DeepSeek-R1训练过程解密
作为一个花大量时间与 LLM 合作并指导他人如何使用它们的人,我决定仔细研究一下 DeepSeek-R1 的训练过程。

DeepSeek 刚刚取得了突破:你可以使用纯强化学习 (RL) 训练模型以匹配 OpenAI o1 级推理,而无需使用标记数据 (DeepSeek-R1-Zero)。但仅使用 RL 并不完美——它可能导致可读性差等挑战。多阶段训练中的混合方法解决了这些问题 (DeepSeek-R1)。
GPT-4 的推出永远改变了人工智能行业。但今天,与下一波推理模型(例如 OpenAI o1)相比,它感觉就像 iPhone 4。
这些“推理模型”在推理时生成答案之前引入了思路链 (CoT) 思考阶段,从而提高了它们的推理性能。
虽然 OpenAI 对他们的方法保密,但 DeepSeek 采取了相反的方法——公开分享他们的进展,并因坚持开源使命而获得赞誉。或者正如 Marc 所说:
这个开源推理模型在数学、编码和逻辑推理等任务上与 OpenAI 的 o1 一样好,这对开源社区……和世界来说是一个巨大的胜利(Marc,这是你的话,不是我们的!)
作为一个花大量时间与 LLM 合作并指导他人如何使用它们的人,我决定仔细研究一下 DeepSeek-R1 的训练过程。以他们的论文为指导,我把所有内容拼凑在一起,并将其分解成任何人都可以遵循的内容——不需要 AI 博士学位。希望你会发现它很有用!
现在,让我们从基础知识开始。
1、快速入门
为了更好地理解 DeepSeek-R1 的主干,让我们介绍一下基础知识:
- 强化学习 (RL)
模型通过根据其行为获得奖励或惩罚来学习,并通过反复试验来改进。在 LLM 的背景下,这可能涉及传统的 RL 方法,如策略优化(例如近端策略优化,PPO)、基于价值的方法(例如 Q 学习)或混合策略(例如演员-评论家方法)。
示例:在对“2 + 2 =”这样的提示进行训练时,模型会因输出“4”而获得 +1 的奖励,而对于任何其他答案则受到 -1 的惩罚。在现代 LLM 中,奖励通常由人工标记的反馈 (RLHF) 决定,或者我们很快就会了解到,由 GRPO 等自动评分方法决定。
- 监督微调 (SFT)
使用标记数据重新训练基础模型,以便在特定任务上表现更好。示例:使用标记的客户支持问题和答案数据集对 LLM 进行微调,使其在处理常见查询时更加准确。如果您有大量标记数据,则非常适合使用。
- 冷启动数据
用于帮助模型对任务有大致了解的最低限度标记的数据集。
示例:使用从网站上抓取的 FAQ 对的简单数据集对聊天机器人进行微调,以建立基础理解。当你没有大量标记数据时很有用。
- 多阶段训练
模型分阶段进行训练,每个阶段都侧重于特定的改进,例如准确性或对齐。
示例:在一般文本数据上训练模型,然后使用强化学习对用户反馈进行改进,以提高其对话能力。
- 拒绝抽样
一种模型生成多个潜在输出的方法,但只选择满足特定标准(例如质量或相关性)的输出以供进一步使用。示例:在 RL 过程之后,模型会生成多个响应,但只保留对重新训练模型有用的响应。
2、第一个模型:DeepSeek-R1-Zero
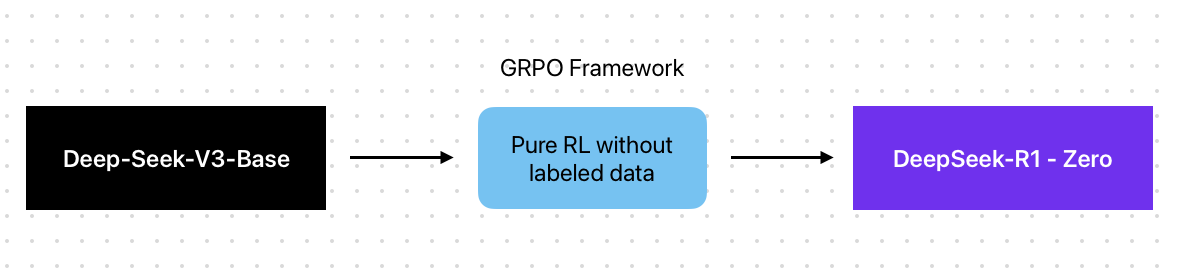
DeepSeek 团队希望证明是否可以使用纯强化学习 (RL) 来训练强大的推理模型。这种形式的“纯”强化学习无需标记数据即可工作。
跳过标记数据?对于 LLM 领域的 RL 来说,这似乎是一次大胆的举动。
我了解到,纯强化学习在前期速度较慢(反复试验需要时间)——但它消除了昂贵且耗时的标记瓶颈。从长远来看,它将更快、可扩展,并且更有效地构建推理模型。主要是因为它们可以自行学习。
DeepSeek 成功进行了纯强化学习训练——与 OpenAI o1 的表现相当。
称其为“巨大成就”似乎有些轻描淡写——这是第一次有人成功做到这一点。不过,OpenAI 也许首先用 o1 做到了,但我们永远不会知道,不是吗?
我脑海中最大的疑问是:“他们是如何做到的?”
让我们来介绍一下我发现的内容。
3、使用 GRPO RL 框架
传统上,用于训练 LLM 的 RL 与标记数据(例如 PPO RL 框架)结合使用时最为成功。这种 RL 方法采用了一种类似于“LLM 教练”的批评模型,对每个动作提供反馈以帮助模型改进。它根据标记数据评估 LLM 的操作,评估模型成功的可能性(价值函数)并指导模型的整体策略。
挑战?
这种方法受到用于评估决策的标记数据的限制。如果标记数据不完整、有偏见或没有涵盖所有任务,评论家只能在这些限制内提供反馈——而且它不能很好地概括。
进入,GRPO!
作者使用了组相对策略优化 (GRPO) RL 框架(由同一个团队发明,wild!),它消除了评论家模型。
使用 GRPO,你可以跳过“教练”——并且 LLM 动作会通过使用预定义的规则(如连贯性和/或流畅性)在多轮中评分。这些模型通过将这些分数与小组的平均分数进行比较来学习。
但是等等,他们怎么知道这些规则是否是正确的规则?
在这种方法中,规则并不完美——它们只是对“好”是什么样子的最佳猜测。这些规则旨在捕捉通常有意义的模式,例如:
- 答案有意义吗?(连贯性)
- 格式正确吗?(完整性)
- 它符合我们期望的一般风格吗? (流畅度)
例如,对于 DeepSeek-R1-Zero 模型,对于数学任务,即使不知道确切答案,该模型也可以因产生符合数学原理或逻辑一致性的输出而获得奖励。
这很有意义……而且有效!
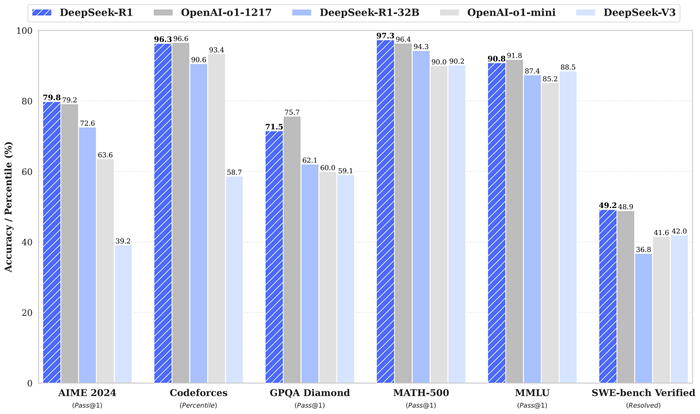
DeepSeek-R1-Zero 模型在推理基准测试中表现出色。此外,它在 AIME 2024(一项针对高中生的著名数学竞赛)上的 pass@1 分数为 86.7%,与 OpenAI-o1-0912 的表现相当。
虽然这似乎是这篇论文的最大突破,但 R1-Zero 模型并没有带来一些挑战:可读性差和语言混合。
4、第二个模型:DeepSeek-R1
可读性差和语言混合是使用纯 RL 时会出现的问题,没有标记数据提供的结构或格式。
现在,通过这篇论文,我们可以看到多阶段训练可以缓解这些挑战。在训练 DeepSeek-R1 模型时,使用了许多训练方法:
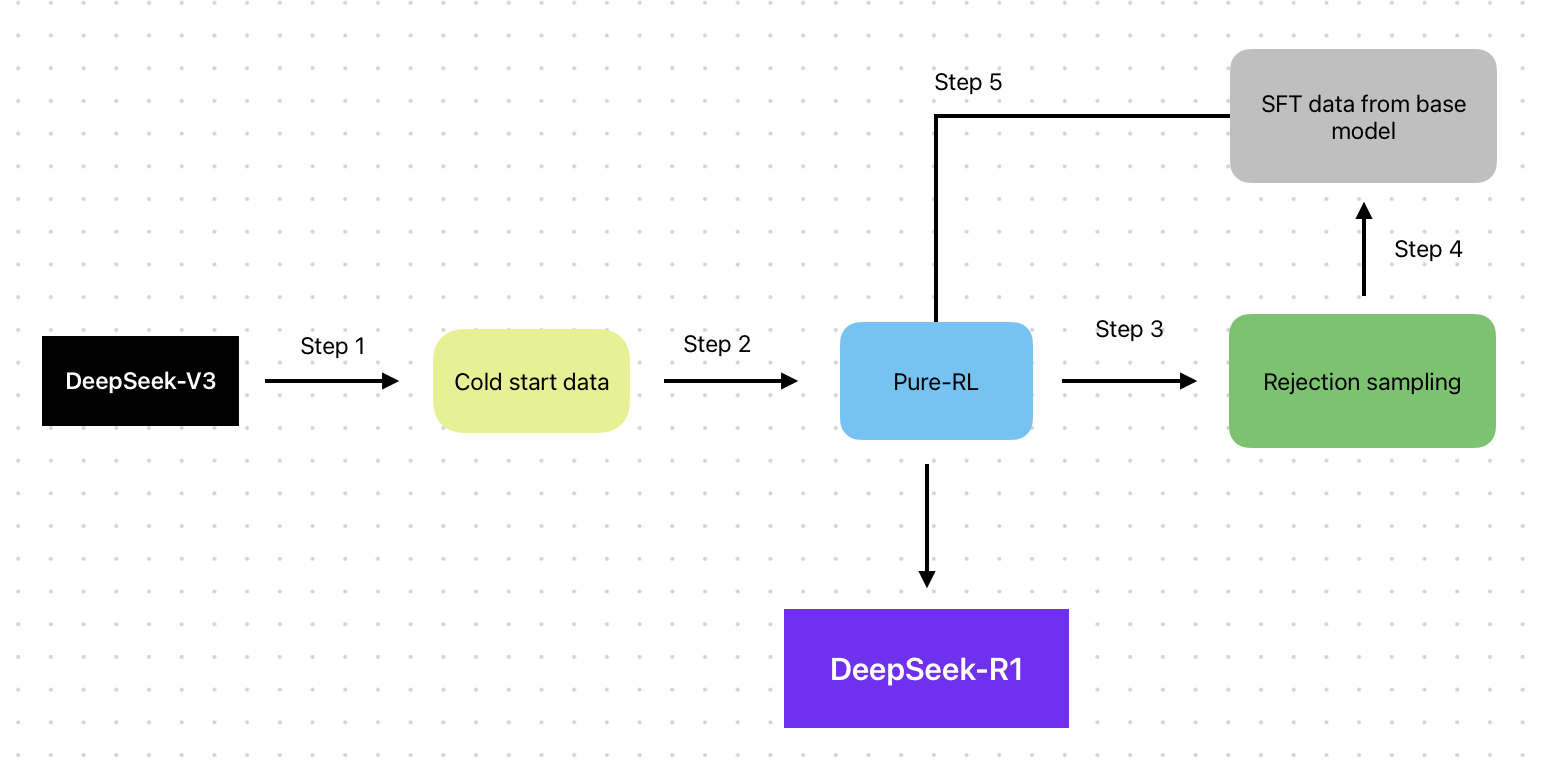
以下是每个训练阶段及其所做工作的简要说明:
步骤 1:他们使用数千个冷启动数据点对基础模型 (DeepSeek-V3-Base) 进行微调,以奠定坚实的基础。仅供参考,与大规模监督学习通常所需的数百万甚至数十亿个标记数据点相比,数千个冷启动数据点只是很小的一部分。
步骤 2:应用纯 RL(类似于 R1-Zero)来增强推理能力。
步骤 3:在 RL 收敛附近,他们使用拒绝抽样,其中模型通过从上次成功的 RL 运行中选择最佳示例来创建自己的标记数据(合成数据)。你听说过 OpenAI 使用较小的模型为 O1 模型生成合成数据的那些传言吗?基本上就是这样。
步骤 4:将新的合成数据与 DeepSeek-V3-Base 中的监督数据合并,这些数据涉及写作、事实问答和自我认知等领域。此步骤确保模型可以从高质量输出和各种特定领域知识中学习。
步骤 5:在使用新数据进行微调后,模型将针对各种提示和场景进行最终的 RL 过程。
这感觉像是黑客攻击——那么为什么 DeepSeek-R1 使用多阶段过程?
因为每一步都建立在最后一步的基础上。
例如 (i) 冷启动数据奠定了结构化基础,解决了可读性差等问题,(ii) 纯 RL 几乎可以自动进行推理 (iii) 拒绝采样 + SFT 与顶级训练数据配合使用,可提高准确性,(iv) 另一个最终 RL 阶段可确保额外的泛化水平。
通过在训练过程中增加所有这些额外步骤,DeepSeek-R1 模型在下面显示的所有基准测试中都取得了高分:
5、推理时的 CoT 依赖于 RL
为了在推理时有效地使用思路链,这些推理模型必须使用强化学习等方法进行训练,以鼓励在训练过程中逐步推理。这是一条双向道路:为了使模型实现顶级推理,它需要在推理时使用 CoT。而为了在推理时启用 CoT,必须使用 RL 方法训练模型。
如果我们考虑到这一点,我很好奇为什么 OpenAI 没有透露他们的训练方法——尤其是因为 o1 模型背后的多阶段过程似乎很容易进行逆向工程。
很明显,他们使用了 RL,从 RL 检查点生成合成数据,并应用了一些监督训练来提高可读性。那么,他们仅仅通过将竞争对手 (R1) 放慢 2-3 个月,真正取得了什么成就?
我想时间会证明一切。
6、如何使用 DeepSeek-R1
要使用 DeepSeek-R1,你可以在其免费平台上进行测试,或者获取 API 密钥并在你的代码中或通过 Vellum 等 AI 开发平台使用它。Fireworks AI 还为该模型提供了推理端点。
DeepSeek 托管模型每百万输入令牌仅需 0.55 美元,每百万输出令牌仅需 2.19 美元——与 OpenAI 的 o1 模型相比,其输入成本大约低 27 倍,输出成本大约低 27.4 倍。
此 API 版本支持最大上下文长度为 64K,但不支持函数调用和 JSON 输出。然而,与 OpenAI 的 o1 输出相反,你可以同时检索“推理”和实际答案。它也非常慢,但没有人关心这些推理模型,因为它们解锁了新的可能性,而即时答案并不是优先事项。
此外,此版本不支持许多其他参数,例如: temperature、 top_p、 presence_penalty、 frequency_penalty、 logprobs、 top_logprobs,这使得它们在生产中使用起来有点困难。
以下 Python 代码演示了如何使用 R1 模型并访问 CoT 流程和最终答案:
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
# Round 1
messages = [{"role": "user", "content": "9.11 and 9.8, which is greater?"}]
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
reasoning_content = response.choices[0].message.reasoning_content
content = response.choices[0].message.content
# Round 2
messages.append({'role': 'assistant', 'content': content})
messages.append({'role': 'user', 'content': "How many Rs are there in the word 'strawberry'?"})
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
# ...我建议你玩一下,看它“思考”很有趣
7、小模型也可以很强大
作者还展示了可以将较大模型的推理模式蒸馏为较小的模型,从而获得更好的性能。
使用 Qwen2.5-32B (Qwen, 2024b) 作为基础模型,DeepSeek-R1 的直接蒸馏效果优于仅在其上应用 RL。这表明,较大的基础模型发现的推理模式对于提高较小模型的推理能力至关重要。模型蒸馏正在成为一种非常有趣的方法,它反映了大规模的微调。
结果也相当有力——经过蒸馏的 14B 模型的表现远胜于最先进的开源 QwQ-32B-Preview,而经过蒸馏的 32B 和 70B 模型在密集模型的推理基准上创下了新纪录:
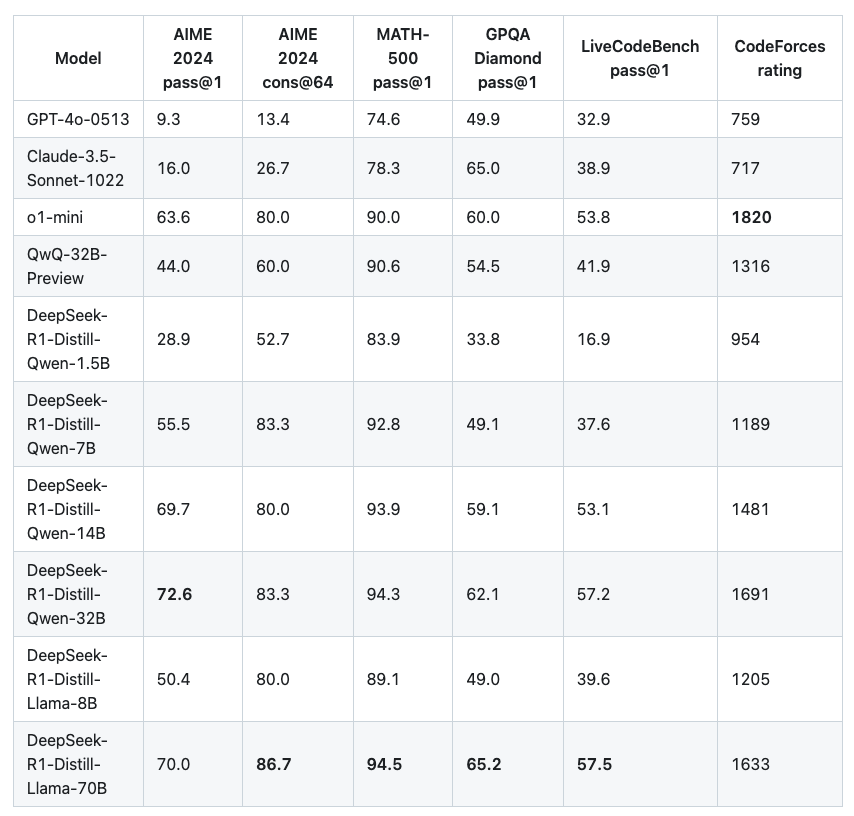
8、结束语
这是我的看法:DeepSeek 刚刚展示了你可以用纯 RL 显著提高 LLM 推理能力,不需要标记数据。更妙的是,他们结合了训练后技术来解决问题并将性能提升到一个新的水平。
预计未来几周(而不是几个月)将出现大量像 R1 和 O1 这样的模型。
我们认为模型扩展会遇到瓶颈,但这种方法正在释放新的可能性,意味着更快的进展。换个角度来看,OpenAI 从 GPT-3.5 到 GPT-4 花了 6 个月的时间。DeepSeek 仅用 2 个月就达到了 O1 的性能——不知道 OpenAI 是如何做到的!
准备好迎接新一波模型吧,它们会让 O1 看起来很慢。
原文链接:Breaking down the DeepSeek-R1 training process—no PhD required
汇智网翻译整理,转载请标明出处
