ollama、HuggingFace Transformers、crewAi 代理),可以将模型微调到你的特定领域或用例。
使用微调模型还有其他优势,例如推理成本。
1、概述
我提出的框架是通用的,可以轻松适应不同领域的不同用途。我将连同用于这样做的 Python 代码一起解释它。我将仅提供微调和 CrewAI 框架的一个非常基本的介绍。
本文提供的代码只是我将用来进一步启发你的一个例子。任何实现都需要根据你的特定需求进行调整。但我当然希望你能从中得到一些乐趣。
1.1 微调模型
微调是人工智能领域的一个关键概念,尤其是在使用大型语言模型 (LLM) 时。它指的是采用已在大型数据集上进行预训练的模型并将其定制为特定的、通常更窄的任务的过程。这是通过在包含与任务或感兴趣的领域更相关的示例的新数据集上继续训练过程来实现的。
微调是一种涉及在特定于特定任务或领域的较小数据集上训练预训练模型的技术。通过利用从大规模预训练中获得的知识,微调允许模型以最少的训练数据适应新任务。
有几种微调方法,但数据集起着至关重要的作用。如果你很幸运,你会有一个由真实观察构建的数据集。即使是这样,你可能仍然需要人为地创建一个更大的数据集来执行有效的微调。
微调是一种过于复杂的方法——在本文中,我们重点介绍数据集生成。因此,我们跳过了数据清理、数据测试等步骤,因为这些步骤因情况而异。
1.2 crewAI 框架
crewAI 是一个用于模拟基于代理的交互的框架,这使其成为生成合成数据的理想选择。通过创建具有特定角色、目标和任务的代理,crewAI 可以生成真实的交互,在我们的案例中,这些交互可以为机器学习模型提供有价值的训练数据。
该框架支持多种功能,可提高 AI 代理的功能和适应性。例如,可以使用特定角色、目标和工具定制 crewAI 中的代理,它们可以使用这些角色、目标和工具来动态执行分配的任务。这种基于角色的代理设计有助于创建一个多才多艺、高效的 AI 代理团队,每个代理都为系统的总体目标做出贡献。
crewAI 还集成了各种工具(自定义或 LangChain 专有工具)来增强代理的能力,从数据分析软件到创意辅助工具,从而增强他们高效执行分配任务的能力。
1.3 crewAI 的核心组件
crewAI 围绕几个核心组件构建,这些组件共同模拟真实的交互并生成高质量的合成数据。这些组件包括:
- 代理(Agent)
代理是 crewAI 中的主要实体。每个代理都被分配了一个特定的角色、目标和背景故事,这些角色、目标和背景故事定义了其在模拟中的行为和交互。代理可以代表不同的专业角色,使交互更加真实和多样化。
- 任务(Task)
任务是分配给代理的特定目标或行动。每个任务都包括详细描述和预期结果。任务旨在模拟现实世界的工作职能,并提供一种结构化的方式来生成用于模型训练的相关数据。
- 团队(Crew)
团队是代理和任务的集合。它管理代理之间的交互,并确保按照预定义的流程执行任务。Crew 组件促进代理交互的协调和执行,在此过程中生成合成数据。
- 流程(Process)
流程定义如何执行任务以及代理如何交互。crewAI 支持不同类型的流程,例如顺序或并行执行,从而允许灵活的模拟场景。流程确保以有组织的方式执行交互,从而产生一致且可靠的数据生成。
这是一个很棒的项目,不断添加新功能,并在 Github 上完全开源(还构建了企业专用服务)。我只做了一个非常简短的解释来帮助你理解这个概念。有关如何使用 crewAI 的更多详细信息和实用指导,你可以浏览其文档。
1.4 为什么要使用代理进行微调
使用代理进行微调具有多种优势,可以改善机器学习模型的整体训练过程:
- 真实的交互
代理可以编程为具有特定角色、目标和背景故事,从而创建反映真实世界场景的真实交互。这可以生成更真实、更多样化的数据集。
- 受控环境
通过使用代理,我们可以控制交互的参数,确保生成的数据与当前任务相关且特定。这种受控环境有助于生成高质量数据,而不会出现现实世界数据中经常出现的噪音和不一致。
- 可扩展性
基于代理的模拟可以轻松扩展以快速生成大量数据。这对于需要大量数据集才能实现高性能的微调模型特别有用。
- 可重用性
创建后,代理及其交互可针对不同的任务和场景进行重用和修改,从而为持续数据生成和模型改进提供灵活且可重用的框架。
2、使用 crewAI 生成合成数据集
如前所述,在本文中我们将重点介绍数据集生成。微调是一个单独的主题,值得单独写一篇文章。但是,我也提供了微调和使用微调模型的代码,但请将其视为说明性的。它有效但不是最佳的。还必须根据特定用例选择特定的微调方法。
因此,主要思想是生成特定于特定领域的代理和任务,并使用 crewAI 框架执行交互以收集代理工作的输出作为我们数据集的元素。见下图。
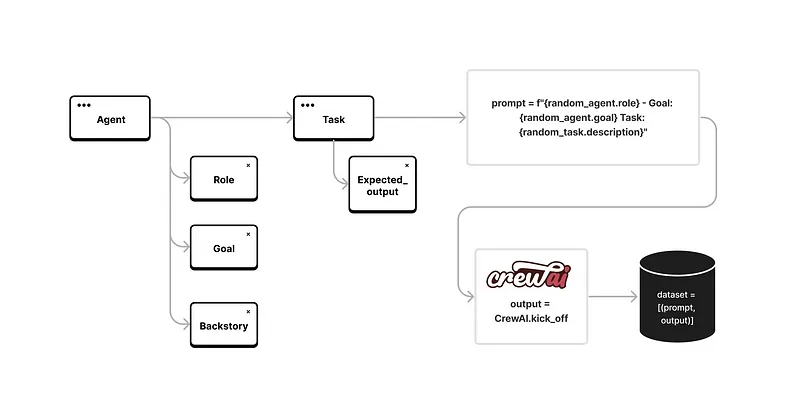
例如,要为我们的代理生成特定于任务或领域的角色,只需调整以下行:
role = generate_text(ollama, "Generate a random professional role.")修改为:
role = generate_text(ollama, "You are Software Architect.")同样,我们可以定义分配给代理的特定目标或任务。这使框架非常灵活。我们可以使用代理交互的中间结果,而不是使用 crewAI 的输出,我在提供的代码示例中跳过了这一点,以专注于主要思想。好的,让我们深入研究代码。
2.1 设置环境
要开始生成合成数据,我们需要设置我们的环境。以下代码片段演示了如何使用 crewAI 初始化环境并将其与 Ollama 模型集成以生成文本。
导入必要的库并进行身份验证
我们首先导入必要的库并使用 Hugging Face Hub 验证我们的会话。
from crewai.tasks.task_output import TaskOutput
from langchain_community.llms import Ollama
import pandas as pd
import streamlit as st
import random
from crewai import Agent, Task, Crew, Process
import os
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, TrainingArguments, Trainer, AutoModelForCausalLM
from huggingface_hub import login
from datasets import load_dataset, Dataset
# Authenticate with your access token
login(token="your_huggingface_token")
st.set_page_config(page_title="crewAI fine-tuned Mistral", page_icon=":robot_face:", layout="wide")
st.markdown("<h1 style='text-align: center;'>crewAI fine-tuned Mistral</h1>", unsafe_allow_html=True)
st.info("Let's fine-tune Mistral for crewAI", icon="ℹ️")加载模型
接下来,我们加载模型,该模型将用于在模拟期间生成文本。我使用 Ollama 生成数据集,并使用 Transformer 和 peft 库进行训练。
@st.cache_resource
def load_model():
model_name = "openhermes"
llm_ollama = Ollama(model=model_name, temperature=0.3)
print("Model loaded")
return llm_ollama
model = load_model()2.2 生成合成数据
代理是 crewAI 中的核心实体,每个都有特定的角色、目标和背景故事。这些代理模拟现实世界的交互并提供丰富的合成数据来源。代码生成十个随机代理。
def create_random_agent(ollama):
role = generate_text(ollama, "Generate a random professional role.")
goal_prompt = f"Generate a specific goal for a professional specializing in {role}."
goal = generate_text(ollama, goal_prompt)
backstory_prompt = f"Generate a generic backstory for {role} specializing in {goal}."
backstory = generate_text(ollama, backstory_prompt)
return Agent(llm=ollama, role=role, goal=goal, backstory=backstory, verbose=True, memory=False)
agents = [create_random_agent(model) for _ in range(10)]
for agent in agents:
print(f"Agent {agent.role} created with goal: {agent.goal} and backstory: {agent.backstory}")2.3 创建随机任务
任务是分配给代理的特定操作或目标。每个任务都包括详细描述和预期结果,模拟现实的工作职能。
def create_random_task(ollama, agent):
role = agent.role
task_description = generate_text(ollama, f"Create a task description suitable for a professional like a {role}")
expected_output = generate_text(ollama, f"What would be an expected output for this task {task_description}?")
return Task(description=task_description, expected_output=expected_output, allow_deadline=False, verbose=True, agent=agent, memory=False, callback=callback_function)
tasks = [create_random_task(model, agent) for agent in agents]
for task in tasks:
print(f"Task {task.description} created for Agent {task.agent.role}"2.4 数据集生成
Crew 是代理和任务的集合。通过初始化 Crew,我们可以模拟交互并在 generated_dataset.csv 文件中收集输出数据。
sequential_process = Process.sequential
universal_crew = Crew(agents=agents, tasks=tasks, process=sequential_process, verbose=True, full_output=True, memory=False)
def simulate_crew_interactions(crew, num_pairs=100):
results = []
if not os.path.isfile("generated_dataset.csv"):
df = pd.DataFrame(columns=['Prompt', 'Output'])
df.to_csv("generated_dataset.csv", index=False)
data_rows_already_in_file = len(pd.read_csv("generated_dataset.csv"))
while (len(pd.read_csv("generated_dataset.csv")) - data_rows_already_in_file) < num_pairs:
random_task = random.choice(crew.tasks)
random_agent = random_task.agent
random_crew = Crew(agents=[random_agent], tasks=[random_task], process=sequential_process, verbose=True, full_output=True, memory=False, step_callback=progress_callback)
prompt = f"{random_agent.role} - Goal: {random_agent.goal} Task: {random_task.description}"
crew_results = random_crew.kickoff()
output = crew_results['final_output']
dataset = [(prompt, output)]
df = pd.DataFrame(dataset, columns=['Prompt', 'Output'])
df.to_csv("generated_dataset.csv", mode='a', header=False, index=False)
simulate_crew_interactions(universal_crew, num_pairs=1)
print("COMPLETED!")
st.markdown("COMPLETED!")3、微调模型
生成合成数据后,我们现在可以微调模型。本节概述了预处理数据及其用于模型训练的步骤。
3.1 预处理数据
我们首先加载合成数据并准备进行训练。
def load_train_data():
return pd.read_csv("generated_dataset.csv")
def preprocess_data(train_data, tokenizer):
def preprocess_function(examples):
inputs = examples["Prompt"]
targets = examples["Output"]
model_inputs = tokenizer(inputs, max_length=1024, truncation=True, padding='max_length')
labels = tokenizer(targets, max_length=1024, truncation=True, padding='max_length')
model_inputs["labels"] = labels["input_ids"]
return model_inputs
train_data = Dataset.from_pandas(train_data)
train_dataset_for_finetuning = train_data.map(preprocess_function, batched=True, remove_columns=train_data.column_names)
return train_dataset_for_finetuning
train_data = load_train_data()
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
train_dataset = preprocess_data(train_data, tokenizer)3.2 使用 LoRA 进行微调
LoRA(低秩自适应)是一种通过在原始模型的权重中添加可训练的低秩矩阵来有效微调大型语言模型的技术。
什么是 LoRA?
低秩自适应(LoRA)是一种将预训练的大型语言模型(LLM)适应特定任务而无需完全重新训练的方法。LoRA 不会更新整个模型参数集,而是将低秩矩阵插入模型的每一层。这些矩阵更小,更容易训练,使得微调过程在计算资源和时间方面更加高效。
LoRA 的优势:
- 效率:通过仅添加少量参数(低秩矩阵),LoRA 显著降低了与微调大型模型相关的计算开销。
- 内存使用:LoRA 使用的内存比完全微调少,因为在训练期间只更新添加的低秩矩阵。
- 可扩展性:此方法对于非常大的模型特别有用,因为由于硬件限制,传统的微调是不切实际的。
接下来我们使用上述代码生成的合成数据对模型进行微调的 LoRA 实现。
以下是一些重要注意事项。
首先,你应该使用你可以访问的最先进的模型来生成数据集。假设你将针对特定用例微调更小、更灵活的模型。在所呈现的代码中,我使用 openhermes(微调的 Mistral)来微调 Mistral 模型。这是因为我获得了经验。我鼓励你尝试不同的模型。
其次,根据你的硬件设置,最好将 per_device_train_batch 设置为最高值,而牺牲 gradient_accumulation_step。这取决于你可用的内存量。最大的批处理大小将提供更好、更一致的结果。
使用训练参数,它们会影响系统要求和微调所需的时间。
最后,你通常不需要生成大型数据集。对于特定的、定义明确的用例,你将需要数据集中的 300 到几千个元素。
在开始微调之前,你应该“清理”生成的数据集——我在这里跳过它,但至少删除重复项总是值得的。
微调后的模型将保存在 /mistral-finetuned目录中。
lora_config = LoraConfig(
r=8,
lora_alpha=32,
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM",
)
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
model = get_peft_model(model, lora_config)
training_args = TrainingArguments(
output_dir="./mistral-finetuned",
overwrite_output_dir=True,
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=2,
save_steps=10_000,
save_total_limit=2,
prediction_loss_only=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
)
trainer.train()
trainer.save_model("./mistral-finetuned")4、利用微调模型
微调后,该模型可用于根据新提示生成响应。以下是代码示例。
# Load the fine-tuned model
model = AutoModelForCausalLM.from_pretrained("./mistral-finetuned")
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
# Define a prompt
prompt = "Write a review about your experience at a restaurant."
# Generate a response from the model
outputs = model.generate(tokenizer(prompt, return_tensors="pt").input_ids, max_length=1024, num_return_sequences=1)
# Decode the response
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Print the response
print(response) 5、结束语
crewAI 框架提供了生成合成数据的强大解决方案,这对于微调模型至关重要。通过创建真实的代理交互和任务,我们可以生成针对特定需求定制的高质量数据集。此过程不仅可以提高模型性能,还可以确保灵活性、隐私性和成本效益。
关键要点:
- 真实性:crewAI 中基于代理的模拟可以生成与真实世界场景非常相似的交互,从而提高训练数据的质量。你可以为你的用例构建多个场景。
- 灵活的数据生成:控制参数和定制交互的能力可确保生成的数据与当前任务高度相关且特定。
- 可扩展性:合成数据生成比现实世界的数据收集和标记更具成本效益和可扩展性,可以高效地生成大型数据集。但您始终需要验证微调模型的质量。
- 可重用性:代理及其交互可以重复使用并适应不同的场景,为持续的数据生成和模型微调提供灵活的框架。
- LoRA:使用 LoRA 进行微调在效率、内存使用和可扩展性方面具有显着优势,使其成为将大型模型适应特定任务的理想选择。但是不要犹豫使用不同的方法——这完全取决于你的特定需求和要求。
通过使用 crewAI 进行合成数据生成,你可以显着提高 AI 模型的稳健性和适应性,使其更适合处理广泛的现实世界应用程序。
无论你是在努力提高模型准确性、解决隐私问题还是减少数据收集成本,基于 crewAI 提出的框架为你的数据需求提供了多功能且高效的解决方案。
原文链接:Synthetic Data Generation with crewAI Agents for Model Fine-Tuning
汇智网翻译整理,转载请标明出处
