解码非结构化文本中的信号
本文介绍了一个案例研究,该案例研究处理来自各种来源的非结构化文本数据以生成精炼的直观和可操作的见解。

在当今快节奏的商业环境中,数据是进步和创新的基石。通过利用高级分析、人工智能和新兴技术,企业可以增强决策能力、优化运营、发现机遇并将挑战转化为成功。战略数据方法涉及理解和处理各种数据类型(结构化、非结构化和半结构化),以获得有意义的见解。本文介绍了一个案例研究,该案例研究处理来自各种来源的非结构化文本数据以生成精炼的直观和可操作的见解。
此外,它强调了手动数据处理过程中遇到的无数挑战,包括偏见、隐私问题和效率低下,同时也强调了使用技术显着减少处理时间和改善战略决策的众多好处。
案例研究提供了一个设计最先进的 AI 解决方案的机会,该解决方案从非结构化文本中提取信号,收集可操作的见解,并提炼出重点突出关键主题、话题和情绪的摘要,并通过洞察导航树进行增强和提炼。我们的新方法包含一个六步流程,以逐步呈现简明、精确且有意义的可操作见解,同时保留其本质。
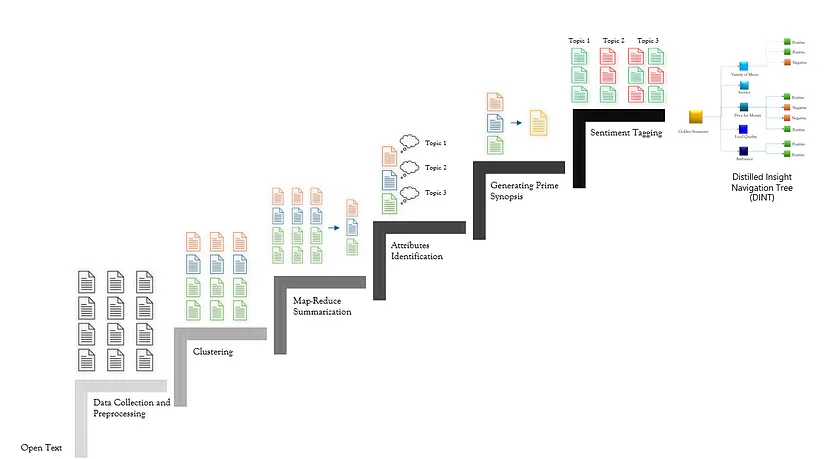
我们在下面依次描述每个组件。
1、数据收集和预处理
当我们开始批处理以获取和提取非结构化文本数据集时,我们探索了多种技术来处理原始数据并将其转换为适合分析的结构化格式。 这对于确保数据干净、连贯且准备好进行进一步处理至关重要。
我们的批处理设置涉及使用 Phi 3.5 等小型语言模型 (SLM) 来处理诸如歧义句子、表情符号转换和俚语等挑战。
1.1 歧义句子
目的:我们利用 SLM 来完善文本,消除歧义,并通过重写提高连贯性和整体质量,确保文本结构良好且更易于理解以供进一步分析。这种方法对于包含评论和反馈的文本非常有用,因为原始内容可能充斥着无关信息。
示例:
- 处理前:“嗨!我上周从 https://example.com 购买的产品很棒!但送货晚了。”
- 处理后:“上周购买的产品很棒,但送货晚了。”
1.2 表情符号转换
目的:反馈和评论文本通常包含传达细微情感的表情符号,但分析工具对这些表情符号的解释不一致。将表情符号转换为文本描述有助于情绪分析更有效地捕捉预期的情绪,提供更清晰的背景。这确保了准确的情绪捕捉和分析,而传统的文本分析工具可能会错过这一点。
示例:
- 处理前:“产品是😍”
- 处理后:“产品很棒。”
1.3 处理俚语
目的:评论通常包含俚语、缩写或不完整的句子,这可能会妨碍理解。在重写过程中为提示添加上下文有助于将俚语翻译成标准语言并补充零散的想法,从而提高文本质量和连贯性。俚语和不完整的句子可能会掩盖含义,因此翻译和澄清它们可确保文本清晰易懂。
示例:
- 处理前:“产品亮了。但是……交货晚了。”
- 处理后:“产品很好,但交货晚了。”
2、聚类
面对庞大的非结构化数据集,我们转向无监督机器学习领域,特别是聚类,将混乱的文本转换为连贯、可管理的集群。这一战略举措使我们能够发掘共同的主题和话题,使我们的分析更加清晰,更易于理解。
在文档摘要中,聚类将相似的部分分组以简化关键信息提取。对于主题建模,它揭示了广泛文本语料库中复杂的层次结构。在客户反馈分析中,聚类通过分组评论来识别共同的主题和情绪,从而提高了效率。此外,它还支持垃圾邮件过滤、社交网络分析、基于内容的分析和数据缩减,这对于提取见解和增强决策至关重要。
尽管我们对聚类技术充满信心,但我们还是在各种选项中精心探索了最适合我们需求的方法——DBSCAN、分层和凝聚(agglomerative)等。
经过彻底的分析,我们采用了凝聚聚类,它完全符合我们检查数据嵌套结构的需求。与其他技术(即 k-means 和 DBSCAN)相比,该方法具有几个优势:
- 预先确定聚类数量:与 k-means 不同,凝聚聚类的灵活性使我们能够避免预先定义聚类的数量。
- 处理不同形状和大小的聚类:凝聚聚类比 k 均值更好地管理各种形状和大小的聚类,k 均值假设球形聚类具有相似的大小。
- 对噪声和异常值具有鲁棒性:虽然 DBSCAN 在处理噪声和聚类方面也很有效,但凝聚聚类在处理噪声和异常值方面的额外优势使其成为我们的首选。
- 可扩展性:虽然与 DBSCAN 相比,凝聚聚类的计算量很大,但我们通过单一和完整的链接对其进行了优化,以处理我们的大型数据集。
- 参数敏感性:DBSCAN 需要仔细选择参数(例如 eps 和 minPts),这对我们来说是一个挑战。凝聚聚类不需要这样的参数,而且更容易实现。
- 处理不同的密度:当密度变化时,DBSCAN 很难处理聚类。凝聚聚类基于相似性而非密度来合并聚类,使我们能够基于单词或主题相似性形成聚类。
- 确定性方法:与 DBSCAN 不同,凝聚聚类是确定性的,为给定的数据集提供稳定的模型。
3、MapReduce 摘要
将非结构化文本聚类为连贯的组后,我们利用 MapReduce 框架并行处理这些聚类,创建既有意义又能代表文本的摘要。
- 映射步骤:将文本分割成较小的块或子文档并并行处理,从而加速摘要过程。然后使用语言模型对每个块进行单独摘要。
- 归约步骤:然后将在映射步骤中生成的各个摘要合并为一个统一的摘要。最终摘要概括了整个文档的关键点。
我们发现 MapReduce 汇总技术对于汇总大量非结构化文本非常有效,它通过单独汇总块(映射)然后将它们组合起来(减少),尤其是在子文档不严重依赖前面的上下文时。这种方法对于大量文本既可扩展又高效。虽然我们也探索了 Refine 方法和 Stuff Chain,但它们各自都具有独特的优势和局限性。
- Refine 方法:Refine 方法通过迭代更新每个新文档的摘要来简化汇总,使其适用于连续数据流。
- Stuff Chain 方法:Stuff Chain 方法通过将大型文档拆分成块,分别汇总每个文档,然后将它们组合起来来处理它们。虽然它可以有效地处理大型文件,但它受到语言模型的上下文窗口的限制。
我们在此分享了将这些替代技术与 MapReduce 进行比较时发现的结果:
MapReduce vs. Refine:
- 可扩展性:MapReduce 更具可扩展性,因为它可以并行处理数据,而 Refine 方法则更具顺序性。
- 复杂性:Refine 方法更简单,更容易实现,但处理大型数据集的效率不如 MapReduce。
- 功能性:MapReduce 为大规模摘要任务提供了更强大的功能,而 Refine 方法更适合连续数据流。
MapReduce vs. Stuff Chain
- 可扩展性:MapReduce 更具可扩展性,可以处理大量文本,而 Stuff Chain 受到语言模型上下文窗口的限制。
- 效率:MapReduce 并行处理数据,使其更适合处理大型数据集,而 Stuff Chain 则难以处理非常大的语料库。
- 灵活性:MapReduce 在处理各种数据结构和大小方面更灵活,而 Stuff Chain 更直接,但不太适合复杂数据。
4、属性识别
在获取和预处理非结构化文本数据后,我们采用聚集聚类和 MapReduce 汇总技术将数据组织成有意义的聚类。下一个关键步骤是识别这些聚类中的关键属性。这涉及从每个集群中提取突出的主题,从而提供每个组中主题的高级概述。此过程有助于轻松标记和更深入地理解数据。
为了实现这一点,我们尝试了各种主题建模技术,包括 BERTopic 库。BERTopic 利用转换器嵌入来捕获文本的语义含义,从而产生更连贯和上下文相关的主题。以下是该过程的简要概述:
嵌入文本:我们使用 SentenceTransformer 模型来生成嵌入,以捕获文本的语义细微差别。
from sentence_transformers import SentenceTransformer
# Load a pre-trained SentenceTransformer model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Encode your text data to get embeddings
embeddings = model.encode(your_texts, show_progress_bar=True)使用 BERTopic 进行主题建模:使用嵌入,我们应用BERTopic 模型来识别文本中的主题。
from bertopic import BERTopic
# Initialize BERTopic model
topic_model = BERTopic()
# Fit the model on your text data and extract topics
topics, _ = topic_model.fit_transform(your_texts)分析主题:我们提取了有关已识别主题的详细信息,并将其可视化以便更好地理解。
# Retrieve topic information
topic_info = topic_model.get_topic_info()
print(topic_info)
# Retrieve top words for a specific topic (e.g., topic 0)
top_words = topic_model.get_topic(0)
print(top_words)
# Visualize the topics
fig = topic_model.visualize_topics()虽然 BERTopic 是一种强大的主题建模技术,但我们还探索了以下其他技术:潜在狄利克雷分配 (LDA)、潜在语义分析 (LSA)、非负矩阵分解 (NMF) 和 Top2vec。此外,利用大型语言模型 (LLM) 或小型语言模型 (SLM) 进行提示可产生更好的结果。这些模型在理解上下文、细微差别和主题之间的关系方面表现出色,从而提供了更全面的数据分析。 LLM 和 SLM 都适用于主题建模,LLM 提供更广泛、更丰富的上下文理解,而 SLM 则为特定用例提供效率和速度。
5、生成主要概要
为了最大限度地发挥非结构化文本数据的价值,我们生成了“黄金摘要”或主要概要。这本质上是摘要的摘要,提供了所有集群的简洁而全面的概述。这确保不会忽略任何关键信息。
为了实现这一点,我们采用了先进的技术,例如密度链 (CoD) 和验证链 (CoVe) 提示工程方法。CoD 技术通过逐步增加信息密度而不显著增加摘要的长度来提高 AI 生成的摘要的质量。通过系统地添加关键细节同时保持可读性,CoD 显著提高了摘要的质量和相关性。另一方面,CoVe 技术通过系统地验证大型语言模型 (LLM) 生成的响应的输出来提高其可靠性。通过将复杂的查询分解为更简单的验证任务,CoVe 提高了各种应用程序中生成内容的整体质量,并建立了对 AI 生成内容的信任。
6、情绪标记
除了总结之外,还执行了情绪标记以提取与每个文本条目相关的情绪(正面、负面、中性)。这使我们能够识别正在讨论的主题,以及人们对这些主题的感受。例如,情绪分析揭示了哪些主题引起了正面反馈,哪些主题是不满的根源。
为了实现准确的情绪标记,我们使用了各种方法来识别正面、负面和中性的文本。情绪分析的主要挑战之一是处理矛盾的情绪和表情符号。矛盾的情绪很难分为正面、负面或中性。
为了解决这个问题,我们使用了思维链 (COT) 推理技术。该技术通过鼓励模型逐步阐明其推理过程,提高了 LLM 在情绪冲突场景中的表现。这使得模型能够在得出结论之前权衡不同的情感线索。例如,在分析对某项服务的复杂感受的反馈时,COT 有助于根据提出的论点澄清整体情绪是偏向正面还是负面。
7、自定义评估指标
在开发文本摘要和情绪分析流程后,彻底评估其有效性至关重要,以确保生成的摘要和见解既准确又可行,而不会失去其本质。我们采用了如下方法进行这项关键评估。
创建主要概要和记分卡
为了全面衡量摘要过程的性能,我们利用了 ROUGE 和 BLEU 分数等传统指标,创建了两个独特而有见地的视图:
- 主要概要:这个高级摘要是从各个文本集群的摘要中精心得出的,将整个文本语料库提炼成一个连贯而全面的概述。它是评估生成的摘要质量和完整性的基准。
- 记分卡:记分卡从文本数据中捕获关键主题,并将每个主题映射到其相关情绪(积极、消极或中性)。这种跨不同主题的情绪结构化视图提供了清晰细致的数据情感图景。通过可视化情绪分布,我们可以快速识别关注和满意的领域,从而做出更明智和更具战略性的决策。
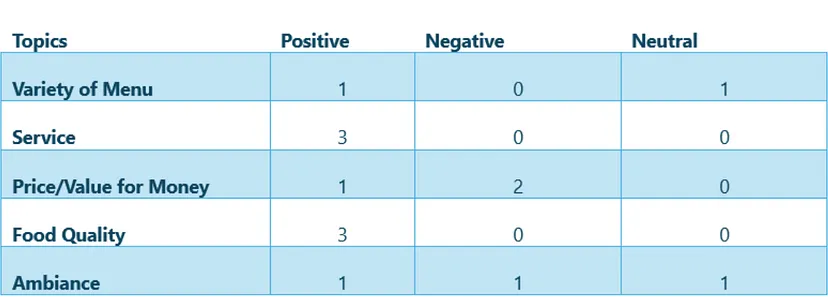
为了评估生成的摘要和主题的一致性和完整性,我们使用了主要概要和记分卡。我们确保黄金摘要与记分卡中的关键主题和情绪保持一致,并利用 LLM 进行一致性检查。主题覆盖率是另一个关键指标,用于评估关键主题在黄金摘要中的呈现情况。通过使用这些指标,我们改进了文本摘要工具,提高了输出质量。这些评估方法对于业务利益相关者至关重要,可确保从文本数据集中获得可靠而全面的见解,这对于明智的决策至关重要。
对于可视化,我们使用了一个直观且交互式的框架来组织见解,使其易于探索和浏览关键发现和文本。在本文中,我们将其称为精炼见解导航树 (DINT)。
8、用例和适用性
文本摘要和情绪分析的协同作用有可能在众多用例中发挥显著作用,尤其是涉及分析大量文本数据的用例。我们在此分享一个经过测试的用例,我们认为该解决方案提供了实质性的见解和价值:
8.1 客户产品评论
用例:我们利用包含电子商务产品评论的数据集来评估我们的摘要和情感分析工具的实力。
结果:摘要和记分卡提供了对产品性能的快速且可操作的见解,突出了产品质量、运输体验和客户服务等关键主题。该工具帮助企业确定客户优先事项和紧急问题。例如,在平板电脑评论中,它有效地综合了反馈,揭示了对产品功能和用户体验的关键见解。
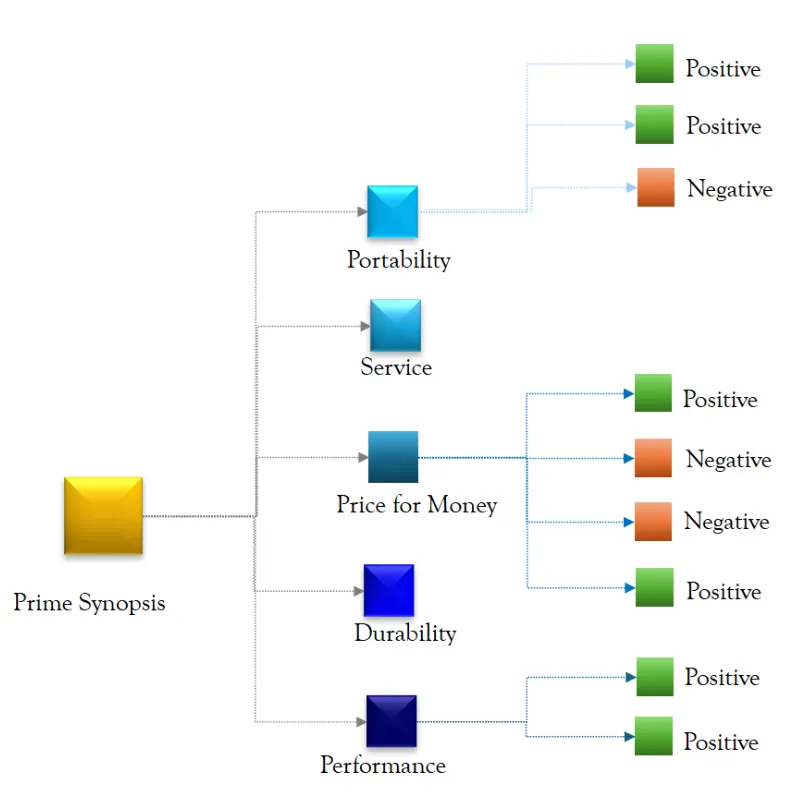
同样,它还可以用于从客户支持、调查、反馈文本和其他类似用例中收集见解。
9、学习和挑战
在我们创建有效文本摘要工具的过程中,我们面临了几个挑战并学到了重要的教训。处理嘈杂数据(例如拼写错误、俚语和不相关信息)需要强大的预处理技术来确保算法专注于核心含义。平衡摘要质量和完整性是另一个关键挑战,我们通过利用黄金摘要方法和评分卡来系统地评估和改进摘要来解决这一问题。此外,我们在 LLM 中遇到了一致性问题,相关主题有时未能出现在最终摘要中,或者情绪被错误分类。为了提高一致性和可靠性,我们采用了自定义评估指标,如主题覆盖率和一致性检查,反复微调提示和评估技术,以提高摘要的准确性和相关性。
10、结束语
自动文本摘要和情绪分析为被非结构化文本数据淹没的企业提供了变革性解决方案,使他们能够迅速将复杂信息转换为清晰、可操作的见解。这些融合了人工智能的技术通过减少处理大型数据集所需的时间来提高效率,使企业能够快速根据见解采取行动。通过识别关键主题和情绪,组织可以做出更明智的决策,解决客户痛点并改进内部流程。尽管存在数据噪声和模型不一致等挑战,但细致的预处理、及时改进和迭代评估可以产生高质量的摘要。最终,这些解决方案可用于帮助领导者以更高的清晰度和敏捷性做出更明智的数据驱动决策,帮助企业在管理大量文本数据方面保持领先地位。
原文链接:Decoding signals from unstructured text: The AI way
汇智网翻译整理,转载请标明出处
