在Cloud Run上部署Gemma 3
本指南将展示如何在Google Cloud Run上运行带有Gemma3模型的Ollama,利用GPU加速实现闪电般的推理速度

想要快速高效地部署强大的开源语言模型吗?本指南将展示如何在Google Cloud Run上运行带有Gemma3模型的Ollama,利用GPU加速实现闪电般的推理速度。我们将实现在不到20秒的时间内完成部署,并探索相关的成本问题,同时对Gemma3的性能进行基准测试。这是一份注重速度和易用性的实用指南。
Gemma3是Google令人兴奋的一系列开源权重生成式人工智能模型家族,为文本和多模态应用提供了令人印象深刻的能力。其主要特点包括:
- 多模态输入:能够处理图像和文本。
- 大上下文窗口:支持128K个标记,以提供更丰富、更有上下文意识的响应。
- 支持多种语言:超过140种语言。
- 不同大小的模型:提供1B、4B、12B和27B参数大小的模型,以适应不同的资源限制。
- 开源权重与商业用途:免费提供,并允许负责任的商业应用。
1、为什么选择Cloud Run?
Cloud Run是一个完全托管的无服务器平台,允许您在Google Cloud上运行无状态容器。它是部署Ollama的理想选择,原因如下:
- 快速部署:几秒钟内即可让您的模型上线。
- 自动扩展:轻松应对流量高峰。
- 按秒计费。
- GPU支持:通过强大的GPU加速推理。
2、在Cloud Run上使用GPU部署Ollama
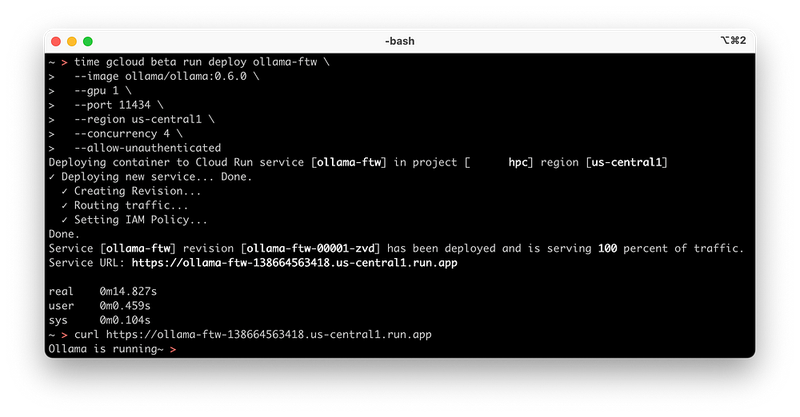
开头的截图展示了Ollama在不到二十秒内运行的情况,但那里的Cloud Run命令有些局限性。为了更稳健的部署,我们将执行以下操作:
gcloud beta run deploy ollama-ftw \
--image ollama/ollama:0.6.0 \
--gpu 1 \
--gpu-type nvidia-l4 \
--set-env-vars OLLAMA_KEEP_ALIVE=-1 \
--cpu 4 \
--memory 16Gi \
--concurrency 4 \
--max-instances 2 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--port 8080 \
--allow-unauthenticated \
--set-env-vars OLLAMA_HOST=0.0.0.0:8080 \
--add-volume name=models,type=cloud-storage,bucket=<MODEL BUCKET NAME> \
--add-volume-mount volume=models,mount-path=/root/.ollama \
--set-env-vars OLLAMA_MODELS=/root/.ollama/models \
--timeout 3600 \
--region us-central1
注意以下重要的标志在这个命令中:
--image ollama/ollama:0.6.0Cloud Run使用的容器镜像。--gpu 1 --gpu-type nvidia-l4暴露给Cloud Run服务的GPU数量和类型。--set-env-vars OLLAMA_KEEP_ALIVE=-1将模型无限期加载到vRAM中。这可以加快多次请求LLM时的响应时间。--cpu 4 --memory 16GiCloud Run服务的CPU和内存资源,使用GPU时这是最低要求(请注意分别推荐值为8和32Gi)。--concurrency 4 --set-env-vars OLLAMA_NUM_PARALLEL=4定义每个实例的最大并发请求数。Cloud Run服务和Ollama配置需要匹配这里。--max-instances 2最大实例数,当扩展时。--port 8080 set-env-vars --OLLAMA_HOST=0.0.0.0:8080定义Ollama容器绑定的端口。--allow-unauthenticated虽然不推荐,但这是一种快速将推理引擎暴露到互联网的方法。--add-volume name=models,type=cloud-storage,bucket=<MODEL BUCKET NAME> --add-volume-mount volume=models,mount-path=/root/.ollama set-env-vars OLLAMA_MODELS=/root/.ollama/models使用GCS Fuse集成在Cloud Run中并持久化存储模型的选项。确保使用与Cloud Run服务在同一区域可用的存储桶。--timeout 3600确保长时间响应(以及模型加载时间)不会成为问题,从默认的300秒延长。--region us-central1我们希望运行Cloud Run服务的区域,具体来说,在撰写本文时,只有四个区域可用: us-central1(爱荷华州)、asia-southeast1(新加坡)、europe-west1(比利时)和europe-west4(荷兰)。
Google还发布了一篇关于在Cloud Run上使用Gemma 3部署无服务器AI的官方论文。
重要注意事项:GCSFuse和内存限制
虽然上述设置速度快,但在使用GCSFuse处理大型模型时可能存在潜在问题。GCSFuse在将整个文件写入Cloud Storage之前会使用内存缓存。这可能导致在拉取像Gemma3 27B这样的大型模型时出现“设备上没有空间”错误,实际上是内存不足的问题。
{"error":"open /root/.ollama/blobs/sha256-123-partial-6: no space left on device"}
对于较大的模型(经验法则:任何大于容器总内存50%的模型),建议使用Filestore,并结合Direct VPC egress,以提高网络性能。
--add-volume=name=models,type=nfs,location=<Filestore-IP>:/models \
--add-volume-mount volume=models,mount-path=/root/.ollama \
--subnet us-central1 \
--vpc-egress=all
3、Cloud Run GPU定价
让我们来谈谈钱。us-central1区域中的Cloud Run服务,配备NVIDIA L4 GPU、4个vCPU和16GB内存的成本大约为:
- 每秒:$0.00029
- 每分钟:$0.017
- 每小时:$1.046
- 每月(730小时):$763.95
4、Gemma3在Cloud Run GPU上的性能🚀

由于内存限制,无法运行完整的Gemma3 27B模型。即使在4位量化的情况下,我们仍然需要大约21GB的内存。
time=2025-03-12T23:38:09.586Z level=INFO source=types.go:130 msg="inference compute" id=GPU-a7d5c53f-acd7-98c4-f088-29799fb0748d 库=cuda 变体=v12 计算=8.9 驱动程序=12.2 名称="NVIDIA L4" 总计="22.2 GiB" 可用="22.0 GiB"
使用12B参数模型,Q4_K_M量化(一种将模型权重压缩到每参数4位的技术以减少内存使用并提高速度),在上述配置下,使用Ollama 0.6.0,我们在回答学术问题“为什么天空是蓝色的?”时达到了平均每秒25.23个token的速度。这相当于每个token的成本约为$0.0000115。老实说,还不错。我计划探索vLLM,看看是否可以进一步提高推理速度并降低成本。
5、其他Cloud Run的好处
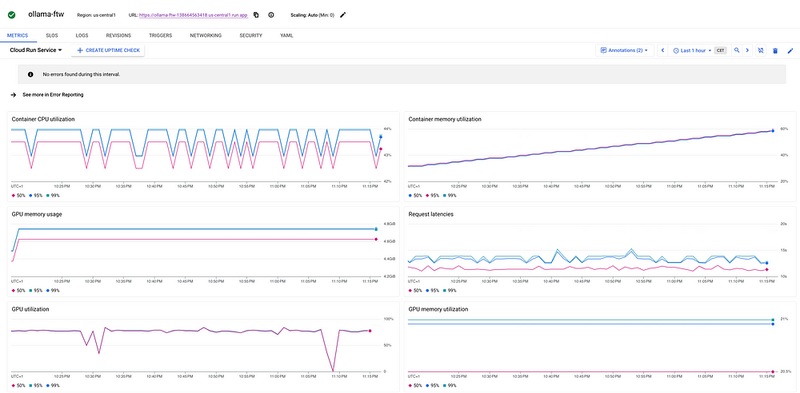
除了速度之外,Cloud Run还提供了内置的指标和日志记录功能,便于监控和调试。您可以直接从Cloud控制台跟踪CPU利用率、内存使用情况、请求延迟和错误率。
6、结束语
总之,这项工作突显了Cloud Run作为不仅仅是一个部署平台的变革潜力;它是一个加速开放源代码AI普及的推动者。能够在不到20秒的时间内启动带有GPU加速的Ollama不仅是一个速度基准;它是AI开发范式的转变。想象一下可能的应用场景:能够快速部署具有细腻多语言理解能力的Gemma3驱动的聊天机器人,实时分析图像和文本的快速原型多模态应用程序,或者能够根据需求以无服务器效率扩展的AI驱动服务。
Gemma3的开源特性,加上Cloud Run的可访问性,使开发人员能够构建创新且负责任的AI解决方案,摆脱专有生态系统带来的限制。这种组合开启了这样一个未来:复杂的AI不再是大型公司的专属领域,而是同样易于初创公司、研究人员和个人开发者的获取。
虽然对内存管理的考虑,尤其是对于最大的Gemma3模型,仍然很重要,但这也推动了优化技术和模型选择的创新。这不是障碍,而是一个探索高效量化、模型蒸馏以及战略性使用Gemma3的不同大小以满足特定应用需求的邀请。
最终,我们展示的速度和简便性不仅仅是技术优势;它们是创新的催化剂,邀请您探索在无服务器云与开源AI模型(如Gemma3)交叉点上等待的巨大而令人兴奋的潜力。
原文链接:Ollama on Cloud Run with GPU in less than 20 seconds!
汇智网翻译整理,转载请标明出处
