DeepSeek OCR 解读
DeepSeek 团队想要探究的是:我们能否构建一个模型,能够读取压缩后的图像并准确重建全文?在压缩到一定程度之前,我们能将压缩效果提升到何种程度?

大型语言模型(LLM) 受限于上下文长度,这是他们一直以来的弱点。
给他们一个 10 万个 token 的文档,你就会感受到它带来的压力:延迟、内存爆炸、token 成本螺旋式上升。这不是他们的错。Transformer 的注意力机制会随着序列长度呈二次方增长,因此处理长文本的计算成本会迅速增加。
现在想象一下,如果你不输入整个文本,而是将其作为图像显示给模型,会是什么情况。这就是 DeepSeek-OCR 背后的理念,该模型不将视觉视为辅助特征,而是将其视为文本的压缩层。
这篇论文称之为“上下文光学压缩”,本质上就是通过图像表示长文本内容,并使用视觉语言理解将其解码回来的行为。
乍一听可能有点奇怪。为什么将文本转换为图像会有帮助呢?但其原理很简单:
图像可以容纳大量文本,但只需用更少的 token 来表示。一页文本可能占用 2000-5000 个文本标记,而渲染成图像后可能只需要 200-400 个视觉标记。这大约相当于 10 倍的压缩。
DeepSeek 团队想要探究的是:我们能否构建一个模型,能够读取压缩后的图像并准确重建全文?在压缩到一定程度之前,我们能将压缩效果提升到何种程度?
1、核心架构
DeepSeek-OCR 是一个两阶段系统,一个称为 DeepEncoder 的视觉编码器和一个称为 DeepSeek-3B-MoE 的解码器。
DeepEncoder(约 3.8 亿个参数)编码器是大多数新想法的源泉。它结合了:
- SAM-base(80M):使用窗口注意力机制进行局部感知。可以将其理解为扫描图像的细粒度部分。
- CLIP-large(300M):使用密集注意力机制进行全局理解。这部分用于捕捉更广泛的布局和上下文。
- 它们之间是一个 16 倍卷积压缩器,用于在将视觉标记输入到繁重的全局注意力部分之前对其进行压缩。
示例:
一张 1024×1024 的图像被分割成 4096 个块。经过 16 倍压缩后,只剩下 256 个标记。因此,该模型避免了视觉转换器常见的激活内存爆炸问题。
DeepSeek-3B-MoE 解码器(约 5.7 亿个活动参数)是一个小型混合专家语言模型,每一步由 64 位专家中的 6 位激活。它从压缩的视觉标记中重建文本。因此,它实际上是一个视觉到文本的转换器,但经过大量文档数据、方程式、图表、化学结构,甚至多语言 PDF 的训练。
图像(文档页面)→ DeepEncoder → 压缩的视觉标记 → MoE 解码器 → 文本
2、多分辨率设计
压缩并非固定不变。 DeepSeek-OCR 支持多种“模式”,具体取决于您需要的细节程度。

这种多分辨率设置允许 DeepSeek-OCR 根据文本密度和页面布局动态调整压缩率。Gundam 模式像 InternVL2.0 一样平铺图像,这对于大型或复杂的页面非常有用。
3、训练设置
DeepSeek-OCR 的训练主要分为两个阶段:
- 第一阶段:使用图像-文本对的下一个标记预测,独立训练 DeepEncoder。
- 第二阶段:使用 OCR、视觉和纯文本数据,联合训练整个编码器-解码器。
训练规模:
- 硬件:20 个节点 × 8 块 A100 (40GB) GPU
- 吞吐量:约 700-900 亿个词条/天
- 批量大小:全局 640
- 学习率:使用 AdamW 时为 3e-5
数据构成:
- OCR 1.0 数据(3000 万页):真实 PDF 文档,涵盖 100 多种语言
- OCR 2.0 数据:合成但结构化的数据:图表、公式、几何图形等
- 通用视觉数据 (20%):用于保持图像基础能力
- 纯文本数据 (10%):用于保持语言质量
简而言之,他们构建了一个模型,它不仅可以从图像中读取文本,还可以理解图表、化学分子和简单示意图,而大多数 OCR 系统都会忽略这些内容。
4、基准测试
4.1 Fox 基准测试(压缩测试)
他们测试了 DeepSeek-OCR 在压缩视觉词条时恢复文本准确率的能力。
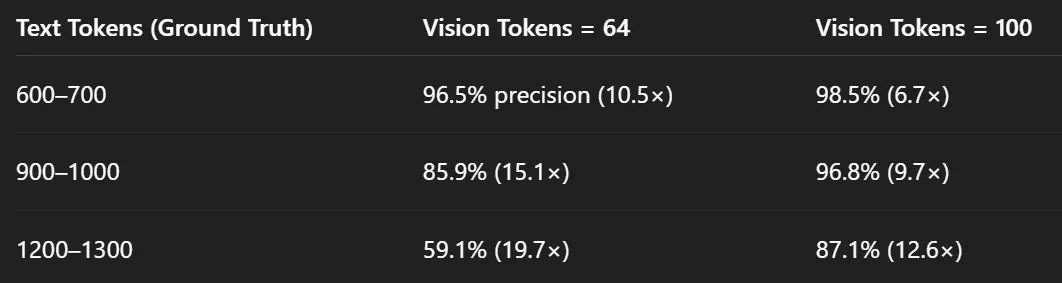
因此,在 10 倍压缩下,该模型保持了约 97% 的准确率。这实际上是无损的。即使在 20 倍压缩下,仍能获得约 60% 的准确率,考虑到如此大规模的压缩,这令人印象深刻。
4.2 OmniDocBench(实用 OCR 测试)
现在进入实际测试环节:解析 PDF 和结构化文档。
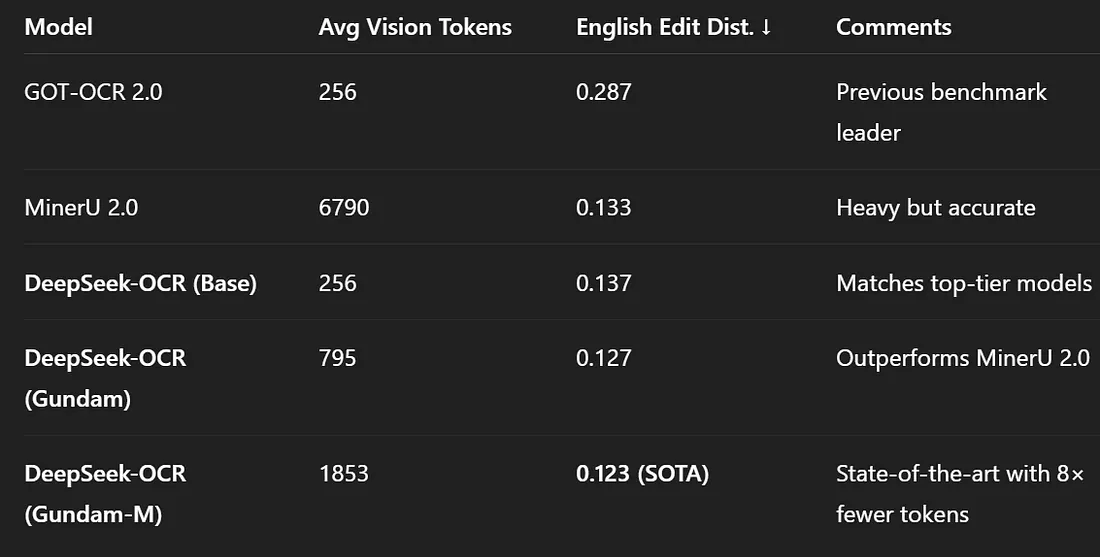
值得一提的是,DeepSeek-OCR 仅使用一小部分标记就达到了最佳的 OCR 准确率。在某些配置下,它仅使用 100-200 个视觉标记即可处理整个页面,比小型 OCR 处理单个段落所需的标记还要少。
5、深入理解上下文光学压缩
让我们来正确解读这个术语。
当你将文本转换为图像并将其输入视觉编码器时,你不再将文本含义存储为文本标记,而是将其以光学方式存储为形状和纹理的模式。然后,编码器将该图像映射到一个紧凑的潜在空间中,生成的标记数量远少于文本所需的标记数量。
这是因为语言冗余度很高,页面的视觉形式比文本序列更有效地编码所有间距、布局和单词形状。
因此,上下文光学压缩意味着:
- 将长文本上下文编码为图像嵌入
- 存储或传输压缩后的视觉表示
- 稍后在需要时将其解码回文本
可以将其视为一种使用视觉模态的LLM内存的有损压缩方案。
与其存储聊天记录中的所有10万个标记,不如存储不同分辨率的“光学快照”。旧的上下文可以压缩得更厉害(更小、更模糊),而新的上下文则保持清晰。
DeepSeek 的论文甚至将这个想法可视化为记忆衰减曲线:近期上下文 = 清晰图像(更多标记),较早的记忆 = 模糊图像(更少标记)。结果:一种可控的遗忘机制,其行为方式与人类随时间推移遗忘细节的方式惊人地相似。
6、其他功能
DeepSeek-OCR 不仅限于文本提取。它可以:
- 将图表解析为 HTML 表格
- 识别化学式并输出 SMILES 字符串
- 使用结构化词典理解平面几何
- 处理近 100 种语言的多语言 OCR
- 保留字幕和物体定位等通用视觉技能
而且由于其高效性,它每天可以在单个 A100 GPU 上生成超过 20 万页的训练数据,相当于在 20 节点集群上每天生成约 3300 万页数据。
因此,它还可以兼作预训练 LLM 和 VLM 的数据生成引擎。
7、为什么这种方法如此重要?
DeepSeek-OCR 改变了我们对长上下文处理的思考方式。它不再无休止地尝试扩展注意力窗口,而是说:从视觉上压缩这该死的东西。
对于 LLM 开发者来说,这意味着:
- 更便宜的内存:视觉标记更紧凑。
- 更快的推理:更少的标记 → 更少的 FLOP。
- 自然遗忘:旧上下文可以进行下采样。
- 更容易的多模态融合:该模型已经将文本视为图像。
对于 OCR 研究人员来说,这是一个全新的、最先进的系统,其性能优于 MinerU 2.0 和 GOT-OCR2.0 等更重的模型,同时运行速度更快、占用更少的内存。
8、结束语
DeepSeek-OCR 并非最终产品;它是一个有证据支持的可行假设。将文本存储为视觉并几乎无损地恢复的想法确实很有意思。它为古老的语境长度问题开辟了一个新视角:或许解决方案并非更大的窗口,而是更小的视野。
未来,LLM 的长期记忆或许不再以标记的形式保存,而是以图像的形式保存,经过压缩、分层且逐渐消退,就像我们自己的记忆一样。
原文链接:DeepSeek OCR is here
汇智网翻译整理,转载请标明出处
