DeepSeek-R1内部工作原理
在这篇文章中,让我们从什么是 DeepSeek-R1 模型开始,深入了解它的内部工作原理。

好吧,本周的头条新闻都是关于 DeepSeek-R1 的。因此,在这篇文章中,让我们从什么是 DeepSeek-R1 模型开始,深入了解它的内部工作原理。
首先,什么是 DeepSeek-R1?
DeepSeek-R1 是由中国 AI 公司 DeepSeek 开发的开源推理模型,可以处理需要逻辑推理、数学问题解决和实时决策的任务。
DeepSeek-R1 和 OpenAI 的 o1 等推理模型与传统大型语言模型 (LLM) 的区别在于,它们能够展示如何得出结论:

如上图所示,使用 DeepSeek-R1,你可以看到它对提示进行推理所遵循的步骤,这使得它更容易理解,并在必要时挑战其输出。这种能力使推理模型在需要解释结果的领域(如研究或复杂决策)中占据优势。
此外,该模型通过展示强化学习 (RL) 可以提高推理能力,挑战了行业对监督微调 (SFT) 的依赖。但同样,除了我上面提到的事情之外,是什么让它具有革命性?
- 自主技能的出现:与需要人工策划的推理示例的 GPT-4 或 Claude 3.5 Sonnet 不同,R1-Zero 通过纯 RL 开发自我验证和多步骤规划等技能。
- 成本:经过提炼的 7B 模型以 1/100 的训练成本超越 GPT-4o。
- 开源:模型权重、训练代码的完整发布。
1、技术架构
DeepSeek-R1建立在 DeepSeek-V3-Base 模型之上,这是一个 671B 参数的混合专家模型(MoE = 集成多个专门的模型或“专家”,以更有效地解决复杂问题),具有:
- 16 个专家网络:每个都是数学、代码、逻辑等的专门子模型
- 动态激活:通过学习路由每个 token 激活 37B 个参数。
- 预训练:4.8T(万亿)token 涵盖 52 种语言和技术领域,包括 STEM 论文、Github 存储库。
R1 变体:
| 模型 | 参数 | 训练方法 | 关键创新 |
|---|---|---|---|
| R1-Zero | 671B MoE | 纯 RL(无 SFT) | 自主推理发现 |
| R1 | 671B MoE | 多阶段 SFT+RL | 与人类对齐的 CoT 生成 |
| R1-Distill | 1.5B–70B | R1 输出上的 SFT | 经济高效的部署 |
2、DeepSeek 内部深入

2.1 以强化学习为核心
DeepSeek-R1 最具突破性的功能是它依赖强化学习 (RL) 来开发推理能力。与依赖人工策划示例的监督微调 (SFT) 的传统 LLM 不同,DeepSeek-R1 使用 RL 自主发现推理模式。它的工作原理如下:
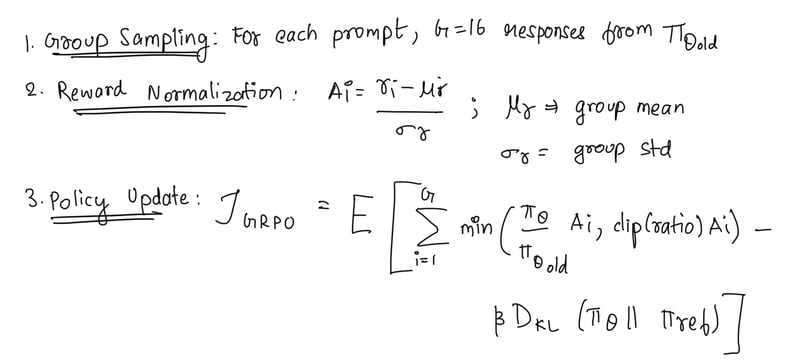
组相对策略优化 (GRPO)
这是一个 critic-free 的 RL 框架,当使用它代替近端策略优化 (PPO) 时,可将计算成本降低 40%。
该算法的工作方式是:
- 组抽样:对于每个提示,模型使用当前策略生成 G = 16 个响应。这些响应形成一个组,稍后用于计算奖励和优势。
- 奖励规范化:根据准确性、格式和语言一致性为组中的每个响应分配奖励,并计算优势 Ai。这种规范化有助于通过减少组统计数据的差异来稳定训练。
- 策略更新:在限制 KL 散度的同时最大化优势。在下面的等式中,β=0.01 控制 KL 惩罚的强度,确保策略不会偏离参考值太远。
混合奖励工程
这是一个三层奖励系统,可以防止奖励黑客攻击 ( reward hacking)。 当强化学习 (RL) 代理利用奖励函数中的缺陷或歧义来获得高奖励,而没有真正学习或完成预期任务时,就会发生奖励黑客攻击。奖励黑客攻击的存在是因为 RL 环境通常不完善,而且准确指定奖励函数从根本上具有挑战性。
| 奖励类型 | 计算方法 | 权重 (λ) |
|---|---|---|
| 准确度 (r_acc) | 二进制(如果最终答案正确则为 1) | 1.0 |
| 格式 (r_fmt) | 0.3 | |
| 语言 (r_lang) | 目标语言中标记的百分比 | 0.2 |
总奖励:
r_total = r_acc + λ1r_fmt + λ2r_lang
2.2 冷启动监督微调 (SFT)
在应用 RL 之前,DeepSeek-R1 会经历冷启动 SFT 阶段,这有助于为模型植入基本推理模式。现在,此阶段涉及:
精选数据集
- ~1,000 个高质量思路链 (CoT) 示例由人工精选。
- 每个示例都遵循严格的 XML 样式模板:
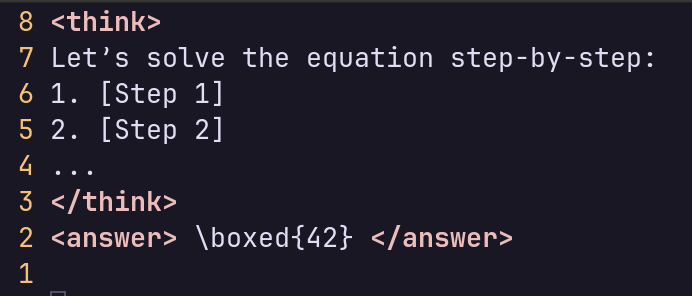
模板执行
- 该模型经过微调,可生成
<think>/<answer>格式的响应。 - 这确保推理过程结构化且可解释。
2.3 拒绝抽样以获得高质量数据
在 RL 过程之后,DeepSeek-R1 通过拒绝抽样生成 600K 个高质量推理样本。其工作方式是:
a) 样本生成
- RL 模型为每个提示生成多个响应。
- 只有通过基于规则的检查的响应才会被保留。
b) 语义过滤
- 语义连贯性低或推理不正确的响应将被丢弃。
c) 最终数据集
- 过滤后的数据集用于进一步微调和提炼。
2.4 提炼为较小的模型
DeepSeek-R1 的推理能力被提炼为较小的模型(1.5B-70B 个参数),以实现经济高效的部署。蒸馏过程包括:
a) 数据集创建
- 从 RL 训练模型生成 800k 个样本。
- 这些样本包括推理(600k)和一般任务(200k)。
b) 微调
- 较小的模型(如 Qwen-7B、Llama-70B)在蒸馏后的数据集上进行微调。
- 蒸馏过程中不应用 RL,这使其具有计算效率。
c) 性能
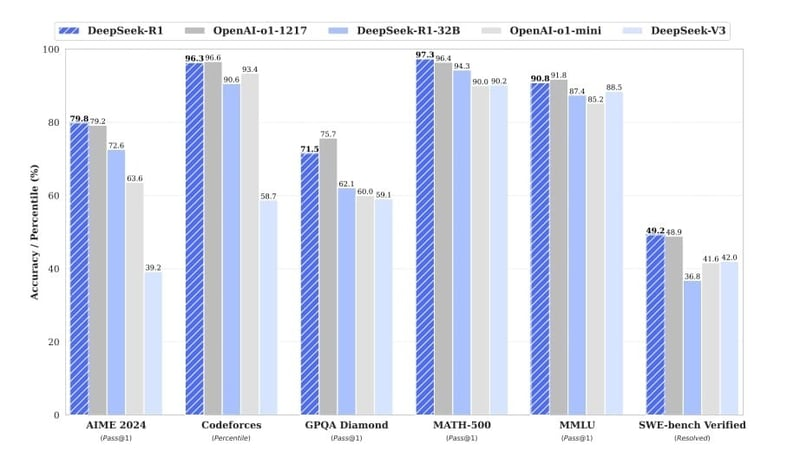
- 蒸馏后的 7B 模型在 AIME 2024 上实现了 55.5% 的 pass@1,以极低的成本超越了 GPT-4o(9.3%)。
3、性能分析:基准测试
数学推理
| 基准测试 | R1 | R1-Zero | GPT-40 | 人类专家 |
|---|---|---|---|---|
| AIME 2024(pass@1) | 79.8% | 71.0% | 9.3% | 85% |
| MATH-500(pass@1) | 97.3% | 95.9% | 74.6% | 98% |
| IMO问题形式化 | 81% | N/A | 22% | 89% |
关键见解:R1 通过以下方式在奥林匹克级问题上实现接近人类的表现:
- 步骤重用:在类似问题中重复使用部分解决方案
- 符号统计融合:将神经直觉与代数简化相结合
编码和软件工程
| 任务 | R1 | GPT-40 | SWE 人类 |
|---|---|---|---|
| LiveCodeBench(pass@1) | 65.9% | 32.9% | 72% |
| Codeforces Elo | 2029 | 759 | 2100(第 95 个百分位) |
| SWE-Bench Resolved | 49.2% | 38.8% | 58% |
突破:
- 调试链:自动生成测试用例以验证代码补丁
- 跨语言传输:解决 Python 问题,然后将解决方案移植到 Rust
原文链接:DeepSeek-R1 : internals made easy
汇智网翻译整理,转载请标明出处
