DeepSeek R1推理能力的训练配方
DeepSeek R1 的训练分为 4 个阶段,本文将每个训练阶段分解为其核心组件、见解和未解决的问题。

DeepSeek AI 发布了他们的第一个成熟的推理模型。它是:
- 旗舰推理语言模型 R1,通过 4 阶段、RL 密集过程进行训练。它是 MIT 授权的,这意味着公司和研究人员可以在其输出的基础上进行构建和训练,以加速推理语言模型 (RLM) 的开发和部署。
- 直接从他们的 V3 基础模型 R1-Zero(用于为完整 R1 创建训练数据)训练的 RL 专用推理模型。
- 一套开放权重模型,使用来自 R1 的监督微调 (SFT) 数据进行微调(类似于他们的中间训练步骤之一的数据)。
- 一份详细介绍他们的 RL 训练方法的技术报告。
- 模型可在 chat.deepseek.com及其新应用中获取。
这篇文章与评估结果(当然,结果非常好,如下所示)关系不大,而是关于如何进行训练以及这一切意味着什么。
这是推理模型研究不确定性的一个重要转折点。到目前为止,推理模型一直是工业研究的主要领域,没有明确的开创性论文。在语言模型起飞之前,我们有 GPT-2 论文用于预训练或 InstructGPT(和 Anthropic 的白皮书)用于后训练。对于推理,我们盯着可能具有误导性的博客文章。推理研究和进展现已锁定——预计 2025 年将取得巨大进展,而且更多的进展将公开。
这再次证实,新的技术配方通常不是护城河——概念验证或泄密的动机通常会让知识流传出去。
首先,看看这些推理模型的定价。 OpenAI 可能因为长期上下文服务的成本以及它是市场上唯一的模型而对其模型收取更高的费用,但现在 o1 的定价为每百万输入令牌 15 美元/输出 60 美元,相对于 R1 的定价为每百万输入令牌 0.55 美元/输出 2.19 美元,显得格格不入(是的,o1-mini 更便宜,为每百万 3 美元/12 美元,但仍然相差近 10 倍)。推理模型即将到来的价格战将看起来像 2023 年的 Mixtral 推理价格战。
有了 o3,OpenAI 可能在技术上处于领先地位,但它并不普遍可用,而且权重也不会很快可用。这表明,自 Stable Diffusion 发布以来,最相关和讨论最多的 AI 模型首次以非常友好的许可证发布。回顾过去 2.5 年“开源”AI 走过的历程,这是历史上一个令人惊讶的时刻。
我们并不完全清楚这些模型在未来除了代码和数学之外还会有怎样的用途,但不断有声音称,OpenAI 的 o1-Pro 是许多更具挑战性的任务的最佳模型(我需要亲自尝试才能做出明确的建议)。
现在最有用的帖子是建立研究领域、该做什么和不该做什么以及未解决的问题。让我们深入了解细节。
DeepSeek R1 推理训练配方
R1 的训练分为 4 个阶段:
- 对来自 R1-Zero 模型的合成推理数据进行监督微调的“冷启动”。
- 对推理问题进行大规模强化学习训练“直到收敛”。
- 对 3/4 推理问题和 1/4 一般查询进行拒绝抽样,以开始向通用模型过渡。
- 强化学习训练将推理问题(可验证奖励)与一般偏好调整奖励模型相结合,以完善模型。
下面的帖子将每个训练阶段分解为其核心组件、见解和未解决的问题。
o1 复制之风一直强烈地远离任何类型的显式搜索(尤其是在推理时)。它确实是一个语言模型,新的推理行为来自大量的 RL 训练。
在我们开始之前,请记住,要做好这种推理训练,你需要一个具有长上下文能力的非常强大的基础模型。就像标准的后训练一样,我们真的不知道基础模型有什么特征更适合直接进行 RL 训练。
步骤 0. 训练 R1-Zero 以使用合成数据初始化 R1
DeepSeek R1 Zero 最为人所知的是第一个使用“大规模强化学习 (RL) 训练的开放模型,无需监督微调 (SFT) 作为初步步骤”。有传言称 o1 也是如此,但对其工作原理的理解尚不清楚。这是一个古怪的模型,DeepSeek 报告称,它有时会改变推理语言或显示出其他可靠性问题的迹象。
R1-Zero 的轻微可用性问题表明,为什么训练出色的推理模型需要的不仅仅是大规模 RL,但 RL 部分是解锁我们正在寻找的推理行为的关键。
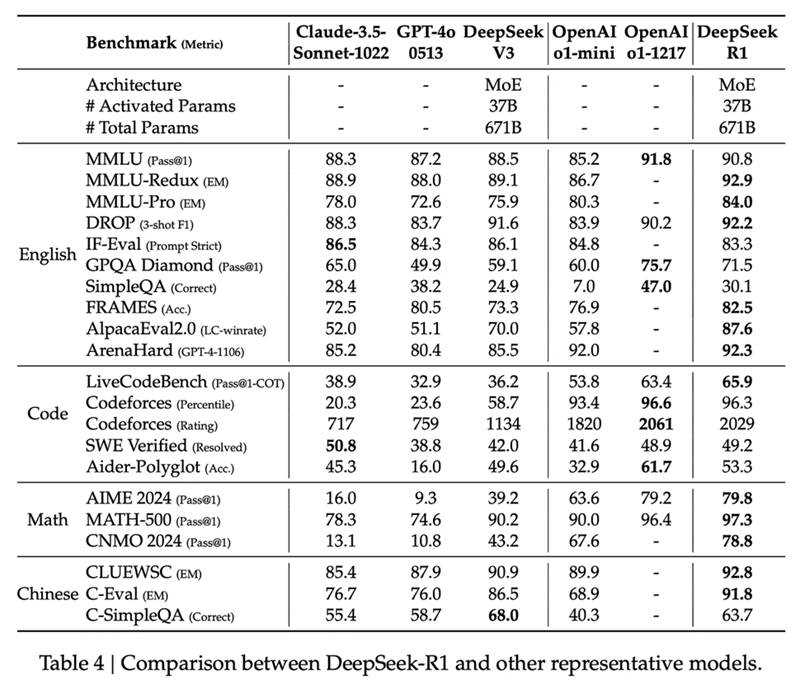
它们包括 R1-Zero 最有趣的结果,包括我一直要求的 RL 训练时间缩放图。自 o1 发布以来,每个人都痴迷于展示推理时间与评估性能之间关系的图表。推理时间更容易引出(或通过使用蒙特卡洛树搜索等框架强制实现),但通过 RL 展示训练时间的改进才是真正的基础结果。这是我在研究中寻找的结果。
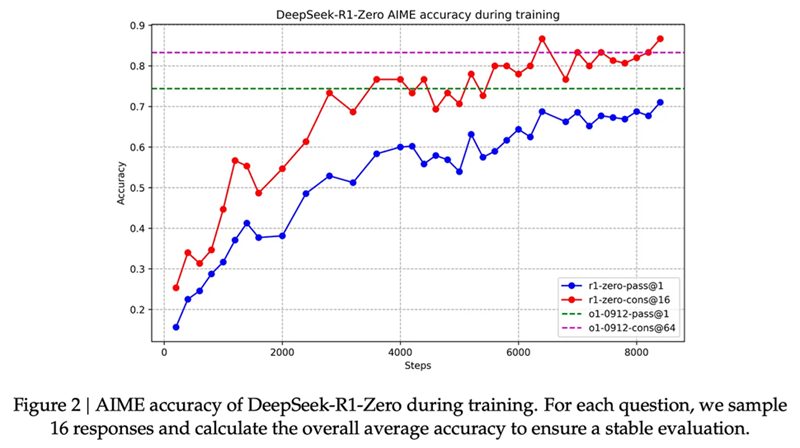
还有一个不足为奇但非常令人满意的长度随训练而增长的图表。这可以与上面的图混合,形成我们已经见过的许多版本的“推理时间缩放”图之一,但方法不太明确。
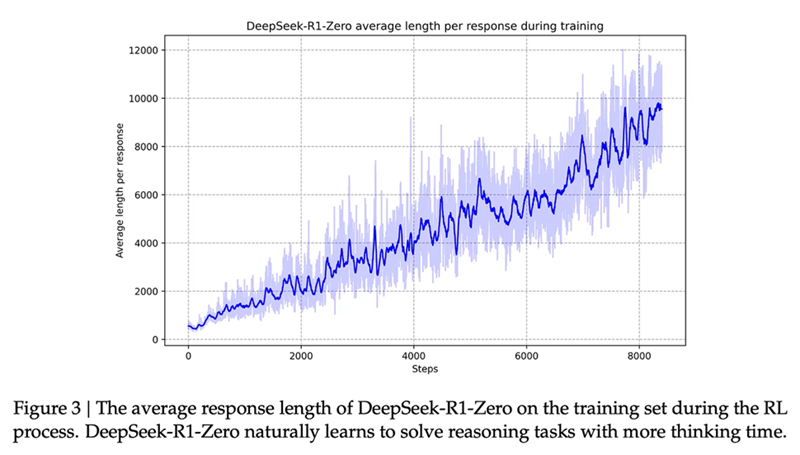
在这两个图中,如果让 RL 煮得更久,数字似乎还会上升。随着进展速度如此之快,这些实验室通过结束接近饱和的工作并开始下一个实验而不是寻求最后的 1%,可以获得更多收益。
大多数(如果不是全部)研究人员将跳过训练 R1-Zero 风格模型的步骤,因为他们不需要这样做。 DeepSeek 明确表示,他们对 SFT 推理轨迹的“冷启动”使最终的 R1 模型变得更好——这并不奇怪,因为他们希望 R1 成为某种类型的指令调整模型。这将有助于避免 DeepSeek 提到的 R1-Zero 中的一些“RL 怪异现象”,例如在生成中期更改语言。
尽管如此,RL-on-base-models 领域应该进一步研究。R1-Zero 的训练方式非常巧妙,因为大多数未经任何指令调整的基础模型都存在漫无目的且永远不会生成停止标记的主要问题。R1-Zero 通过系统提示告诉模型生成 HTML 标记来避免这种情况。此外,我怀疑这种类型的训练不适用于较旧的基础模型,因为这些模型在预训练语料库中没有一些标准的训练后风格指令数据。例如,在 OLMo 2 中,我们在退火混合中有一些数学指令数据。只需几条指令就可以让这个系统提示工作。
事实上,当直接从基础模型而不是没有冗长思路链风格的标准后训练模型进行训练时,通过 RL 训练增加代长度的趋势可能会更强。为了让 RL 真正开始在这种指令跟随模型中增加响应长度,它必须忘记已经嵌入的某个响应长度。例如,在 Tülu 3 的 RL 微调的最后阶段,响应率首次下降的阶段可能是较大轮次的 SFT 训练与较小轮次的 RL 设置之间不一致的障碍。
放大这些 R1-Zero 图的 x 轴,你可以看到它们正在执行 1000 个“RL 步骤”。在这种情况下,RL 步骤是指模型更新步骤,该步骤是在对批次中的提示进行多次生成并验证答案之后进行的。3 这是大量的 RL 训练,尤其是对于如此大的模型。作为参考,在我们的 Tülu 3 工作中,我们通常针对 100 步对模型进行微调,而我们即将发布的最大模型仅针对约 50 步的 RL 进行训练。
相对于现有文献,这是扩大的 RL。R1 本身肯定使用了类似的设置,但 DeepSeek 没有包含相同的细节,因此本文的其余部分更多地依赖于论文中的明确文本。
步骤 1. 推理 SFT“冷启动”
为了提高可读性(即帮助维护格式)并提高最终推理模型的最终性能,DeepSeek 使用来自 R1-Zero 模型的“几千个”过滤完成对原始基础模型进行了少量监督微调。这涉及一些技巧(这些技巧似乎都不是必不可少的,你只需要一些数据),例如:
以长 CoT 的少样本提示为例,直接提示模型通过反射和验证生成详细答案,以可读格式收集 DeepSeek-R1-Zero 输出,并通过人工注释者的后处理来完善结果。
对于复制工作,可以做到其中任何一点。事实上,使用 DeepSeek-R1 本身就可能是最简单的方法。
此阶段为模型的损失状况做好准备,使“突发”行为(如“等一下,让我检查一下我的工作”或“那是错的”)在 RL 训练中更容易出现。
步骤2:大规模 RL 用于推理
提醒一下,RL 用于推理模型建立在一个简单的想法上,即您应该奖励模型获得问题的正确答案,您可以检查它是否有正确的答案。此的基本反馈循环如下所示:
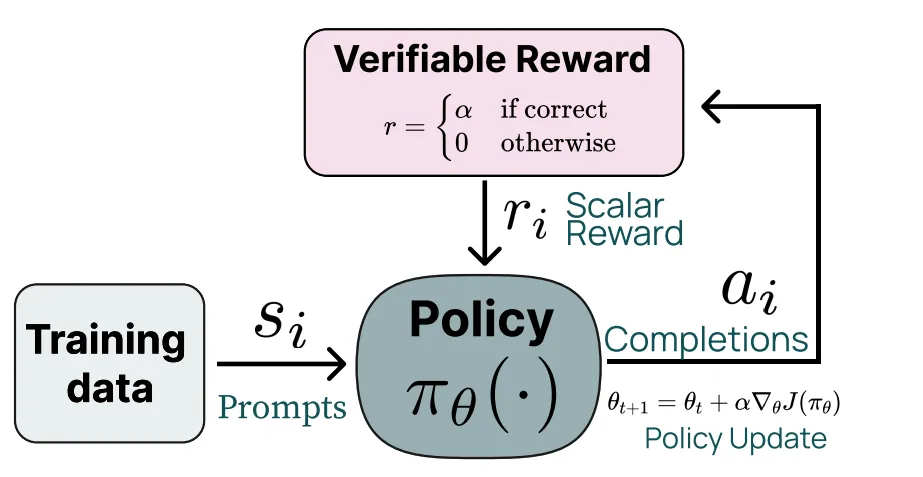
这里的“奖励”到底是什么(同样的问题适用于 R1-Zero)没有详细说明。DeepSeek 在 RL 的推理阶段提到了三个奖励组成部分:
- 准确度奖励:如果对提示的响应正确,则这些是分数奖励。我一直将这些称为“可验证”领域,在 OpenAI 的强化微调中,这由他们的评分员处理。TLDR:如果答案正确,奖励为正,如果不正确,则为 0.5
- 格式奖励:这些是奖励(或不满足则惩罚),用于检查并确保模型遵循正确的格式 或 和 和 以实现稳定的推理。
- 语言一致性奖励:如果答案的语言与问题的语言 100% 匹配,则会向模型添加奖励。DeepSeek 写道,这个额外的奖励表明“模型性能略有下降”,但人类偏好更好。它被添加是为了让模型更好用,这是一个很好的提醒,评估分数并不是最重要的。
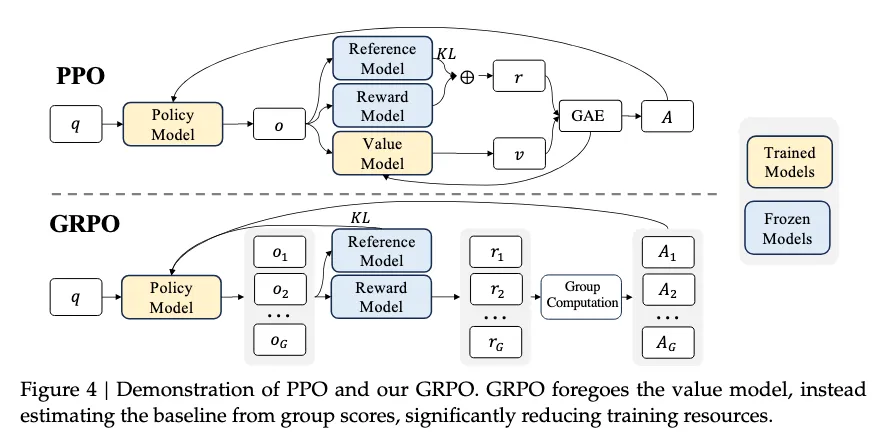
这里的第一个奖励推动了大部分学习,而其他两个奖励是创建稳定模型的护栏(这并不是说它们不是重要的实施细节,而是第一个奖励是必要的,而其他奖励可能不是)。为了优化这个奖励,DeepSeek 使用了他们引入的 RL 算法,即 Group Relative Policy Optimization,它是基于蒙特卡洛优势估计的不同值近似方法的 PPO 更新规则,而不是在内存中保存单独的值模型。这种选择最有可能的解释(就像 OpenAI 一直使用 PPO 的方式一样)是它是他们基础设施中成熟的实现。
DeepSeekMath 论文中的这张图片是对 PPO 和 GRPO 的精彩比较(如果你只关心大局,可以跳过这一点):
奖励设置(和数据)的性质是这种推理训练的关键,许多小的 RL 细节可以相互替代。
与 DeepSeek V3 论文非常相似,他们用于训练模型的数据细节并未包含在此处。这绝对至关重要,而且几乎肯定涉及许多可验证的提示和答案。为了研究这些模型,社区需要这些数据集的开放版本。
我很想看到他们的 RL 基础设施的细节(类似于 DeepSeek V3 论文中的细节),因为很多人都希望在这些模型的基础上进行构建。RL 训练需要在内存中保存多个模型,并在生成、验证和采取损失步骤之间交替进行。正如 Sasha Rush 所说,“我们需要尽快编写验证器”,这正是我们在 Tülu 3 上的 Ai2 构建中尝试做的事情,并且可以使用开源代码提供大量帮助。6 对于对此感兴趣的实体来说,一个好方法是一次为一个领域开发工具和数据。
这前两个步骤并不是新的,而是人们广泛讨论的想法的扩展版本。 DeepSeek 在论文中详细介绍的最后两个步骤是已知技术的新应用,以帮助提高其原始推理性能并“训练用户友好的模型”。
步骤 3 拒绝抽样以引入一般能力
拒绝抽样是一种技术,你可以从模型中生成完成,通过奖励模型对其进行排名,然后微调原始模型(通常使用监督微调损失)以提高各种任务的性能。它是 Llama 3 和许多其他人使用的标准训练后工具之一。
DeepSeek 使用拒绝抽样开始将一般能力重新引入模型。这也是他们包含数据数量的一个阶段——总共 800K 个完成,分为 600K 用于推理和 200K 用于一般聊天问题。鉴于这只是后期的 SFT 训练,800K 这个数字对我来说并不奇怪,但它的大小与我们在 Tülu 3 SFT 组合中使用的约 1M 个提示相似,而 Tülu 3 SFT 组合是领先的训练后配方的大致范围。
本文中的细节主要围绕生成对提示的响应和过滤以优先考虑高质量训练数据的方法。为了将更多领域纳入模型的能力范围,DeepSeek 有各种技巧,例如:
- 使用生成奖励模型(即 LLM-as-a-judge)来验证可能无法明确验证的问题的答案,
- 来自 DeepSeek-V3 标准后训练管道,以及
- 标准(不可验证)聊天数据,在回答之前通过扩展的思维链进行增强,以帮助模型从推理训练推广到更广泛的用例。
总而言之,我们目前在这里的细节很少,还有很大的学习空间(并且可能会改进)。
步骤 4 最终的 RL 训练以供一般使用
最后,DeepSeek R1 回到强化学习,这似乎是目前大多数微调的结束方式。第二个 RL 阶段“旨在提高模型的有用性和无害性,同时完善其推理能力。”
为了做到这一点,他们进行 RL 训练,将来自可验证域的提示(如 R1-Zero 所做的那样)和标准 RLHF 偏好调整的提示混合在一起。为了做到这一点,他们有多个奖励模型,并在 DeepSeek V3 中的后训练配方的基础上进行构建。
这并不容易做到,而且涉及许多问题:正确的数据平衡是什么?您可以使用现成的现有奖励模型吗?还是需要看到长时间的推理轨迹?是否需要额外的步骤来不降低性能?等等。
随着这成为一个更大的研究和开发领域,这些问题将慢慢得到解答。
随着这篇文章进入训练的后期阶段,很明显许多细节尚不清楚。我们对如何对事物进行排序有了大致的了解,并将从这里开始补充细节。我有一大堆与推理相关的研究论文需要研究,虽然它们出现在 DeepSeek R1 之前,但它们仍然会指向答案。
所有这些都是可以解决的,正如 DeepSeek 从 o1 版本到与开放权重模型匹配性能的速度所证明的那样。
原文链接:DeepSeek R1's recipe to replicate o1 and the future of reasoning LMs
汇智网翻译整理,转载请标明出处
