DeepSeek GRPO强化学习算法
GRPO(组相对策略优化)是强化学习 (RL) 中使用的一种方法,通过比较不同的动作并使用一组观察结果进行小的受控更新来帮助模型更好地学习。
如果你在地球上,你现在一定听说过 DeepSeek 以及它是如何导致美国股市崩盘的。这个革命性模型的根源是“我的初恋”,即强化学习。因此,在这篇文章中,我们将尝试了解 GRPO,这是一种使这一切成为可能的强化学习算法。
1、预备知识
1.1 什么是强化学习中的策略?
在强化学习 (RL) 中,策略(policy)是代理用来决定在给定状态下采取哪种行动的策略。
- 确定性策略 (π(s)) → 始终为给定状态选择相同的动作。
- 随机策略 (π(a|s)) → 定义给定状态下动作的概率分布。
强化学习的目标是学习最大化累积奖励的最佳策略 (π*)。
1.2 什么是价值函数?
价值函数(value function)告诉我们一个状态或行动在未来奖励方面有多好。
- 状态值 (V) → 处于某种状态有多好。
- 动作值 (Q) → 在某个状态下采取特定动作有多好。
它如何与策略相关联:
- 策略决定采取什么动作。
- 价值函数通过估计哪些状态/动作会带来更高的回报来帮助改进策略。
- 价值估计越好,策略就会变得越好!
1.3 RL 中的 Critic-Actor 模型是什么?
与 GAN 非常相似,在 GAN 中,生成器和鉴别器模型在整个训练过程中都在相互竞争,RL Actor-Critic-Models 中也存在类似的概念,其中Actor-Critic (A2C、A3C) 是一种流行的 RL 架构,它结合了两个组件:
- Actor — 学习策略 (πθ) 并决定动作。
- Critic — 评估价值函数 (V(s)) 以指导 Actor。
工作原理:
- Actor 根据Critic的反馈更新策略。
- Critic估计预期奖励并减少学习中的差异。
2、GRPO 强化学习算法
在进入数学之前,我们将从一个例子开始。
GRPO(组相对策略优化)是强化学习 (RL) 中使用的一种方法,通过比较不同的动作并使用一组观察结果进行小的受控更新来帮助模型更好地学习。这就像是一种从经验中学习的聪明方法,而不会做出可能搞砸事情的重大改变。
想象一下,你正在教机器人玩一个简单的游戏,它必须在不同的路径之间做出选择才能达到目标。机器人需要学习哪些路径是好的,哪些不是。
GRPO 通过以下方式帮助机器人实现这一点:
- 尝试不同的路径:机器人尝试当前策略(策略)中的几条不同路径(操作)。
- 比较性能:比较每条路径的效果。
- 进行小幅调整:根据比较结果,机器人对其策略进行小幅调整以提高性能。
2.1 示例:机器人选择路径
假设机器人在迷宫中,必须在三条路径(A、B 和 C)之间进行选择才能到达目标。以下是 GRPO 的分步工作方式:
示例路径:
机器人尝试每条路径几次并记录结果。
- 路径 A:3 次中有 2 次成功。
- 路径 B:3 次中有 1 次成功。
- 路径 C:3 次中有 3 次成功。
计算指标:
机器人计算每条路径的成功率:
- 路径 A:成功率为 66.67%。
- 路径 B:成功率为 33.33%。
- 路径 C:成功率为 100%。
请注意,更新将在观察到“x”次观察后进行,而不是在每次试验后进行。与小批量梯度非常相似
比较路径:
机器人比较这些成功率,以确定哪条路径最佳。
路径 C 显然是最好的,因为它的成功率最高。
调整策略:
机器人更新其策略,以便将来更频繁地选择路径 C。
但它并没有完全忽略路径 A 和 B。它仍然会偶尔尝试它们,看看它们是否有所改善。
受控更新:
机器人确保不会过度改变其策略。例如,它可能会将选择路径 C 的概率从 30% 提高到 50%,但不会提高到 100%。这样,它仍然可以探索其他路径并了解更多信息。
现在让我们进入数学
2.2 GRPO 算法数学
策略和行动
- 让策略表示为 πθ,其中 θ 表示策略的参数。
- 对于给定状态 s,策略输出动作的概率分布:πθ(a∣s),即(给定状态选择哪个动作)
- 目标是最大化预期累积奖励 J(θ):
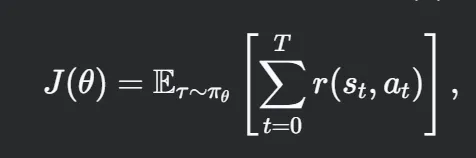
其中 τ=(s0,a0,s1,a1,… ) 是轨迹(过去采取的状态动作),r(st, at) 是时间 t 的奖励。
组抽样
- 对于给定状态 s,GRPO 使用当前策略 πθ 生成一组 N 个动作 {a1,a2,…,aN}。
- 每个动作 ai 都从策略中抽样:ai∼πθ(a∣s)。
奖励评分
- 每个动作“ai”都使用奖励函数 R(ai) 进行评估,该函数衡量动作的质量。
- 奖励函数可以基于即时奖励或未来奖励的折扣总和。
优势计算
优势 A(ai) 衡量动作 ai 与组的平均表现相比好多少或差多少。

策略更新
GRPO 更新策略参数 θ,以增加具有正优势的动作的可能性,并降低具有负优势的动作的可能性。
KL 散度约束
为了确保更新后的策略 πθ 不会与旧策略偏离太多,GRPO 包含一个 KL 散度约束:
此约束可确保更新稳定,并防止策略发生太大变化。
GRPO 目标
GRPO 的总体目标是在保持策略更新稳定的同时最大化预期累积奖励
2.3 GRPO 为何有效
- 组比较:通过比较组内的动作,GRPO 减少了策略更新的方差并确保更稳定的学习。
- 受控更新:KL 散度约束可防止对策略进行大的、不稳定的更改。
- 效率:GRPO 避免了评估每个可能的操作的需要,使其具有计算效率。
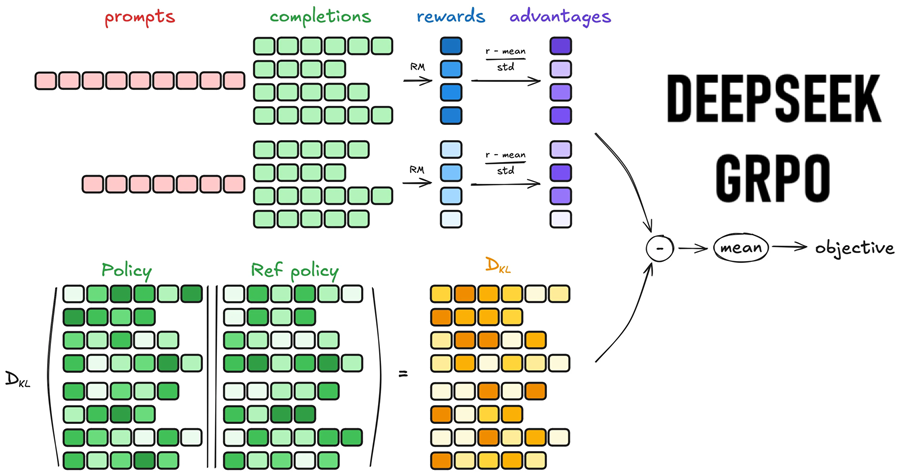
3、如何使用 GRPO 来训练 LLM?
- 组抽样:对于给定的提示,LLM 会生成多个响应。
- 奖励评分:奖励模型评估每个响应的质量。
- 优势计算:将响应与组的平均奖励进行比较,以确定哪些更好或更差。
- 策略更新:使用 KL 散度约束调整 LLM 的策略以支持高奖励响应,同时避免剧烈变化。
- 迭代训练:此过程重复进行,逐渐提高 LLM 生成高质量对齐文本的能力。
这就是纯强化学习用于训练LLM的方式。
原文链接:What is GRPO? The RL algorithm used to train DeepSeek
汇智网翻译整理,转载请标明出处
