DeepSeek-R1的推理能力分析
DeepSeek 提出了一个模型,该模型的推理能力可与 OpenAI-o1 相媲美,尽管其参数只是 OpenAI-o1 的一小部分,训练成本也低得多。

DeepSeek 提出了一个模型,该模型的推理能力可与 OpenAI-o1 相媲美,尽管其参数只是 OpenAI-o1 的一小部分,训练成本也低得多。
之前,我写了一篇文章,展示了 GPT-4o 无法有效推理的实例。其中一个例子就是“死薛定谔猫”问题。
我的一位读者在 DeepSeek-R1 上尝试了同样的提示,他告诉我 DeepSeek 的输出,实际上非常令人印象深刻!
当我问 GPT-4o 时,它的回答是这样的。显然,它没有意识到猫已经死了,猫还活着的概率是 0。

当我在 DeepSeek 上尝试同样的问题时,我注意到 LLM 像一个聪明的人一样思考,试图考虑所有可能性,避免在最终确定答案之前犯愚蠢的错误。最终,它不仅给出了正确的答案,而且解释得很好。

如果你想要更多 GPT-4o 推理失败的例子,请查看此博客 。
那时我决定需要进一步调查。DeepSeek 改进推理的秘诀是什么?

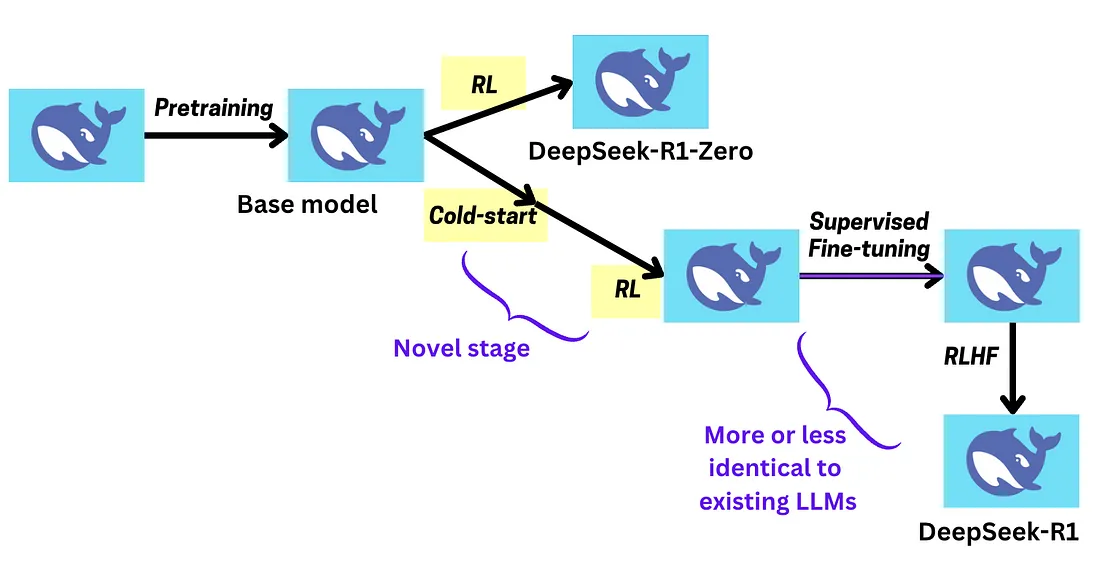
1、基础模型
所有训练方法,包括 DeepSeek 的方法,都从预训练阶段开始,然后进入“基础模型”。
基础模型是预训练后立即出现的 LLM,但在任何形式的监督微调之前。
预训练(在 LLM 中)涉及将 LLM 暴露于大量的互联网文本语料库,从而提高 LLM 预测下一个单词的能力。出现的基础模型不一定会给出有用的答案,但它们将相当熟练地掌握语言结构,并且知道在给定文本序列的情况下它们可以预测哪些单词。

最终出现的基础模型具有以下特点:
- 它理解语言的结构。它可以在给定输入问题的情况下预测一组语法流畅的下一个标记。
- 它可能无法提供有用的响应,例如它回答了一个流畅的句子但提供了不准确或不相关的答案的情况。
- 它可能会导致有害的输出,包括令人反感的答案或无法拒绝有害的请求(例如,“如何入侵某人的电子邮件”)。
大多数基础模型都可以在 HuggingFace 上找到,你可以试用它们。这些模型通常不适用于生产用例,因为它们忽略了有助于使它们更适合生产的后续步骤。
2、DeepSeek 的方法
DeepSeek-R1 与其他方法的主要区别在于它们在训练期间引入的特殊“自主” RL 步骤。请注意,这与 LLM 中已经存在的 RLHF 步骤非常不同。
RL 到底是什么?我将在这里简要解释这个想法。
2.1 RL 简介
假设一只老鼠需要学习寻找食物。
最初,老鼠会“探索”很多次,尝试随机动作并查看哪些有效。
随着时间的推移,特定的动作序列会引导老鼠获得奖励(例如食物),老鼠会学会优先考虑这些动作。在这个阶段,老鼠“利用”它已经知道的东西来最大化它的奖励。

强化学习问题有三个变量——状态、动作和奖励。
给定一个特定状态,老鼠应该“学习一个策略”,这使它能够确定应该采取什么行动来获得最大奖励。

那么 DeepSeek 究竟用强化学习做了什么?
2.2 DeepSeek-R1-Zero 的强化学习策略
我们将从 DeepSeek-R1-Zero 开始,它是 DeepSeek-R1 的简化版本。
早些时候,DeepSeek 发布了一篇名为 DeepSeekMath 的论文,他们首次介绍了这种强化学习策略。
这是他们第二次使用它。
强化学习策略的目标是让 LLM 在生成输出时更好地推理。动作对应于 LLM 生成的下一个标记,而状态对应于到目前为止生成的标记,奖励由奖励“良好输出”的特殊奖励函数确定。

你一定听说过 RLHF,这是典型的 LLM 训练阶段之一。
我想在本博客中谈到的主要区别是奖励的定义方式。
奖励函数不再基于“人工反馈”。奖励是根据以下条件自动确定的:
- 答案的正确性。模型会得到一些数学问题,通常会将得到的最终答案框起来,并且模型会因“正确的最终答案”而获得奖励。因此,通过 RL,模型会尝试优化其过程以给出更多正确的答案。

- 代码输出的正确性。训练数据集还包含编码问题,LLM 的代码输出可以简单地传递到编译器中,并在一组预定的测试用例上进行评估,类似于 LeetCode 等竞争性编程网站。

- 对思考过程的奖励。有人说这就是 DeepSeek 如此有效的秘诀。它特别奖励在
<think></think>标签内加入思考标记的 LLM。这迫使 LLM 思考,鼓励 LLM 在回答之前找出答案。

这个过程很有帮助,因为它确保我们可以使用 RL 用大量示例和高质量数据来训练 LLM。人类反馈数据可能很嘈杂,但像这里使用的客观奖励意味着更干净的数据,让 LLM 学习如何优化以获得正确答案。
3、结果如何?

此处的图表表示 LLM 在美国数学邀请考试 (AIME) 基准上的准确率。
- 蓝色图表显示通过单个模型的预测获得的准确率。
- 红色图表表示 16 个模型的一致预测。这意味着每个问题都会询问我们的 16 个 DeepSeek 模型,在计算准确率时将“多数票”作为最终答案。
RL 过程显然会随着时间的推移提高 LLM 的推理能力,显示出这种技术的强大之处。事实上,该模型在几个推理基准上的表现与 OpenAI-o1 相似!
4、DeepSeek-R1
DeepSeek-R1-Zero 的问题在于,虽然它在推理方面表现出色,但并没有产生可读的输出。
为了解决这个问题,他们实施了一些额外的步骤,例如监督微调和强化学习步骤,这些步骤不仅优先考虑推理,还优先考虑其他任务。

例如,由于我们通常希望 LLM 无害,我们可能会训练它拒绝回答任何有害的问题,例如“如何入侵某人的电子邮件”。
但 DeepSeek-R1 的一个核心区别是冷启动。
这样想:
- DeepSeek-R1-Zero 通过反复试验,以艰难的方式(如何推理)找到了答案。
- DeepSeek-R1-Zero 然后通过多个高质量示例将其学习到的知识传授给 DeepSeek-R1。这使得 DeepSeek-R1 能够以更少的训练迭代取得更大的进步。
这就是冷启动。在这个阶段,DeepSeek-R1-Zero 生成的思维链推理示例被清理、变得可读,并用于微调 DeepSeek-R1。
冷启动后,DeepSeek-R1 会经历相同的 RL 过程——它已经从 R1-Zero 中学到了很多东西,但现在继续自己解决问题。

5、结束语
这个新的 RL 管道在很大程度上促进了推理。 但这是结局吗?
我认为不是。
一个干净客观的奖励函数允许 LLM 可以使用大量数据来学习如何得出正确答案。
鼓励 LLM 在回答之前多“思考”可以确保 LLM 验证其答案并给出更准确的答案。
某些“聪明”的行为就是从这个学习过程中发展而来的。例如,LLM学习了诸如重新阅读问题、考虑所有可能性以及重新审视/重新评估其先前步骤等行为。这些“智能”行为并未明确编入LLM的程序中,而是通过为模型提供正确的激励而发展起来的。
只要提供正确的激励,人工智能系统就可以开发出人类都不知道的新推理规则。
这意味着它们“可能”有一天会比人类更聪明,即使它们是由人类建造的。
强化学习会成为实现目标的秘诀吗?
原文链接:Why I think DeepSeek-R1 just revealed the path to AGI.
汇智网翻译整理,转载请标明出处
