DeepSeek-R1 671B本地运行指南
原始的 DeepSeek R1 是一个 6710 亿参数的语言模型,由 Unsloth AI 团队进行了动态量化,大小减少了 80%(从 720 GB 减少到 131 GB),同时保持了强大的性能。

原始的 DeepSeek R1 是一个 6710 亿参数的语言模型,由 Unsloth AI 团队进行了动态量化,大小减少了 80%(从 720 GB 减少到 131 GB),同时保持了强大的性能。当添加模型卸载时,该模型可以在 24GB VRAM 下以低令牌/秒的推理速度运行。
为什么大小对大型语言模型很重要
大型语言模型本质上需要大量存储和计算资源。为所有参数保持全精度表示(通常为 FP16 或 FP32)变得不切实际,尤其是对于局部推理,因为它需要内存。量化(减少权重表示的位宽)通过大幅减少模型大小和内存占用提供了一种解决方案。然而,整个网络的简单、统一的量化可能会导致严重的性能下降,表现为不稳定的输出或重复的 token 生成。
动态量化:一种量身定制的方法
Unsloth AI 团队的方法涉及动态量化,其中根据不同网络组件的敏感度分配可变位精度。关键技术见解包括:
- 选择性精度分配:初始密集层和向下投影(down_proj)矩阵对于设置稳定的表示和管理 SwiGLU 激活中的缩放属性至关重要,它们保持在更高的精度(4 位或 6 位)。相反,大部分参数(主要是混合专家 (MoE) 层中的参数,约占模型的 88%)被积极量化为 1.5-2 位。
- 重要性矩阵校准:在量化过程中加入重要性矩阵允许该方法动态调整每层的精度水平。此校准可防止常见的陷阱,例如通常由均匀量化引起的无限循环或无意义的输出。
- 层特定的敏感性分析:技术评估表明,虽然 MoE 层可以容忍较低的精度,但注意机制、嵌入层和最终输出头等组件需要更多位来保留激活分布。这种细致入微的策略可确保计算图中的关键路径保持足够的保真度。
1、量化模型变体和性能
Unsloth AI 发布了多个动态量化变体,每个变体都平衡了模型大小和输出质量:
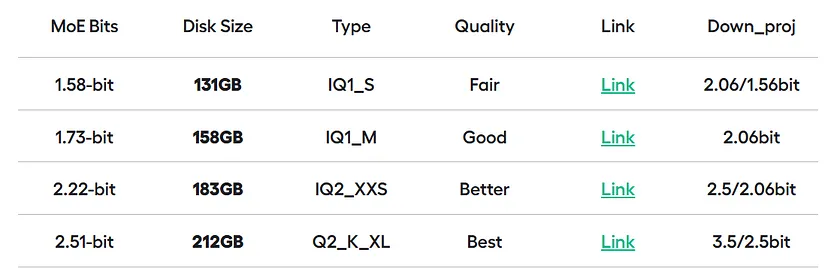
例如,在受控测试中,模型的任务是生成 Flappy Bird 游戏的 Python 实现,即使是最小的 1.58 位变体也能保持实质性的功能。相比之下,所有层的统一量化会导致重复输出或完全无法生成连贯的代码。
2、本地部署 DeepSeek R1
动态量化模型旨在在常见的推理引擎(如 llama.cpp)上运行,它支持 Unsloth AI 版本使用的 GGUF 文件格式。以下是部署过程的概述:
2.1 构建推理引擎
在启用 GPU 支持的情况下克隆和编译 llama.cpp:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
cmake . -B build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON
cmake --build build --config Release -j --clean-first --target llama-quantize llama-cli llama-gguf-split2.2 下载模型
使用 Hugging Face Hub 检索所需的模型变体:
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="unsloth/DeepSeek-R1-GGUF",
local_dir="DeepSeek-R1-GGUF",
allow_patterns=["*UD-IQ1_S*"], # For the 1.58-bit version
)2.3 GPU 卸载注意事项
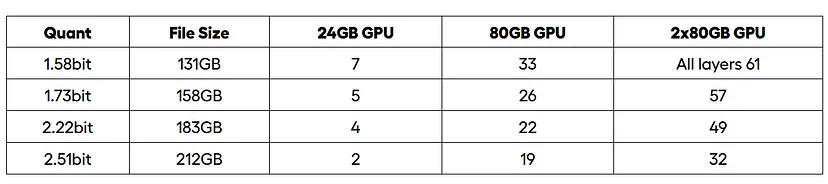
根据可用的 VRAM,使用以下命令确定要卸载到 GPU 的层数:
n_offload = floor((GPU_VRAM_GB / Model_FileSize_GB) * (Total_Layers - 4))使用类似以下命令执行模型运行推理:
./build/bin/llama-cli \
--model DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--cache-type-k q4_0 \
--threads 16 \
--prio 2 \
--temp 0.6 \
--ctx-size 8192 \
--seed 3407 \
--n-gpu-layers 7 \
-no-cnv \
--prompt "<|User|>Create a Flappy Bird game in Python.<|Assistant|>"3、我的经验
我想亲自尝试一下这种动态量化。为了测试该模型,我在 VastAI 上租用了一个 80 GB 的 GPU,每小时仅需 2.7 美元。考虑到原始模型的庞大规模,我对量化版本的性能和效率非常满意。以下是我进行的一些示例测试:
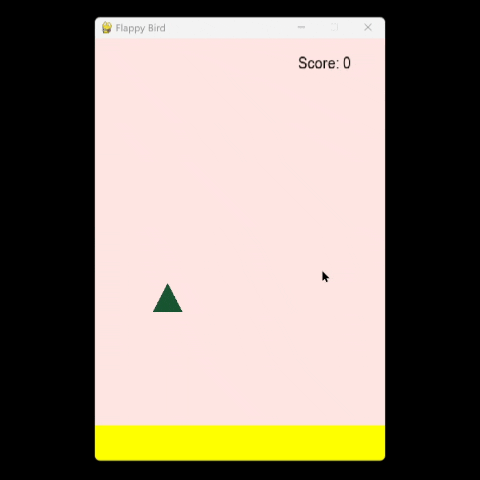
3.1 Flappy Bird 游戏生成
该模型成功生成了经典 Flappy Bird 游戏的 Python 实现。尽管激进量化存在一些典型的小问题,但核心功能完好,代码只需进行少量修改即可运行。
3.2 运动检测

4、常见陷阱和技术考虑
- 标记化细微差别:
注意特殊标记(例如,<|User|>、<|Assistant|>、<|begin_of_sentence|>、<|end_of_sentence|>)。处理不当可能会导致 BOS 标记重复或 EOS 屏蔽错误等问题。
- 参数敏感性:
有时,动态量化可能会在长序列中产生孤立的错误标记。调整推理参数(例如 min_p)(例如,调整为 0.1 或 0.05)可以帮助缓解这些细微差异。
5、结束语
Unsloth AI 对 DeepSeek R1 的动态量化体现了模型压缩技术的重大进步。通过在各个网络层之间智能地分配位精度,此方法保留了基本的计算保真度,同时将模型的存储空间减少了多达 80%。这意味着最先进的大型语言模型现在更容易访问,从而能够在以前不足的硬件上进行实验和部署。
如果你有兴趣进一步探索这一点,我鼓励你查看 Hugging Face 上的模型和 llama.cpp的GitHub 存储库。也请查看他们的原始文章:运行 DeepSeek-R1 Dynamic 1.58 位
原文链接:DeepSeek R1 in 24GB GPU : Dynamic Quantization by Unsloth AI for a 671B-Parameter Model
汇智网翻译整理,转载请标明出处
