DeepSeek V3–0324
DeepSeek 回归并发布了 DeepSeek V3–0324,早期的Reddit和社交媒体评论称它是一个令人兴奋的模型,该模型的上下文长度大幅增加,并且在编码和数学任务上的表现看起来非常出色。

DeepSeek 回归并发布了 DeepSeek V3 的新版本,即 DeepSeek V3–0324,这是他们在2024年12月之后发布的第一个非推理型大语言模型。
出人意料的是,为了保持悬念,他们没有发布任何关于该模型的信息,只开放了模型权重。没有基准数据发布。因此,基于指标我们真的无法说什么,但
早期的Reddit和社交媒体评论称它是一个令人兴奋的模型。尽管DeepSeek提到这只是一个小更新,但实际上它远不止如此。该模型的上下文长度大幅增加,并且在编码和数学任务上的表现看起来非常出色。
DeepSeek V3–0324 vs. DeepSeek V3
1、编码与技术任务
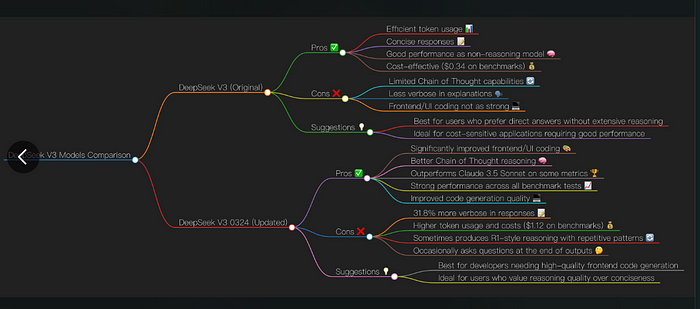
- DeepSeek V3–0324:在前端/UI开发方面表现出色,生成更干净、更高效且生产就绪的代码。在复杂前端逻辑处理上显著优于原始V3。
- 原始V3:在动态UI开发方面存在困难,但在基本脚本编写和后端逻辑方面表现良好。
2、推理与问题解决
- DeepSeek V3–0324:具备增强的链式思维(CoT)推理能力,能够进行逐步分解以进行调试、数学证明和结构化决策。
- 原始V3:更加直接但缺乏解释性——对于简单查询更快,但在多步推理方面较弱。
3、基准性能
- DeepSeek V3–0324:在代码生成、逻辑推理和准确性方面优于竞争对手如Claude 3.7 Sonnet。
- 原始V3:提供可靠但中等水平的结果,更适合通用任务。
4、令牌使用与响应风格
- 原始V3:高度令牌高效,产生简短直接的响应——非常适合成本效益高的聊天机器人和自动化。
- DeepSeek V3–0324:比原版多31.8%的冗长,通常会扩展解释并提供结构化的答案——更适合清晰表达,但也增加了令牌成本。
5、成本影响
- 原始V3:每项基准任务$0.34 → 最适合大规模、预算友好的部署。
- DeepSeek V3–0324:每项基准任务$1.12 → 对于需要调试、辅导和高级编码的高价值应用是合理的。
6、潜在缺点
- DeepSeek V3–0324:可能会过度解释或提出不必要的后续问题,可能减缓工作流程。
- 原始V3:可能会简化回答,缺乏在技术或分析查询中的深度。

{kind=link}
7、最佳用例与建议
✔ 何时选择 DeepSeek V3–0324
高级编码项目(React、Angular、复杂JavaScript)。
技术支持与辅导(需要详细解释)。
研究、数据分析和结构化推理任务。
当性能比成本更重要时。
✔ 何时坚持使用原始 DeepSeek V3
高容量、低成本自动化(例如客户服务机器人)。
快速的事实查询和摘要。
基本脚本编写和轻量级后端任务。
当简洁比深度更重要时。
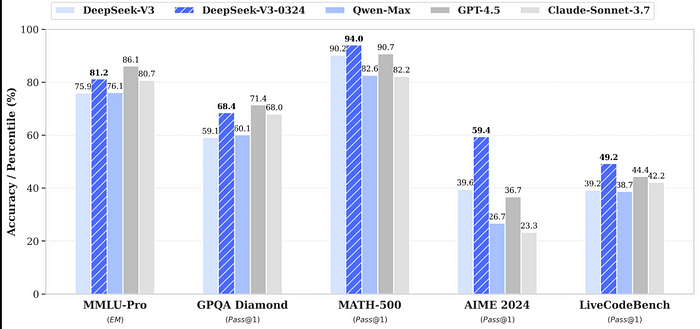
8、DeepSeek V3–0324 vs. Claude 3.7 Sonnet
一位用户刚刚发布了一些基准数据对比 DeepSeek V3–0324 和 Claude 3.7 Sonnet 的结果,该模型看起来轻松击败了Claude 3.7。

- DeepSeek V3–0324 是明确的赢家,在编码、逻辑和复杂问题解决方面表现出色。它是开发人员和技术用户的最佳选择。
- Claude 3.7仍然是一个可靠的通才,但在数学密集型和结构化推理任务中落后。
对于大多数用户来说,DeepSeek V3–0324 是更好的选择,特别是当需要编码或数值推理时。
9、结束语
DeepSeek V3–0324 是一个重大升级,在推理、编码和结构化问题解决方面表现出色,甚至在关键领域超过了Claude 3.7。虽然它更冗长且成本更高,但这种权衡对高级编码、调试和辅导是值得的。如果你需要效率和低成本自动化,原始的DeepSeek V3仍然是一个不错的选择。
原文链接:DeepSeek V3–0324 vs DeepSeek-V3
汇智网翻译整理,转载请标明出处
