DeepSeek R1驱动的PDF机器人
本指南将引导你使用DeepSeek R1 + RAG构建一个功能性的PDF聊天机器人。逐步学习如何增强AI检索能力,并创建一个能够高效处理和响应文档查询的智能聊天机器人。

本指南将引导你使用DeepSeek R1 + RAG构建一个功能性的PDF聊天机器人。逐步学习如何增强AI检索能力,并创建一个能够高效处理和响应文档查询的智能聊天机器人。
想象一下:您刚刚部署了一个聊天机器人来处理客户查询,但与其让用户印象深刻,它却在基本问题上磕磕绊绊,吐出无关的答案,甚至更糟——完全捏造虚假信息。听起来熟悉吗?这是当今大多数AI聊天机器人的现实,即使是那些由尖端语言模型驱动的也不例外。但是,如果您可以构建一个不仅猜测而且知道答案的聊天机器人呢?一个系统,它可以深入您的PDF文件,提取所需的内容,并以精准的准确性交付答案。这就是检索增强生成(RAG)和DeepSeek R1的用武之地。那么,如何实现呢?让我们一探究竟。
1、DeepSeek R1:一种更智能的RAG方法
传统的RAG模型常常检索不相关或过于宽泛的内容,但DeepSeek R1采用先进的矢量化技术,能够从密集的PDF中提取精确且上下文相关的片段。
可以把DeepSeek R1想象成一个图书管理员,他不仅能找到正确的书,还能高亮显示您需要的确切段落。在法律科技领域,它可以提取冗长合同中的关键条款,而在医疗领域,它可以精确定位医疗手册中的剂量指南——没有废话,只有事实。
本地部署确保了数据隐私,使其非常适合金融和医疗等行业。展望未来,多模态集成可以增强其将文本与视觉数据结合的能力,从而提供更丰富的见解。
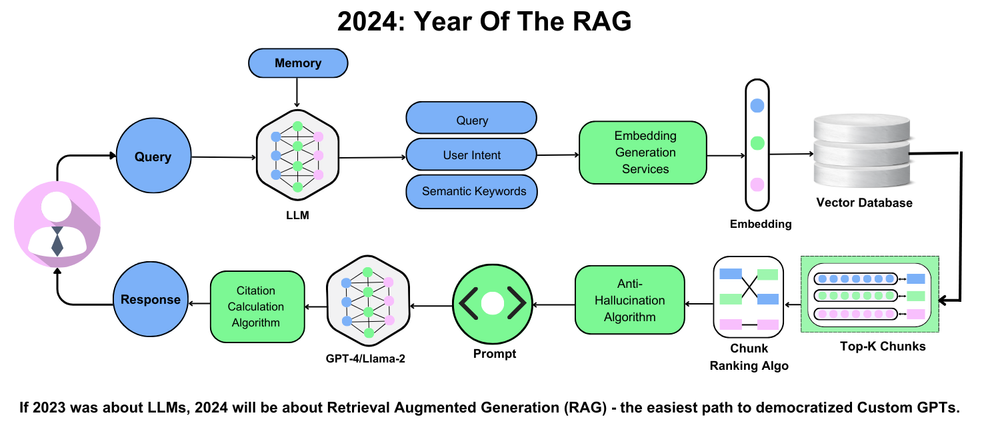
2、DeepSeek R1与RAG技术的协同作用
大多数RAG系统失败的原因在于它们将检索和生成视为独立的孤岛。DeepSeek R1通过紧密集成这些过程改变了游戏规则。它的语义矢量化不仅仅是检索数据——它检索相关数据,即使是从密集的PDF中也是如此。当回答复杂查询时,相关性就是一切。
在法律科技领域,DeepSeek R1可以精确提取案例法先例。它不会随机抽取段落;而是将检索与用户的意图对齐,确保生成的响应具有可操作性。
真正的魔力发生在您使用特定领域的嵌入对其进行微调时。这种方法弥合了通用AI与专业需求之间的差距,使其成为医疗、金融和教育等行业的强大工具。
3、设置开发环境
设置开发环境可能感觉像在没有说明书的情况下组装宜家家具。但是,如果您知道正确的步骤,使用DeepSeek R1会非常简单。
首先,确保您的系统满足最低硬件要求:8 GB RAM和现代CPU。DeepSeek R1的语义矢量化计算量很大。把它想象成一辆高性能跑车——它需要合适的赛道才能发光。
接下来,安装Python(3.8或更高版本)和所需的库。使用以下命令开始:
pip install deep-seek-r1 langchain transformers sentence-transformers
最后,使用示例PDF测试您的设置。如果它能检索到相关数据,您就可以开始构建了。
小贴士:从小型PDF开始,以免让系统不堪重负。
4、系统要求和先决条件
DeepSeek R1不是普通的聊天机器人框架——它是一个强大的工具。但要充分发挥其潜力,您的系统需要做好准备。
最低要求是8 GB RAM,但为了更流畅的性能,建议使用16 GB。DeepSeek R1的高级矢量化处理在处理大型PDF时内存消耗较大。
固态硬盘(SSD)将显著减少在矢量数据库中索引文档时的延迟,确保更快的检索速度。这对于实时应用(如客户支持)至关重要。
最后,不要低估专用GPU的重要性。虽然不是必须的,但它可以加速语义编码等任务,使您的聊天机器人变得闪电般快速。
5、安装DeepSeek R1及其依赖项
安装DeepSeek R1时,关键是确保Python环境、库和硬件之间的兼容性。
这里大多数人容易犯错的地方是跳过虚拟环境。不要这样做。使用venv或conda隔离依赖项。它可以防止可能导致设置中断的版本冲突。
例如,DeepSeek R1依赖于像ChromaDB这样的矢量数据库。安装错误的版本可能会导致索引失败。始终检查库的文档以确保版本对齐。将其与最新的torch和transformers库搭配使用,以获得最佳性能。
最后,优化您的GPU驱动程序。许多人忽视了这一点,但过时的驱动程序可能会在语义矢量化期间成为性能瓶颈。使用NVIDIA的CUDA工具包等工具来确保兼容性。
6、准备您的PDF数据进行集成
将您的PDF数据分块是构建一个不会因复杂查询而卡住的聊天机器人的秘密武器。
大多数人认为将PDF拆分成页面就足够了。其实不然。相反,应将文本分解为语义块——保留上下文的小而有意义的部分。
较小且富含上下文的块在与像ChromaDB这样的矢量数据库配对时提高了检索准确性。使用PyPDF2或pdfplumber等库提取原始文本。然后,应用带有重叠的滑动窗口技术(例如,200个标记,50个标记重叠)。这种重叠确保不会丢失块之间的关键信息。
想象一下一个解析合同的法律聊天机器人。如果不进行分块,它可能会错过条款之间的交叉引用。有了分块,您可以获得精确且上下文感知的答案。
7、使用DeepSeek R1和RAG构建PDF聊天机器人
大多数PDF聊天机器人之所以失败,是因为它们不了解数据——只是机械地复述。这就是DeepSeek R1改变游戏规则的地方。
通过将语义矢量化与RAG结合,它检索到的是真正需要的内容,没有多余信息,也没有幻觉。
DeepSeek R1的链式思维推理确保逻辑且上下文感知的响应。就像有一位图书管理员,不仅能找到书,还能翻到您需要的确切页面。
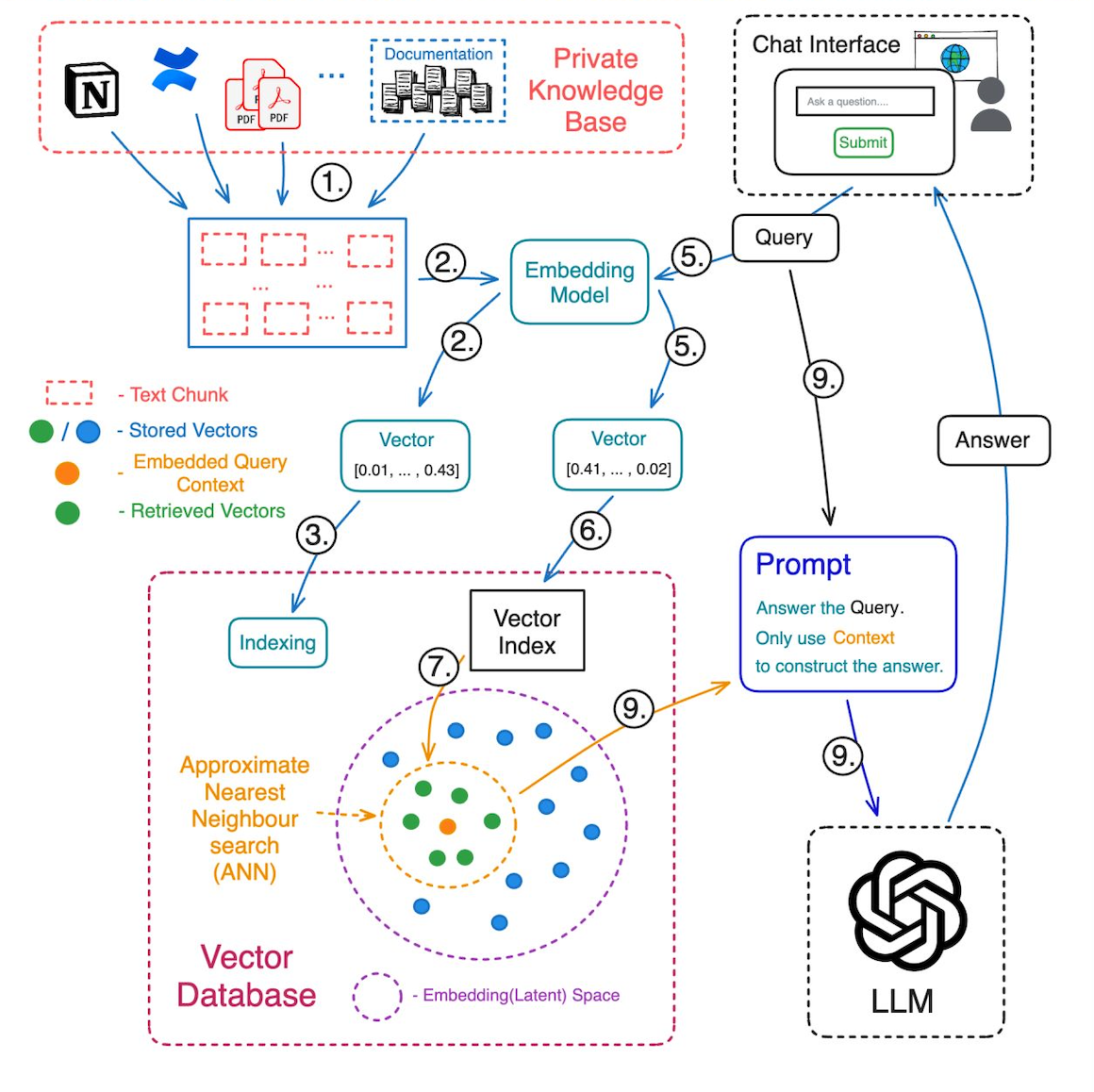
8、设计聊天机器人架构
如果没有专门构建的矢量数据库,您的聊天机器人注定会检索到不相关或不完整的数据。传统数据库无法处理语义块之间细微的关系。
DeepSeek R1与高性能矢量数据库(如Pinecone或Weaviate)搭配时表现出色。这些系统存储嵌入(可以理解为PDF块的数学指纹),并实现闪电般的相似性搜索。例如,在法律科技领域,这种设置确保聊天机器人能够立即定位500页合同中的确切条款。
此外,索引策略也很重要。对于密集数据集,使用分层可导航小世界(HNSW)索引——它更快且更准确。忽略这一点,您将面临迟缓的响应和沮丧的用户。
9、实现检索增强生成技术
大多数人关注检索算法,但这里有个秘密:结构不良的查询甚至会破坏最好的系统。
使用DeepSeek R1,您可以利用动态查询重构来即时优化用户输入。这确保检索器获取最相关的块,即使查询模糊或过于复杂。
例如,在医疗领域,医生可能会问:“儿科患者的推荐剂量是多少?”DeepSeek R1可以语义分解这个问题,优先考虑剂量指南部分,同时忽略无关内容。这种精确性是由上下文嵌入驱动的,它捕捉术语之间的微妙关系。
10、最佳实践和故障排除
使用DeepSeek R1 + RAG构建PDF聊天机器人可能感觉像组装宜家家具——理论上简单,但实际操作起来却很棘手。让我们简化一下。
从干净的数据开始。把您的PDF想象成食谱的原料。如果它们混乱——充满无关的元数据或扫描质量差的页面——您的聊天机器人就会输出垃圾。使用PyPDF2等工具提取干净、结构化的文本,并应用语义分块以保留上下文。
优化您的矢量数据库。一个缓慢的数据库就像糟糕的Wi-Fi连接——它会让用户感到沮丧。选择高性能选项,如Pinecone或Weaviate,并为您的领域微调嵌入。例如,法律聊天机器人可以从训练在案例法上的嵌入中受益。
注意幻觉。如果您的聊天机器人开始编造东西,很可能是因为检索和生成之间的对齐不佳。实施反馈循环以随着时间推移改进响应。
最后,不断测试。聊天机器人的好坏取决于其最弱的查询。
11、长查询中的上下文漂移及其解决方法
当用户提出复杂的多部分问题时,聊天机器人往往会在中途失去上下文。这是因为传统的RAG系统难以在多次检索中保持语义连贯性。
解决方案: 使用上下文分层。DeepSeek R1在此表现出色,通过将先前的响应嵌入到后续查询中,创建对话记忆。例如,在法律聊天机器人中,如果用户询问“违反合同的先例”并接着问“这对医疗保健有何影响?”,DeepSeek R1确保第二个查询保留了法律上下文。
实施递归分块并带有重叠窗口。这确保在检索过程中不会丢失关键信息,尤其是在像医学期刊或财务报告这样的密集PDF中。
上下文漂移不仅让用户感到沮丧——它还破坏了信任。通过解决它,您不仅仅是在修复一个漏洞;您正在构建一个直观且可靠的聊天机器人。
12、设计用户体验和可访问性
如果您希望聊天机器人真正引起用户的共鸣,请专注于上下文持久性。大多数聊天机器人在用户提出后续问题时失败,因为它们失去了对话流的跟踪。
DeepSeek R1的上下文分层通过维护先前交互的记忆解决了这一问题,确保查询之间的无缝过渡。想象一下一个协助患者的医疗聊天机器人。如果用户首先询问症状,然后接着问“我接下来应该做什么?”,聊天机器人必须连接这些点。没有上下文分层,响应可能泛泛而谈或无关紧要。有了它,系统会检索针对初始查询的可操作建议。
要实现这一点,请在矢量数据库中使用分层索引。这按相关性和上下文组织数据,提高检索速度和准确性。使用不同的用户组测试可访问性。小的调整,比如简化医学术语,可以使您的聊天机器人更具包容性和用户友好性。
13、结束语
使用DeepSeek R1和RAG构建PDF聊天机器人不仅仅是创建另一个AI工具——它是以精确和效率解决现实世界的问题。把它想象成从手电筒升级到激光:不是到处散射光线,而是将其聚焦在需要的地方。这就是DeepSeek R1的突出之处——它从密集且无结构的PDF中检索到完全正确的信息。
原文链接:DeepSeek R1 + RAG Tutorial: Build a PDF Chatbot That Actually Works (2025 Guide)
汇智网翻译整理,转载请标明出处
