DeepSeek R1 vs. V3:如何选择?
在手机或桌面上使用 DeepSeek 应用程序时,我们可能会不确定何时选择 R1(也称为 DeepThink),而不是日常任务的默认 V3 模型。

在手机或桌面上使用 DeepSeek 应用程序时,我们可能会不确定何时选择 R1(也称为 DeepThink),而不是日常任务的默认 V3 模型。
对于开发人员来说,挑战有点不同。当通过其 API 集成 DeepSeek 时,挑战在于找出哪种模型更符合我们的项目要求并增强功能。
在此博客中,我将介绍这两种模型的关键方面,以帮助你更轻松地做出这些选择。我将提供示例来说明每个模型在不同情况下的行为和性能。我还会为你提供一个决策指南,可以使用它来在 DeepSeek-R1 和 DeepSeek-V3 之间进行选择。
1、DeepSeek-V3 和 DeepSeek-R1
DeepSeek 是一家中国 AI 初创公司,它以比 OpenAI 的 o1 低得多的成本开发了 DeepSeek-R1,引起了国际关注。就像 OpenAI 有我们都知道的 ChatGPT 应用程序一样,DeepSeek 也有类似的聊天机器人,它有两个模型:DeepSeek-V3 和 DeepSeek-R1。
1.1 什么是 DeepSeek-V3?
DeepSeek-V3 是我们与 DeepSeek 应用程序交互时使用的默认模型。它是一种多功能的大型语言模型 (LLM),是一种可以处理各种任务的通用工具。

该模型与其他知名语言模型(如 OpenAI 的 GPT-4o)竞争。
DeepSeek-V3 的主要功能之一是它使用了混合专家 (MoE) 方法。这种方法允许模型从不同的“专家”中进行选择来执行特定任务。在你向模型提供提示后,只有模型中最相关的部分才会针对任何给定任务处于活动状态,从而节省计算资源并提供精确的结果。
本质上,DeepSeek-V3 是我们需要 LLM 完成的大多数日常任务的可靠选择。但是,与大多数 LLM 一样,它使用下一个单词预测来工作,这限制了它解决需要推理的问题或提出训练数据中未以某种方式编码的新答案的能力。
1.2 什么是 DeepSeek-R1?
DeepSeek-R1 是一个强大的推理模型,专为解决需要高级推理和深度解决问题的任务而构建。它非常适合解决编码挑战,这些挑战不仅仅是重复编写了数千次的代码和逻辑繁重的问题。
当要解决的任务需要高级认知操作(类似于专业或专家级推理)时,可以将其视为你的首选。
我们通过单击“DeepThink (R1)”按钮来激活它:

DeepSeek-R1 的与众不同之处在于它对强化学习的特殊使用。为了训练 R1,DeepSeek 在 V3 奠定的基础上构建,利用其广泛的功能和巨大的参数空间。他们通过允许模型为解决问题的场景生成各种解决方案来执行强化学习。然后使用基于规则的奖励系统来评估答案和推理步骤的正确性。这种强化学习方法鼓励模型随着时间的推移完善其推理能力,有效地学习自主探索和开发推理路径。
DeepSeek-R1 是 OpenAI 的 o1 的直接竞争对手。
V3 和 R1 之间的一个区别是,当与 R1 聊天时,我们不会立即得到回复。该模型首先使用思维链推理来思考问题。只有当它完成思考后,它才会开始输出答案。

这也意味着,一般来说,R1 的响应速度比 V3 慢得多,因为思考过程可能需要几分钟才能完成,我们将在后面的例子中看到。
2、V3 和 R1 之间的差异
让我们从各个方面来看一下 DeepSeek-R1 和 DeepSeek-V3 之间的差异:
2.1 推理能力
DeepSeek-V3 没有推理能力。正如我们所提到的,它充当下一个单词预测器。这意味着它可以回答答案编码在训练数据中的问题。
由于用于训练这些模型的数据量非常庞大,因此它几乎可以回答任何主题的问题。与其他 LLM 一样,它在自然对话和创造力方面表现出色。这是我们想要的模型,用于创作文章、内容创作或回答可能已经被解决过无数次的一般问题。
另一方面,DeepSeek-R1 在解决复杂的问题、逻辑和逐步推理任务时表现出色。它旨在解决需要彻底分析和结构化解决方案的具有挑战性的查询。当面对复杂的编码挑战或详细的逻辑谜题时,R1 是值得信赖的工具。

2.2 速度和效率
DeepSeek-V3 受益于其混合专家 (MoE) 架构,使其能够更快、更有效地做出响应。这使得 V3 适用于速度至关重要的实时交互。
DeepSeek-R1 通常需要更长的时间来生成响应,但这是因为它专注于提供更深入、更结构化的答案。额外的时间用于确保全面和深思熟虑的解决方案。

2.3 内存和上下文处理
两种模型都可以处理多达 64,000 个输入标记,但 DeepSeek-R1 特别擅长在长时间交互中保持逻辑和上下文。这使得它适合于需要在长时间对话或复杂项目中持续推理和理解的任务。

2.4 最适合 API 用户
对于使用 API 的用户,DeepSeek-V3 提供了更自然、更流畅的交互体验。它在语言和对话方面的优势使用户交互感觉流畅且引人入胜。
R1 的响应时间对许多应用程序来说可能是一个问题,因此我建议仅在绝对必要时使用它。
请注意,使用 API 时的模型名称不是 V3 和 R1。 V3 模型名为 deepseek-chat,而 R1 模型名为 deepseek-reasoner。
2.5 定价差异
在考虑使用哪种模型时,值得注意的是 V3 比 R1 便宜。虽然本博客侧重于功能,但重要的是要权衡与每种模型相关的成本以及我们的具体需求和预算。有关成本的更多详细信息,请查看其 API 定价文档。
3、DeepSeek-R1 vs. V3:DeepSeek Chat示例
3.1 问题解决和逻辑任务
让我们通过提出以下问题来比较两种模型的推理能力:
"Use the digits [0-9] to make three numbers: x,y,z so that x+y=z"翻译:“使用数字 [0-9] 组成三个数字:x、y、z,使得 x+y=z”
例如,一个可能的解决方案是:x = 26、y = 4987 和 z = 5013。它使用所有数字 0-9 且 x + y = z。
当我们向 V3 提出这个问题时,它立即开始给出一个冗长的答案,并最终得出了没有解决方案的错误结论:

另一方面,R1 经过大约 5 分钟的推理后就能找到解决方案:
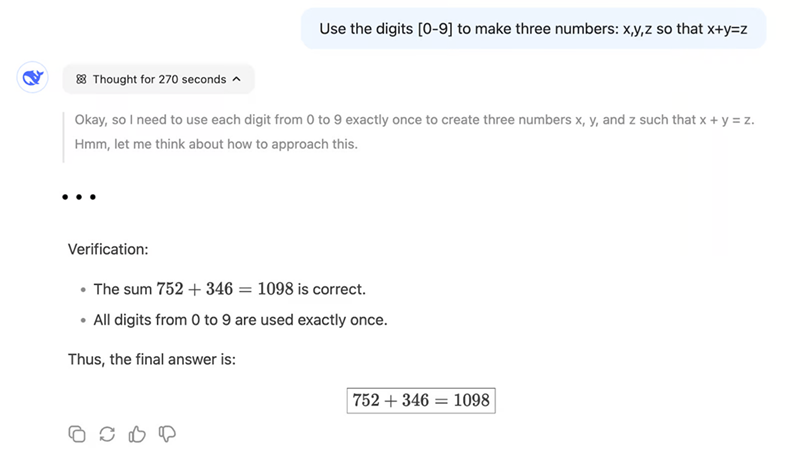
这表明 R1 更适合需要数学推理的问题,因为像 V3 这样的下一个单词预测不太可能走上正确的道路,除非在模型训练期间使用了许多类似的问题。
3.2 创作写作
现在,让我们关注创意写作。让我们要求两个模型写一篇关于人群中孤独的微型小说。
"Write a microfiction story about loneliness in a crowd"翻译:“写一篇关于人群中孤独的微型小说”
这是 V3 的输出:

我们立即得到了一个符合主题的故事。我们可能喜欢或不喜欢,这是主观的,但答案与我们要求的一致。
在使用推理时,模型推理来创作故事。我们不会在这里展示所有的细节,但它将任务分解为如下步骤:
- 首先,我应该设置场景……
- 接下来,感官细节……
- 我需要展示他们的内部状态……
- 以一个凄美的图像结束……
- 让我检查一下我是否涵盖了所有元素……
我们可以看到,创作过程非常结构化,这可能会降低输出的创造力。

我认为,只有当我们对推理过程感兴趣时,我们才应该将 R1 用于这种任务,因为我们想要的输出不是逻辑思维过程的结果,而是创造性的结果。
3.3 编码协助
在这个第三个例子中,我们要求 DeepSeek 帮助修复一个略有错误的 Python 函数,该函数旨在解决以下问题:
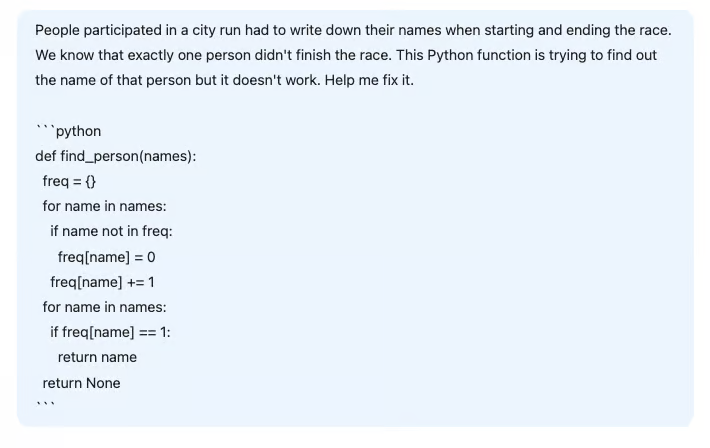
"People participating in a city run had to write down their names when starting and ending the race. We know that exactly one person didn't finish the race. This Python function is trying to find out the name of that person but it doesn't work. Fix it."
```
def find_person(names):
freq = {}
# Calculate the frequency of each name
for name in names:
if name not in freq:
freq[name] = 0
freq[name] += 1
# Find the name that appears only once
for name in names:
if freq[name] == 1:
return name
return None
```翻译:“参加城市跑步的人必须在开始和结束比赛时写下他们的名字。我们知道只有一个人没有完成比赛。这个 Python 函数试图找出那个人的名字,但它不起作用。修复它。”
在将其发送给 AI 之前,让我们先了解一下代码中的问题。
由于每个人在开始和结束比赛时都会写下自己的名字,因此此代码试图通过查找只出现一次的名字来解决问题。每个完成比赛的人都会写两次自己的名字,而没有完成比赛的人只会写一次。然而,此代码错误地假设所有名字都是不同的。
正确的答案不是频率等于 1 的名字,而是频率为奇数的名字。因此,解决方案是将第二个 for 循环检查 if freq[name] == 1: 替换为 if freq[name] % 2 == 1,以查找频率奇数的名称。
让我们看看这两个模型如何解决这个问题。我们提供了以下提示:
这是 V3 的响应:

V3 模型无法找到正确答案。它不仅通过引入两个输入列表来更改问题参数,而且即使我们有两个不同的列表,提供的解决方案也无法工作。
相比之下,R1 可以找到代码中的问题,即使它的解决方案更改了代码而不是修复提供的代码:
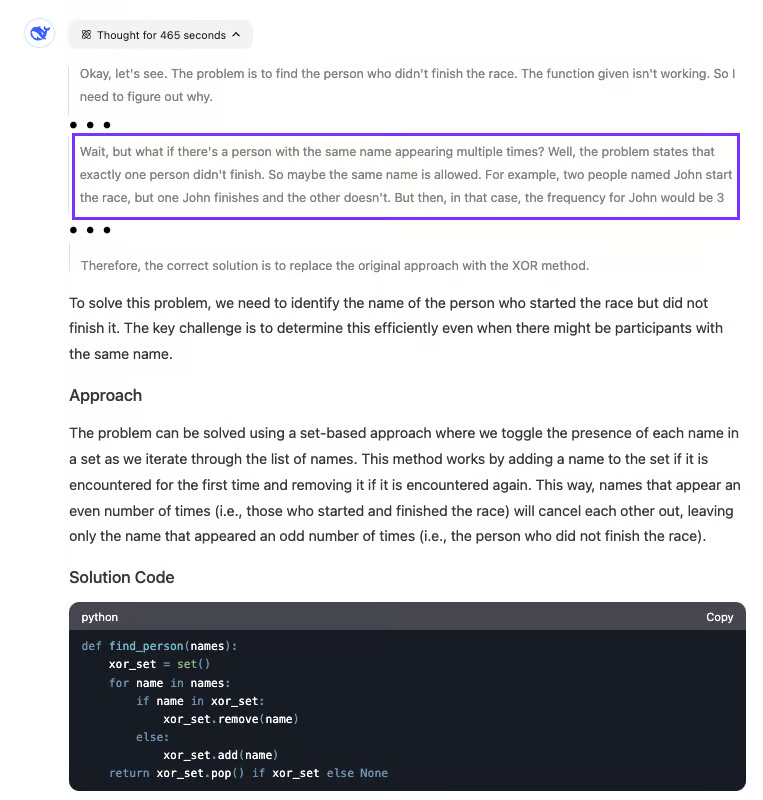
该模型在寻找答案时相当慢。我们看到它推理了将近八分钟。突出显示的部分显示了模型何时意识到代码出了什么问题。
4、何时选择 DeepSeek R1 或 V3
在 DeepSeek-R1 和 DeepSeek-V3 之间选择正确的模型取决于你希望通过我们的任务或项目实现什么目标。
对于大多数任务,我一般推荐的工作流程是使用 V3,如果陷入 V3 无法找到答案的循环,则切换到 R1。但是,此工作流程假设我们可以确定我们得到的答案是否正确。根据问题的不同,我们可能并不总是能够做出这种区分。
例如,在编写一个总结一些数据的简单脚本时,我们可以运行代码并查看它是否在执行我们想要的操作。但是,如果我们正在构建一个复杂的算法,验证代码是否正确就不那么简单了。
因此,在两种模型之间进行选择时,仍然需要一些指导方针。以下是何时选择其中一个的指南:
| 任务 | 模型 |
|---|---|
| 写作、内容创建、翻译 | V3 |
| 可以评估输出质量的任务 | V3 |
| 一般编码问题 | V3 |
| AI 助手 | V3 |
| 研究 | R1 |
| 复杂的数学、编码或逻辑问题 | R1 |
| 为解决单个问题而进行的长时间迭代对话 | R1 |
| 有兴趣了解得出答案的思维过程 | R1 |
5、结束语
DeepSeek V3 非常适合日常任务,如写作、内容创建和快速编码问题,以及构建 AI 助手,其中自然、流畅的对话是关键。它也非常适合可以快速评估输出质量的任务。
但是,对于需要深度推理的复杂挑战,例如研究、复杂的编码或数学问题,或扩展的解决问题对话,DeepSeek R1 是更好的选择。
原文链接:DeepSeek V3 vs R1: A Guide With Examples
汇智网翻译整理,转载请标明出处
