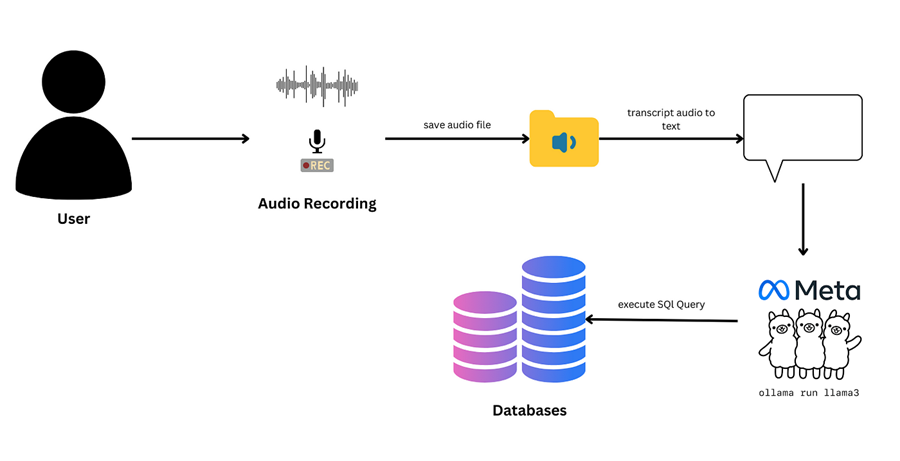
用语音命令管理数据库
该项目使用 Whisper 进行语音转文本,并使用 Llama 3 将转录转换为 SQL 查询,从而实现通过语音命令自动更新数据库。
微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我当时正在重温《哈利波特》系列,心里一直在想:老师和级长们到处给各个学院扣分!但是,他们会记录这么多班级的分数变化吗?数据完整性呢?可扩展性呢?写入冲突呢?他们肯定需要可扩展的东西,比如用于学院分数更新的发布-订阅系统。除了规模之外,语音识别必须有多好?
严肃地说,这让我开始思考——我们能用人工智能重现其中的一些吗?如果我们可以直接从语音转到 SQL 会怎么样?这就是我最终深入研究这个有趣的小实验的原因:使用 OpenAI 的 Whisper 进行转录,使用 Meta 的 Llama3 将文本转换为 SQL 查询,进行语音转 SQL。

这是我的方法,你也可以通过四个简单的步骤完成:
1、录制音频
我们通过使用简单的 Python 设置捕获音频来开始。使用 sounddevice库,我们直接从麦克风录制音频,然后将其临时保存为 .wav 文件以便稍后转录。
import sounddevice as sd
import tempfile
import wave
# Function to record audio from the microphone and save it as a WAV file
def record_audio(duration, sample_rate=16000):
print("Recording...")
audio_data = sd.rec(int(duration * sample_rate), samplerate=sample_rate, channels=1, dtype='float32')
sd.wait() # Wait for the recording to finish
print("Recording finished.")
# Save the audio to a temporary WAV file
temp_wav = tempfile.NamedTemporaryFile(delete=False, suffix=".wav")
with wave.open(temp_wav.name, 'wb') as wf:
wf.setnchannels(1) # Mono channel
wf.setsampwidth(2) # 16-bit audio
wf.setframerate(sample_rate)
wf.writeframes(np.int16(audio_data * 32767)) # Convert float32 to int16
return temp_wav.name一切从这里开始:一个简陋的语音命令准备转换成 SQL!
2、使用 Whisper 进行语音转文本
接下来,我们使用 OpenAI 的 Whisper 模型转录音频。此模型非常适合将语音转换为文本。这几乎就像拥有一个私人助理,可以听取你的命令并将其写下来 — 只是更加可靠和可扩展。
import whisper
import os
# Function to transcribe audio from the microphone using Whisper
def audio_to_text_from_mic(duration=5):
# Record audio from the microphone
audio_file = record_audio(duration)
# Load Whisper model
model = whisper.load_model("turbo") # You can use "turbo", "small", etc.
# Transcribe the recorded audio file
result = model.transcribe(audio_file)
# Delete the temporary audio file after transcription
os.remove(audio_file)
return result['text']
# Example usage
text = audio_to_text_from_mic(duration=3) # Record for 5 seconds
print("Transcription:", text)Transcription: 10 points to Gryffindor你的自然语言命令现在以文本形式呈现,可以进行下一级别的转换。
3、使用 Llama 3 将文本转换为 SQL
现在,真正的魔法来了 — 将转录的文本转换为 SQL 命令。使用 Llama 3 模型,我们输入自然语言命令(“为 Gryffindor 加 10 分”)并输出有效的 SQL 查询。
我们首先构建一个提示,提供有关数据库架构的上下文。在我们的例子中, house_points 表有两列: house_name(房屋名称)和 points(当前总分)。提示清楚地解释了这种结构,并指示模型返回格式良好的 SQL UPDATE 查询,而无需不必要的解释。
以下是分步操作:
a) 定义表架构:我们提供表的结构,让模型清楚地了解它是什么样子。架构指定表包含 house_name 和 points。
table_schemas = """
house_points(house_name TEXT PRIMARY KEY, points INTEGER)
"""b) 创建提示:我们生成一个提示,要求 Llama 3 将自然语言命令转换为 SQL UPDATE 查询。它明确要求仅使用查询以 JSON 格式响应,以确保输出干净且可用。
prompt = f"""
You are a SQL expert.
Please help to convert the following natural language command into a valid UPDATE SQL query. Your response should ONLY be based on the given context and follow the response guidelines and format instructions.
===Tables
{table_schemas}
===Response Guidelines
1. If the provided context is sufficient, please generate a valid query WITHOUT any explanations for the question.
2. Please format the query before responding.
3. Please always respond with a valid well-formed JSON object with the following format
4. There are only UPDATE queries and points are either added or deducted from a house
===Response Format
{{
"query": "A valid UPDATE SQL query when context is sufficient.",
}}
===command
{natural_language_text}
"""c) 向 Llama 3 发送请求:然后使用 Ollama API 将文本发送到 LLM。模型处理请求并返回带有 SQL 查询的 JSON 对象。我们解析模型的 JSON 响应以提取 SQL 查询。如果出现问题(例如解析响应失败),则会返回错误。这确保了代码的稳健性。
import ollama
import json
response = ollama.chat(
model="llama3",
messages=[{"role": "user", "content": prompt}]
)
# Directly return the content as it should now be only the SQL query
# Parse the JSON response and return the SQL query if provided
response_content = response['message']['content']
# Directly return the content as it should now be only the SQL query
# Parse the JSON response and return the SQL query if provided
response_content = response['message']['content']
try:
response_json = json.loads(response_content)
if "query" in response_json:
return response_json["query"]
else:
return f"Error: {response_json.get('explanation', 'No explanation provided.')}"
except json.JSONDecodeError:
return "Error: Failed to parse response as JSON."这样,你的“格兰芬多加 10 分”就变成了这样的 SQL 查询:
UPDATE house_points SET points = points + 10 WHERE house_name = 'Gryffindor';3、运行 SQL 查询
最后,我们获取生成的 SQL 查询并在数据库上执行它以更新学院分数。但在深入执行查询之前,让我们确保初始设置已到位。
首先,你需要一个表来跟踪每个霍格沃茨学院的分数。以下是完成这项工作的简单表结构:
CREATE TABLE house_points (
house_name VARCHAR(50) PRIMARY KEY,
points INT
);现在,将每栋房子的初始分数填入表格中。以下是一条快速 SQL 命令,可让每栋房子从 100 分开始:
INSERT INTO house_points (house_name, points)
VALUES ('Gryffindor', 100), ('Hufflepuff', 100), ('Ravenclaw', 100), ('Slytherin', 100);数据库准备就绪后,您需要建立连接以运行查询。使用 SQLAlchemy 可使此操作变得非常简单。设置连接的方法如下:
from sqlalchemy import create_engine, text
engine = create_engine('postgresql://db_user:db_password@localhost/db_name')
def run_sql_query(query):
with engine.connect() as conn:
conn.execute(text(query))
conn.commit()将 “db_user”、“db_password”和“db_name”替换为您的实际 PostgreSQL 凭据和数据库名称。
此函数获取由我们的语音转 SQL 脚本生成的 SQL 查询并在你的数据库上执行它。每次新的语音命令更新积分时,此函数都会运行相应的 SQL 并提交更改,确保实时更新学院积分表。
你刚刚通过语音命令更新了您的霍格沃茨学院积分——这太神奇了?
5、在 Streamlit 中将所有内容整合在一起
为了使你的项目更加用户友好,为什么不将整个解决方案包装到 Web 应用程序中?
使用 Streamlit,你可以构建一个交互式界面,用户可以在其中记录他们的语音命令,查看学院积分的实时更新,并查看学院徽标等视觉效果。
我已经在我的 Github 存储库中包含了完整的代码,你可以查看并自定义以满足你的需求。

6、结束语
只需几行代码,你就构建了一个语音驱动的 SQL 执行器。非常适合那些你内心的麦格教授,巧妙扣分的时刻。因此,无论你是管理霍格沃茨还是任何数据集,语音转 SQL 可能正是你节省时间所需的咒语。
原文链接:Speech-To-SQL Using OpenAI’s Whisper and Ollama (Llama3)
汇智网翻译整理,转载请标明出处
