DeepSeek GRPO Trainer简明教程
GRPO 是一种在线学习算法,这意味着它通过在训练期间使用训练模型本身生成的数据来迭代改进。GRPO 目标背后的直觉是最大化生成的完成的优势,同时确保模型接近参考策略。

TRL 支持使用 GRPO Trainer 来训练语言模型,如论文《DeepSeekMath:突破开放语言模型中数学推理的极限》中所述。
论文摘要如下:
数学推理因其复杂性和结构性而对语言模型构成了重大挑战。在本文中,我们介绍了 DeepSeekMath 7B,它继续使用来自 Common Crawl 的 120B 个数学相关标记以及自然语言和代码数据对 DeepSeek-Coder-Base-v1.5 7B 进行预训练。DeepSeekMath 7B 在不依赖外部工具包和投票技术的情况下,在竞赛级 MATH 基准上取得了令人印象深刻的 51.7% 的成绩,接近 Gemini-Ultra 和 GPT-4 的性能水平。 DeepSeekMath 7B 的 64 个样本的自洽性在 MATH 上达到 60.9%。DeepSeekMath 的数学推理能力归因于两个关键因素:首先,我们通过精心设计的数据选择管道利用了公开可用的网络数据的巨大潜力。其次,我们引入了组相对策略优化 (GRPO),这是近端策略优化 (PPO) 的一种变体,它可以增强数学推理能力,同时优化 PPO 的内存使用量。
1、快速入门
此示例演示如何使用 GRPO 方法训练模型。我们使用 TLDR 数据集中的提示训练 Qwen 0.5B Instruct 模型(忽略完成列!)。你可以在此处查看数据集中的数据。
以下是用于训练模型的脚本。请注意,前向传递的输入张量的大小为 num_generations * per_device_train_batch_size,因为 GRPO 为批次中的每个提示生成 num_generations 个完成。适当调整这些值有助于防止 OOM 错误。因此,有效的训练批次大小为 num_generations * per_device_train_batch_size * gradient_accumulation_steps。
# train_grpo.py
from datasets import load_dataset
from trl import GRPOConfig, GRPOTrainer
dataset = load_dataset("trl-lib/tldr", split="train")
# Define the reward function, which rewards completions that are close to 20 characters
def reward_len(completions, **kwargs):
return [abs(20 - len(completion)) for completion in completions]
training_args = GRPOConfig(output_dir="Qwen2-0.5B-GRPO", logging_steps=10)
trainer = GRPOTrainer(
model="Qwen/Qwen2-0.5B-Instruct",
reward_funcs=reward_len,
args=training_args,
train_dataset=dataset,
)
trainer.train()使用以下命令执行脚本:
accelerate launch train_grpo.py
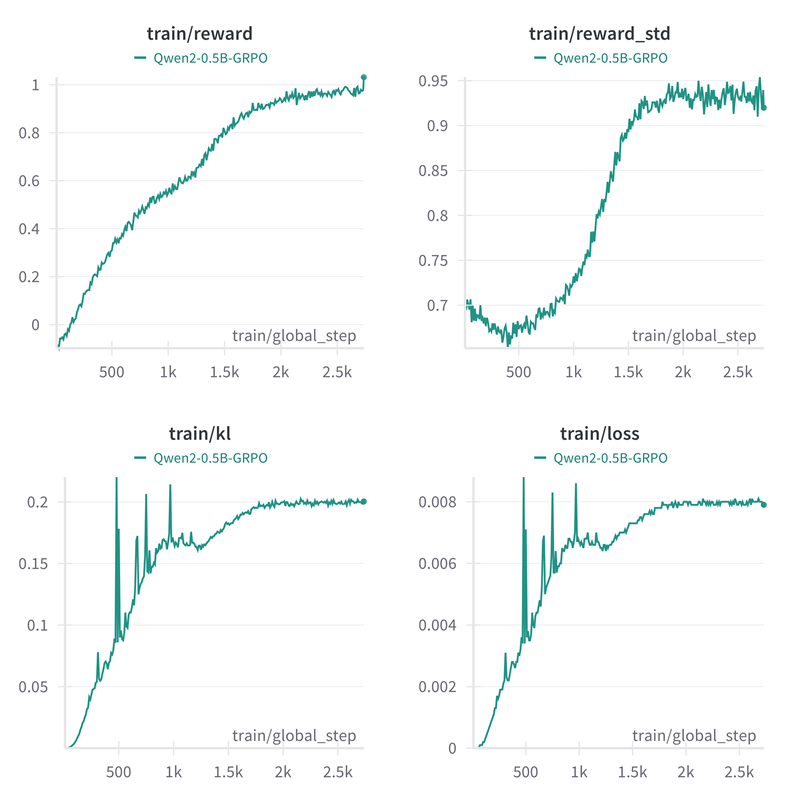
训练分布在 8 个 GPU 上,大约需要 1 天。
2、深入了解 GRPO 方法
GRPO 是一种在线学习算法,这意味着它通过在训练期间使用训练模型本身生成的数据来迭代改进。GRPO 目标背后的直觉是最大化生成的完成的优势,同时确保模型接近参考策略。要了解 GRPO 的工作原理,可以将其分解为四个主要步骤:生成完成、计算优势、估计 KL 散度和计算损失。

生成完成
在每个训练步骤中,我们都会抽样一批提示并为每个提示生成一组G 完成(表示为
oi)。
计算优势
对于每个G 序列,我们使用奖励模型计算奖励。为了与奖励模型的比较性质保持一致(通常在针对同一问题的输出比较数据集上进行训练),优势的计算反映了这些相对比较。它按如下方式进行规范化:

这种方法让该方法得名:组相对策略优化 (GRPO)。
估计 KL 散度
KL 散度是使用 Schulman 等人 (2020) 引入的近似器来估计的。近似器定义如下:

计算损失
目标是最大化优势,同时确保模型接近参考策略。因此,损失定义如下:

其中第一项表示缩放优势,第二项通过 KL 散度惩罚偏离参考策略的行为。
在原始论文中,该公式被推广为通过利用裁剪替代目标来考虑每一代之后的多次更新:
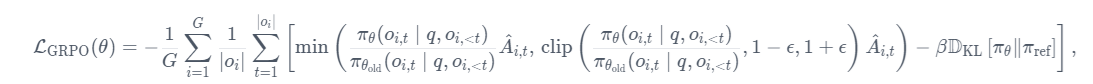
其中 clip(⋅,1−ϵ,1+ϵ) 通过将策略比率限制在 1−ϵ 和 1+ϵ 之间来确保更新不会过度偏离参考策略。然而,在 TRL 中,与原始论文一样,我们每代只进行一次更新,因此我们可以将损失简化为第一种形式。
3、记录指标
GRPO Trainer 记录以下指标:
completion_length:平均完成长度。reward/{reward_func_name}:每个奖励函数计算的奖励。reward:平均奖励。reward_std:奖励组内的平均标准差。kl:根据完成情况计算的模型与参考模型之间的平均 KL 散度。
4、定制
4.1 加速
生成通常是导致在线方法训练缓慢的主要瓶颈。为了加速生成,你可以使用 vLLM,这是一个支持快速生成的库。要启用它,请在训练参数中传递 use_vllm=True。
from trl import GRPOConfig
training_args = GRPOConfig(..., use_vllm=True)有关更多信息,请参阅使用 vLLM 加速训练。
4.2 使用自定义奖励函数
GRPOTrainer 支持使用自定义奖励函数代替密集奖励模型。为确保兼容性,你的奖励函数必须满足以下要求:
输入参数:
该函数必须接受以下内容作为关键字参数:
prompts(包含提示)、completions(包含生成的完成)、- 数据集可能具有的所有列名(但提示除外)。例如,如果数据集包含名为
ground_truth的列,则将使用ground_truth作为关键字参数调用该函数。
满足此要求的最简单方法是在函数签名中使用 **kwargs。
根据数据集格式,输入会有所不同:
- 对于标准格式,提示和完成将是字符串列表。
- 对于对话格式,提示和完成将是消息字典列表。
返回值:该函数必须返回浮点数列表。每个浮点数代表与单次完成相对应的奖励。
4.3 示例 1:奖励较长的完成次数
以下是标准格式的奖励函数示例,用于奖励较长的完成次数:
def reward_func(completions, **kwargs):
"""Reward function that gives higher scores to longer completions."""
return [float(len(completion)) for completion in completions]可以按如下方式测试它:
prompts = ["The sky is", "The sun is"]
completions = [" blue.", " in the sky."]
print(reward_func(prompts=prompts, completions=completions))4.4 示例 2:以特定格式奖励完成
下面是一个奖励函数的示例,用于检查完成是否具有特定格式。此示例的灵感来自论文 DeepSeek-R1:通过强化学习激励法学硕士中的推理能力中使用的格式奖励函数。它专为对话格式而设计,其中提示和完成由结构化消息组成。
import re
def format_reward_func(completions, **kwargs):
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<think>.*?</think><answer>.*?</answer>$"
completion_contents = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, content) for content in completion_contents]
return [1.0 if match else 0.0 for match in matches]可以按如下方式测试此功能:
prompts = [
[{"role": "assistant", "content": "What is the result of (1 + 2) * 4?"}],
[{"role": "assistant", "content": "What is the result of (3 + 1) * 2?"}],
]
completions = [
[{"role": "assistant", "content": "<think>The sum of 1 and 2 is 3, which we multiply by 4 to get 12.</think><answer>(1 + 2) * 4 = 12</answer>"}],
[{"role": "assistant", "content": "The sum of 3 and 1 is 4, which we multiply by 2 to get 8. So (3 + 1) * 2 = 8."}],
]
format_reward_func(prompts=prompts, completions=completions)4.5 示例 3:基于参考的奖励完成
下面是检查是否正确的奖励函数的示例。此示例的灵感来自论文 DeepSeek-R1:通过强化学习激励 LLM 中的推理能力中使用的准确度奖励函数。此示例专为标准格式设计,其中数据集包含一个名为 ground_truth 的列。
import re
def reward_func(completions, ground_truth, **kwargs):
# Regular expression to capture content inside \boxed{}
matches = [re.search(r"\\boxed\{(.*?)\}", completion) for completion in completions]
contents = [match.group(1) if match else "" for match in matches]
# Reward 1 if the content is the same as the ground truth, 0 otherwise
return [1.0 if c == gt else 0.0 for c, gt in zip(contents, ground_truth)]可以按如下方式测试此功能:
prompts = ["Problem: Solve the equation $2x + 3 = 7$. Solution:", "Problem: Solve the equation $3x - 5 = 10$."]
completions = [r" The solution is \boxed{2}.", r" The solution is \boxed{6}."]
ground_truth = ["2", "5"]
reward_func(prompts=prompts, completions=completions, ground_truth=ground_truth)4.6 将奖励函数传递给训练器
要使用你的自定义奖励函数,请按如下方式将其传递给 GRPOTrainer:
from trl import GRPOTrainer
trainer = GRPOTrainer(
reward_funcs=reward_func,
...,
)如果有多个奖励函数,你可以将它们作为列表传递:
from trl import GRPOTrainer
trainer = GRPOTrainer(
reward_funcs=[reward_func1, reward_func2],
...,
)奖励将计算为每个函数奖励的总和。
请注意,GRPOTrainer 支持多种不同类型的奖励函数。有关更多详细信息,请参阅参数文档。
原文链接:GRPO Trainer
汇智网翻译整理,转载请标明出处
