视觉语言模型AWS部署指南
本文介绍如何使用Qwen-2.5-VL、vLLM和AWS Batch构建处理数百万份文档的文档解析管道。

简要说明:我们部署了一个AI功能,用于从文档(如发票、报告)中提取结构化数据,使用的是 Qwen-2.5-VL 和 vLLM —— 无需训练或数据收集即可完成。解决方案通过 Docker 和 uv 进行容器化,然后作为* 批推理 管道在* AWS Batch 上部署,并使用 Terraform。令人惊讶的是,我们的内部方法比第三方LLM提供商更便宜,即使没有进行基本优化。*
如今,大多数公司开发其AI功能时都依赖外部LLM提供商。
OpenAI与GPT,Google与Gemini,Anthropic与Claude。一次API调用。就是这样,您的应用程序就具备了AI功能!
然而,这种开发的便利性也伴随着代价,大多数已经进入POC阶段的公司并不愿意支付这个代价……
- 数据安全: 你的数据就是他们的数据。用于训练下一代LLM版本,或者对你使用情况进行神秘分析。
- 成本: 当使用API端点上的LLMs时,您按token付费。这意味着成本呈线性增长:调用越多,费用越高。虽然价格看似对简单的POCs很低,但它可以迅速失控。
- 可靠性: 你无法控制LLM的正常运行时间和停机时间。服务器因高需求而失败?那就意味着您的所有功能(或应用程序)都会关闭。祝您好运发送支持票。
- 性能: 预测准确性取决于模型的大小和提示的质量。但说实话:无论您如何提示/恳求LLM,它只是在训练期间没有看到足够的您的数据,因此在您的任务上表现得不够好……
- 可维护性: 今天一切正常。您的提示设置好了。第二天,什么也不起作用了。您需要重新校准一切。再次。直到下一天。
然而,随着开源社区的最新发展,任何人都可以构建一个完整的内部LLM功能并解决所有这些问题。
为了展示如何做到这一点,我们选择了我在机器学习工程师职业生涯中经常遇到的一个常见问题:从文档中提取数据。
在这篇文章中,您将学习如何在AWS Batch上部署开源视觉语言模型,Qwen-2.5-VL。
系好安全带!读完这篇文章后,你将再也不考虑OpenAI来开发您的AI功能了。
1、功能组件
1.1 解析文档:视觉语言模型的工作!
视觉语言模型(VLM)是一种Transformer架构的类别,经过文本和图像的联合训练。指令和图像分别嵌入,然后在模型前向路径中合并。
这开启了多种可能性,例如图像和视频识别结合用户指令。
我们的任务是从模型生成中提取结构化文档数据。
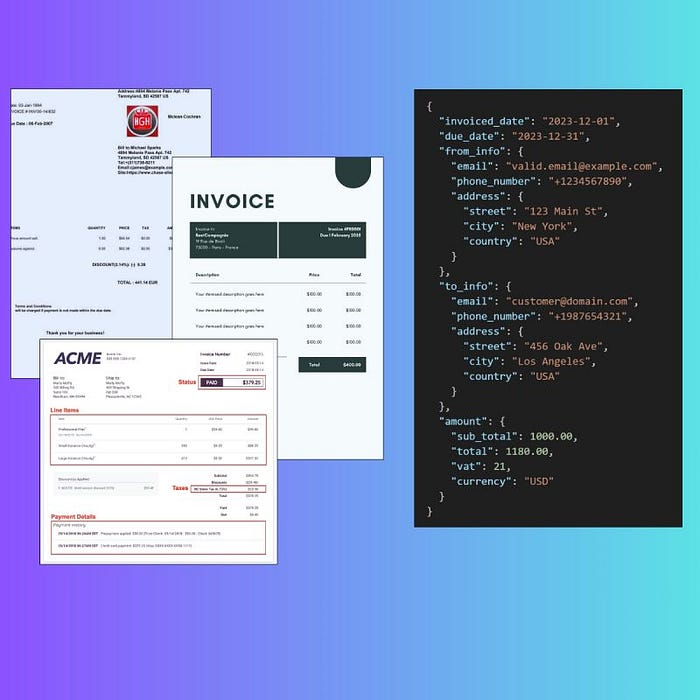
我们有几个候选模型来完成这项任务:
- Qwen-2.5-VL
由阿里巴巴开发的模型,是开源模型中最强大的之一。VL版本提供了许多功能,如图像理解、长视频处理、对象识别和结构化输出。
从3亿到720亿参数的模型集合,可在Hugging Face平台上获得。
- SmolVLM
由Hugging Face开发的开源模型。它是所有VLM中最轻量级的,仅包含2.56亿参数!该架构由SigLip组成编码器部分和SmolLM2组成解码器部分。
该模型在图像理解、代数推理、表格理解等方面进行了训练。了解更多关于SmolVLM的信息,请访问其官方Hugging Face模型页面。
- Idefics3
来自Hugging Face的另一个模型。
Idefics3是SigLip和Llama-3.1的融合。它在开放数据集上关于图像理解和问答指令进行了训练。
由于Qwen-2.5-VL已经经过微调以返回结构化输出,因此它是解析文档的理想候选模型。
1.2 vLLM为VLM提供服务
vLLM 是一种LLM服务工具,极大地加速了LLM推理。它利用了PagedAttention机制,该机制在内存中最佳分配KV缓存,以同时处理多个LLM请求。
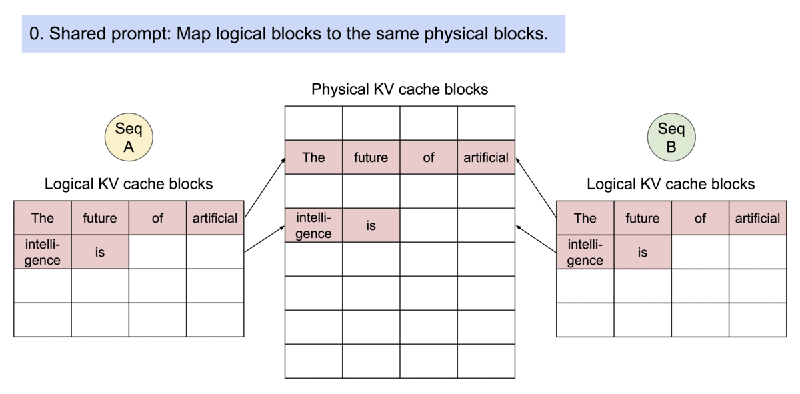
vLLM不仅支持仅文本模型,还支持视觉语言模型,并且支持结构化输出生成,这使其成为完美的选择。
最好的部分是:它直接集成在Transformers库中。这允许我们加载任何来自Hugging Face平台的模型,vLLM会自动将模型权重分配到GPU VRAM中。
我们可以使用vLLM进行两种部署配置:在线推理和离线推理。
在这篇文章中,我们将只关注离线推理。我们将创建一个使用vLLM的Python模块,并将图像处理成JSON等结构化输出。
1.3 AWS Batch运行推理
我们将开发的功能将作为一个ETL(提取-转换-加载)管道中的步骤。定期,比如说每天一次,模型将从数千个图像中提取数据,直到完成。
这是批量部署的最佳用例。
我们将使用AWS Batch来管理云中的批量作业。
它由以下部分组成:
- 作业
最小的实体。基于Docker容器,一个作业运行模块直到完成或失败。
与服务相比,这是一种成本效益高的解决方案,适用于时间限制的任务。
- 作业定义
作业模板。它定义了为任务分配的资源、Docker镜像的位置、重试次数、优先级和最大时间。
一旦定义,您可以根据需要创建和运行任意数量的作业。
- 作业队列
负责根据资源可用性和作业优先级协调和优先级排序作业。
您可以为高优先级任务创建多个队列,例如对时间敏感的任务,或者低优先级任务,可以在最便宜的资源上运行。
计算环境通过作业队列自动为每个队列分配适当的资源。
- 计算环境
它定义了您准备为所有作业队列分配的资源。例如,GPU用于重型计算任务,如LLM训练,或Spot实例用于容错任务。
作业队列根据作业定义的要求自动分配适当的资源。
AWS Batch是AWS的一项强大服务,可用于运行任何类型的作业,使用任何EC2资源:CPU和GPU实例。您只需为运行时间付费。一旦作业完成,AWS Batch会自动关闭所有内容。这使它成为我们用例的理想选择。
2、开始构建我们的文档解析功能
VLM部署将如下所示:
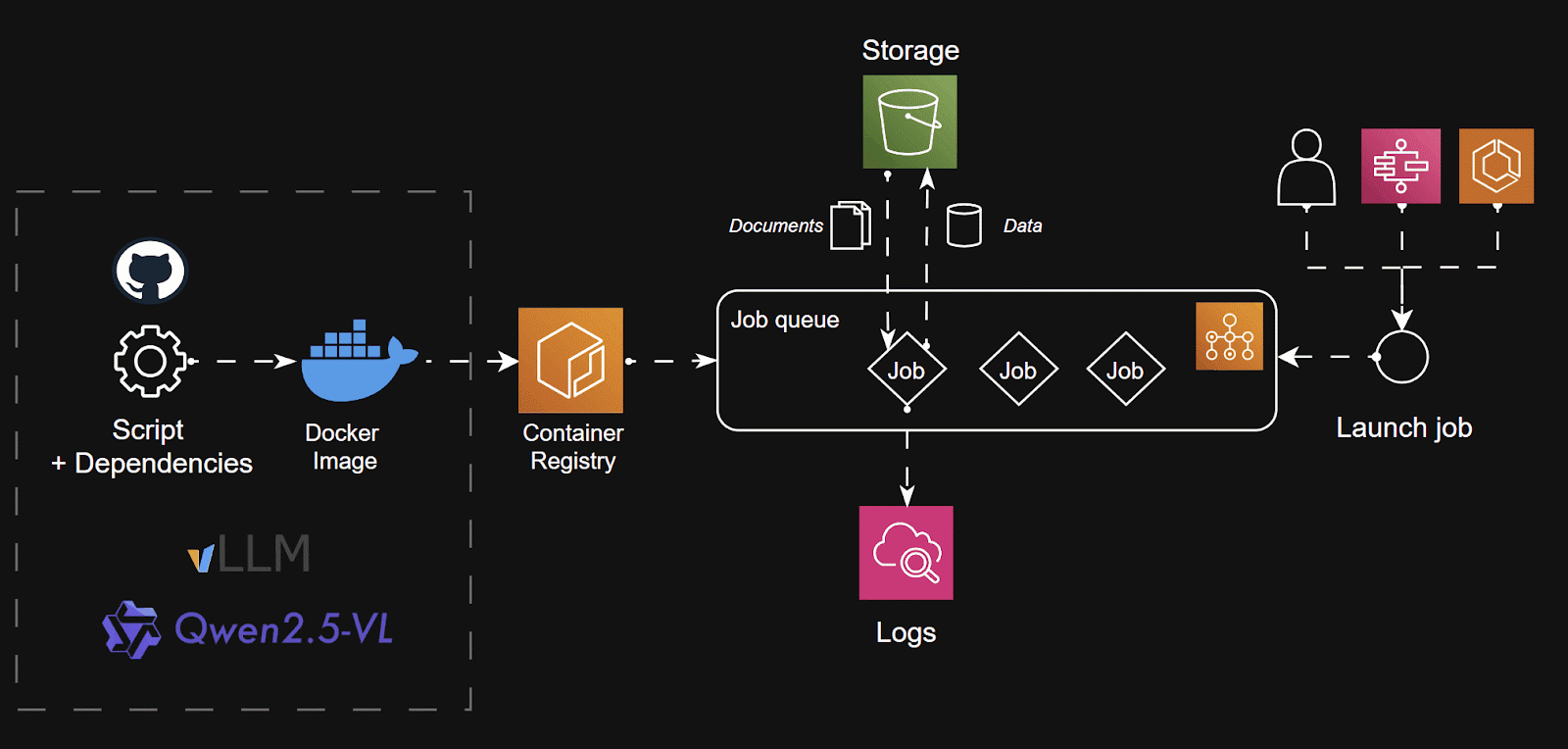
- 因为其能够直接生成结构化输出的能力,我们将使用Qwen-2.5-VL来执行从文档中提取数据。
- 为了加速推理,我们使用vLLM来自动管理大批量推理。实际上,vLLM使用PagedAttention机制自动处理来自指令和嵌入图像的大批量tokens。
- 包含vLLM离线推理的脚本和模块将使用uv打包并使用Docker容器化。这使得模块几乎可以在任何地方部署:AWS Batch / GCP Batch / Kubernetes。
- Docker镜像将存储在AWS ECR中,以保持功能在AWS生态系统中。
- 我们将使用AWS Batch来管理作业队列。我们将使用EC2而不是Fargate来编排实例。原因是Fargate不提供GPU资源,这对于运行LLMs至关重要。基础设施将使用Terraform管理和部署。
- 我们将使用AWS S3作为存储解决方案,下载文档并上传提取的数据作为数据集。数据随后可用于任何ETL管道,例如为分析仪表板提供数据。
让我们开始吧!
2.1 作业模块
我们首先编写作业脚本。
流程如下:
文档存储在S3桶中作为图像,使用AWS SDK下载。我们还通过唯一的S3路径标识每个文档,这将帮助我们将其提取的数据与其对应的数据输出关联起来。我已将提供的文本翻译成中文,并保持了Markdown格式。以下是翻译后的文本:
我有文档。
#llm/parser/main.py
from io import BytesIO
from PIL import Image
import logging
import boto3
from botocore.exceptions import ClientError
LOGGER = logging.getLogger(__name__)
def load_images(
s3_bucket: str,
s3_images_folder_uri: str,
) -> tuple[list[str], list[Image.Image]]:
try:
s3 = boto3.client("s3")
response = s3.list_objects_v2(Bucket=s3_bucket, Prefix=s3_images_folder_uri)
images: list[Image.Image] = []
filenames: list[str] = []
for obj in response["Contents"]:
key = obj["Key"]
filenames.append(key)
response = s3.get_object(Bucket=s3_bucket, Key=key)
image_data = response["Body"].read()
images.append(Image.open(BytesIO(image_data)))
return filenames, images
except ClientError as e:
LOGGER.error("Issue when loading images from s3: %s.", str(e))
raise
except Exception as e:
LOGGER.error("Something went wrong when loading the images from AWS S3: %s", e)
raise我们使用vLLM从Hugging Face平台加载模型并为其准备GPU。
它还带有有用的特性,例如可以在SamplingParams参数中设置的指导解码。
在后端,vLLM使用xGrammar机制将文本生成输出导向为有效的JSON格式。
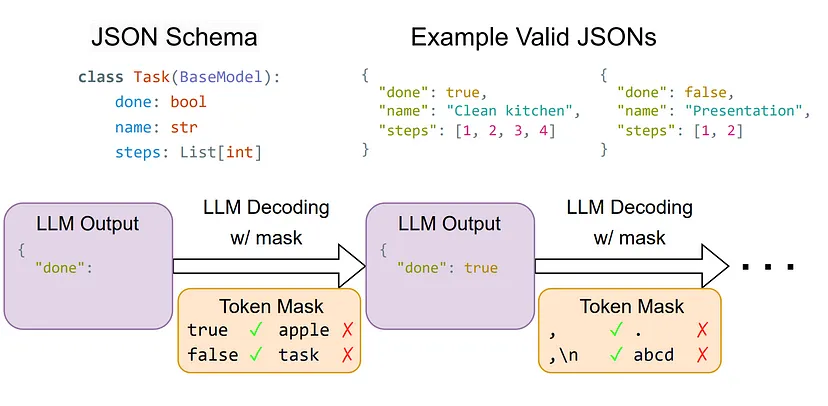
通过提供预期输出的Pydantic模式,我们可以引导生成进入正确的数据格式。
#llm/parser/schemas.py
import re
from pydantic import BaseModel, field_validator, ValidationInfo
class Address(BaseModel):
street: str | None = None
city: str | None = None
country: str | None = None
class Info(BaseModel):
email: str | None = None
phone_number: str | None = None
address: Address
class Amount(BaseModel):
sub_total: float | None = None
total: float | None = None
vat: float | None = None
currency: str | None = None
class Invoice(BaseModel):
invoiced_date: str | None = None
due_date: str | None = None
from_info: Info
to_info: Info
amount: Amount一旦模型和图像被加载到内存中,我们就可以使用vLLM运行推理。
由于我们使用的是指导解码而不是普通的推理,这个过程会花费更多的时间以换取更好的数据质量。
为了辅助文本生成,我们还提供了一个指令,引导LLM返回有效的模式。我们需要将该指令适配到Qwen-2.5-VL微调期间使用的提示模板中。
#llm/parser/prompts.py
INSTRUCTION = """
Extract the data from this invoice.
Return your response as a valid JSON object.
Here's an example of the expected JSON output:
{
"invoiced_date": 09/04/2025 # format DD/MM/YYYY
"due_date": 09/04/2025 # format DD/MM/YYYY
"from_info": {
"email": "jeremya@gmail.com",
"phone_number": "+33645789564",
"address": {
"street": "Chemin des boulangers",
"city": "Bourges",
"country": FR # 2 letters country
},
"to_info": {
"email": "igordosgor@gmail.com",
"phone_number": "+33645789564",
"address": {
"street": "Chemin des boulangers",
"city": "New York",
"country": US
},
}
"amount": {
"sub_total": 1450.4 # Before taxes
"total": 1740.48 # After taxes
"vat": 0.2 # Pourcentage
"currency": USD # 3 letters code (USD, EUR, ...)
}
}
""".strip()
QWEN_25_VL_INSTRUCT_PROMPT = (
"<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n"
"<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>"
"{instruction}<|im_end|>\n"
"<|im_start|>assistant\n"
)
#llm/parser/main.py
from PIL import Image
from vllm import LLM, SamplingParams
from llm.parser import prompts
def run_inference(
model: LLM, sampling_params: SamplingParams, images: list[Image.Image], prompt: str
) -> list[str]:
"""Generate text output for each image"""
inputs = [
{
"prompt": prompt,
"multi_modal_data": {"image": image},
}
for image in images
]
outputs = model.generate(inputs, sampling_params=sampling_params)
return [output.outputs[0].text for output in outputs]
if __name__ == "__main__":
outputs = run_inference(
model=model,
sampling_params=sampling_params,
images=images,
prompt=prompts.QWEN_25_VL_INSTRUCT_PROMPT.format(
instruction=prompts.INSTRUCTION
),
)我们还使用 Pydantic 验证了返回的 JSON。
Pydantic 的使用非常方便,因为它允许模块返回有效的模式,无论其生成方式如何。LLM 容易产生“幻觉”,这在生产应用程序中可能会非常严重。
然而,Pydantic 并没有提供开箱即用的“如果无效则返回默认值”功能。
为此,我们将使用 @field_validator 装饰器创建自己的验证。查看文档以了解更多关于该功能的信息。
class Info(BaseModel):
email: str | None = None
phone_number: str | None = None
address: Address
@field_validator("email", mode="before")
@classmethod
def validate_email(cls, email: str | None, info: ValidationInfo) -> str | None:
if not email:
return None
email_pattern = r"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$"
if not re.match(email_pattern, email):
return cls.model_fields[info.field_name].get_default()
else:
return email最后,数据被转换为数据集,每个元素都有唯一的标识符(我们选择了每个文档的 S3 路径)。
我们使用 uv 来管理 Python 依赖项并打包我们的应用程序。此外,我们使用 Pyproject.toml 文件,添加了 cli 命令 run-batch-job 来运行作业脚本。
#pyproject.toml
[project.scripts]
run-batch-job = "llm.__main__:main"包构建完成后,我们只需运行:
uv run run-batch-job关于应用程序的设置,例如 S3 存储桶名称和 S3 前缀,我们使用 pydantic-settings ,而不是基本的 Python 类。原因是 Pydantic 除了验证环境变量外,还会自动验证作业配置。
from typing import Annotated
from pydantic_settings import BaseSettings, SettingsConfigDict
from pydantic import Field
class Settings(BaseSettings):
model_config = SettingsConfigDict(
env_file=".env", extra="ignore"
) # extra="ignore" for AWS credentials
# Model config
model_name: str = "Qwen/Qwen2.5-VL-3B-Instruct"
gpu_memory_utilisation: Annotated[float, Field(gt=0, le=1)] = 0.9
max_num_seqs: Annotated[int, Field(gt=0)] = 2
max_model_len: Annotated[int, Field(multiple_of=8)] = 4096
max_tokens: Annotated[int, Field(multiple_of=8)] = 2048
temperature: Annotated[float, Field(ge=0, le=1)] = 0
# AWS S3
s3_bucket: str
s3_preprocessed_images_dir_prefix: str
s3_processed_dataset_prefix: str
settings = Settings()S3 设置在运行时执行,这意味着我们无需重新构建包即可修改设置!
2.2 使用 Docker 将模块容器化
我们使用 uv 文档中的官方多阶段构建方法。
(由于使用了 Pytorch 和 Cuda 库,Docker 镜像大小约为 9GB!)
# An example using multi-stage image builds to create a final image without uv.
# First, build the application in the `/app` directory.
# See `Dockerfile` for details.
FROM ghcr.io/astral-sh/uv:python3.12-bookworm-slim AS builder
ENV UV_COMPILE_BYTECODE=1 UV_LINK_MODE=copy
# Disable Python downloads, because we want to use the system interpreter
# across both images. If using a managed Python version, it needs to be
# copied from the build image into the final image; see `standalone.Dockerfile`
# for an example.
ENV UV_PYTHON_DOWNLOADS=0
WORKDIR /app
RUN --mount=type=cache,target=/root/.cache/uv \
--mount=type=bind,source=uv.lock,target=uv.lock \
--mount=type=bind,source=pyproject.toml,target=pyproject.toml \
uv sync --frozen --no-install-project --no-dev
ADD . /app
RUN --mount=type=cache,target=/root/.cache/uv \
uv sync --frozen --no-dev
# Then, use a final image without uv
FROM python:3.12-slim-bookworm
# Copy the application from the builder
COPY --from=builder --chown=app:app /app /app
# vLLM requires some basic compilation tools
RUN apt-get update && apt-get install -y build-essential
# Place executables in the environment at the front of the path
ENV PATH="/app/.venv/bin:$PATH"
# Executable package. Check pyproject.toml
CMD ["run-batch-job"]构建完成后,我们会将 Docker 镜像上传到 ECR。我们将逻辑直接实现到 Makefile 中,以便轻松运行命令。这也有助于记录项目。
AWS_REGION ?= eu-central-1
ECR_REPO_NAME ?= demo-invoice-structured-outputs
ECR_URI = ${ECR_ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/${ECR_REPO_NAME}
.PHONY: deploy
deploy: ecr-login build tag push
# Require ECR_ACCOUNT_ID (fail if not provided)
ifndef ECR_ACCOUNT_ID
$(error ECR_ACCOUNT_ID is not set. Please provide it, e.g., `make deploy ECR_ACCOUNT_ID=123456789012`)
endif
ecr-login:
@echo "[INFO] Logging in to ECR..."
aws ecr get-login-password --region ${AWS_REGION} | docker login --username AWS --password-stdin ${ECR_URI}
@echo "[INFO] ECR login successful"
build:
@echo "[INFO] Building Docker image..."
docker build -t ${ECR_REPO_NAME} .
@echo "[INFO] Build completed"
tag:
@echo "[INFO] Tagging image for ECR..."
docker tag ${ECR_REPO_NAME}:latest ${ECR_URI}:latest
@echo "[INFO] Tagging completed"
push:
@echo "[INFO] Pushing image to ECR..."
docker push ${ECR_URI}:latest
@echo "[INFO] Push completed"你可以运行这个命令:
make deploy ECR_ACCOUNT_ID=<YOUR_ECR_ACCOUNT_ID>2.3 使用 EC2 编排部署 AWS Batch
AWS Batch 提出了三种使用 AWS 资源执行作业的主要方法:EC2、Fargate 或 EKS。由于 Fargate 不允许使用 GPU,而 EKS 需要现有集群运行,因此我们选择 EC2 编排。
我们将解释如何使用 Terraform(一种基础设施即代码工具)进行部署。
- IAM 角色
首先是 IAM 权限和角色。
在 AWS 中,角色使 AWS 服务能够与其他服务交互。AWS Batch 需要 4 个角色:
- EC2 实例角色
AWS Batch 实际上在后台使用 ECS 来启动和运行 EC2 实例。因此,我们需要创建一个策略来访问 EC2 服务,并将此角色分配给一个 ECS 角色,该角色将分配给 AWS Batch 计算环境。
我知道,既然可以复杂化,何必简化呢?
# IAM Policy Document
data "aws_iam_policy_document" "ec2_assume_role" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["ec2.amazonaws.com"]
}
actions = ["sts:AssumeRole"]
}
}
# IAM Role Creation
resource "aws_iam_role" "ecs_instance_role" {
name = "ecs_instance_role"
assume_role_policy = data.aws_iam_policy_document.ec2_assume_role.json
}
# Policy Attachment
resource "aws_iam_role_policy_attachment" "ecs_instance_role" {
role = aws_iam_role.ecs_instance_role.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonEC2ContainerServiceforEC2Role"
}
# Instance Profile Creation. Used in Batch-Compute-Env
resource "aws_iam_instance_profile" "ecs_instance_role" {
name = "ecs_instance_role"
role = aws_iam_role.ecs_instance_role.name
}- AWS Batch 服务角色
AWS Batch 服务角色策略,允许访问相关服务,包括 EC2、自动扩展、EC2 容器服务、Cloudwatch 日志、ECS 和 IAM。
它是 AWS Batch 的骨干,将服务连接到所有其他 AWS 服务。
data "aws_iam_policy_document" "batch_assume_role" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["batch.amazonaws.com"]
}
actions = ["sts:AssumeRole"]
}
}
resource "aws_iam_role" "batch_service_role" {
name = "aws_batch_service_role"
assume_role_policy = data.aws_iam_policy_document.batch_assume_role.json
}
resource "aws_iam_role_policy_attachment" "batch_service_role" {
role = aws_iam_role.batch_service_role.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSBatchServiceRole"
}- ECS 任务执行角色
由于 AWS Batch 在 ECS 集群中运行,因此它需要访问 ECS 执行角色才能访问服务,例如从 ECR 私有存储库中提取容器。
resource "aws_iam_role" "ecs_task_execution_role" {
name = "ecs_task_execution_role"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [{
Effect = "Allow",
Principal = { Service = "ecs-tasks.amazonaws.com" },
Action = "sts:AssumeRole"
}]
})
}
# Attach the standard ECS Task Execution policy
resource "aws_iam_role_policy_attachment" "ecs_task_execution_role" {
role = aws_iam_role.ecs_task_execution_role.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy"
}- 批量作业角色
最后,如果您需要作业调用外部 AWS 服务(在本例中为 S3),我们需要为正在运行的容器指定一个角色。这是一种比使用环境变量更好、更安全的处理 AWS 凭证的方式。
我们还将 ecs-task-execution 角色附加到此角色,因为它由 ECS 作为任务进行管理。
最后,我们将权限限制在存储桶内。这符合最小权限原则。
resource "aws_iam_role" "batch_job_role" {
name = "demo-batch-job-role"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [{
Effect = "Allow",
Principal = { Service = "ecs-tasks.amazonaws.com" },
Action = "sts:AssumeRole"
}]
})
}
# IAM Policy for S3 Access
resource "aws_iam_policy" "batch_s3_policy" {
name = "batch-s3-access"
description = "Allow Batch jobs to access S3 buckets"
policy = jsonencode({
Version = "2012-10-17",
Statement = [{
Effect = "Allow",
Action = [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
Resource = [
"arn:aws:s3:::${var.s3_bucket}",
"arn:aws:s3:::${var.s3_bucket}/*"
]
}]
})
}2.4 计算环境
AWS Batch 使用计算环境从 AWS(EC2 或 Fargate)启动资源。
它还支持竞价型实例,这些实例比按需资源成本更低,但存在提前终止的风险。对于批处理作业来说,这是一个理想的用例,因为失败的作业可以轻松重试。
resource "aws_batch_compute_environment" "batch_compute_env" {
compute_environment_name = "demo-compute-environment"
type = "MANAGED"
service_role = aws_iam_role.batch_service_role.arn # Role associated with Batch
compute_resources {
type = "EC2"
allocation_strategy = "BEST_FIT_PROGRESSIVE"
instance_type = var.instance_type
min_vcpus = var.min_vcpus
desired_vcpus = var.desired_vcpus
max_vcpus = var.max_vcpus
security_group_ids = [aws_security_group.batch_sg.id]
subnets = data.aws_subnets.default.ids
instance_role = aws_iam_instance_profile.ecs_instance_role.arn # Role to roll up EC2 instances
}
depends_on = [aws_iam_role_policy_attachment.batch_service_role] # To prevent a race condition during environment deletion
}批处理计算环境会自动将作业分配给 VPC 内的资源。在本例中,我们使用了 AWS 的默认 VPC。
查看代码,了解用于创建 VPC/子网/安全组的 Terraform 部分。
我们将使用 EC2 实例 g6.xlarge,其中包含一个 Nvidia L4 处理器,配备 16GB CPU RAM 和约 24GB VRAM。
重要信息:
一个 g6.xlarge 实例由 4 个 vCPU 组成,这意味着如果我们想同时运行 2 个作业,我们需要指定最多 8 个 vCPU。
如果 desired_vcpus 的数量为 0,AWS Batch 将自动启用作业所需的实例数量。AWS Batch 会根据作业队列需求在最小值和最大值之间调整此值。
请确保 vCPU 和 GPU 实例的配额充足。请检查您的服务配额并向 AWS 发出请求。 (这给我带来了一些麻烦,因为我没有足够的 g6.xlarge 实例配额。不要犯同样的错误!)
2.5 作业队列
作业队列按优先级调度和管理作业。创建后,我们会分配一个计算环境。
resource "aws_batch_job_queue" "batch_job_queue" {
name = "demo-job-queue"
state = "ENABLED"
priority = 1
compute_environment_order {
order = 1
compute_environment = aws_batch_compute_environment.batch_compute_env.arn
}
}您可以创建多个具有不同优先级的作业队列,并根据其优先级组织作业。
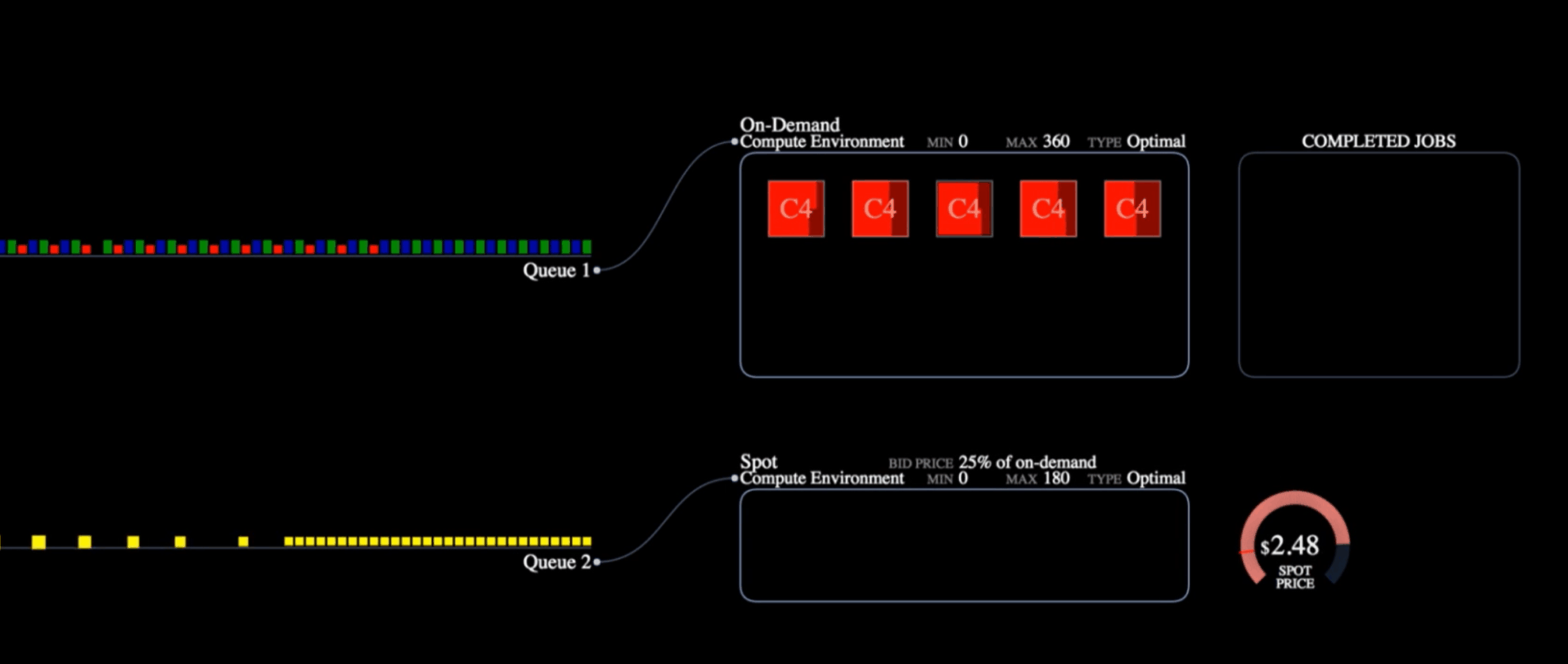
2.6 作业定义
最后是作业定义。这是创建作业的模板。它指定了优先级、Docker 镜像的提取位置、环境变量等等……
它还指定了作业所需的资源。如果计算环境中有可用资源(例如,尚未被其他作业队列使用),则可以启动作业。由于我们在 GPU 上运行推理,因此我们需要指定正确的 vCPU 数量、最大 CPU 内存(g6.xlarge 总共有 16GB)以及 GPU 数量(此处为 1)。
esource "aws_batch_job_definition" "batch_job_definition" {
name = "demo-job-definition"
type = "container"
container_properties = jsonencode({
image = var.docker_image,
jobRoleArn = aws_iam_role.batch_job_role.arn,
executionRoleArn = aws_iam_role.ecs_task_execution_role.arn,
resourceRequirements = [
{
type = "VCPU"
value = "4" # g6.xlarge has 4 vCPUs
},
{
type = "MEMORY"
value = "8000" # g6.xlarge has 16GB RAM
},
{
type = "GPU"
value = "1" # Critical for g6.xlarge
}
],
environment = [
{
name = "S3_BUCKET",
value = var.s3_bucket
},
{
name = "S3_PREPROCESSED_IMAGES_DIR_PREFIX",
value = var.preprocessed_images_dir_prefix
},
{
name = "S3_PROCESSED_DATASET_PREFIX",
value = var.s3_processed_dataset_prefix
}
]
})
}现在你已经准备好了!运行并部署你的基础设施:
terraform init
terraform applyAWS Batch基础设施将准备好处理存储在S3桶中的文档。
aws batch submit-job \
--job-name <YOUR-JOB-NAME> \
--job-queue demo-job-queue \
--job-definition demo-job-definition3、成本如何?
在内部部署你的LLM功能的最大优势是隐私性和可靠性。但成本真的那么低吗?
答案是:是的!
我们使用了10份文件进行了实验。平均而言,每份文件的处理时间为4.5秒,使用的是vLLM和Qwen-2.5-VL-3B模型。一台EC2 g6.xlarge实例的成本今天为 $0.8048。
对于10,000份处理过的文档,这代表的成本约为 ~$10,所需时间约为 ~12.5小时。
我们将我们的解决方案与现有的VLMs(如GPT-4.1、Gemini-2.5-Flash或Claude 3.7)的成本进行了比较。
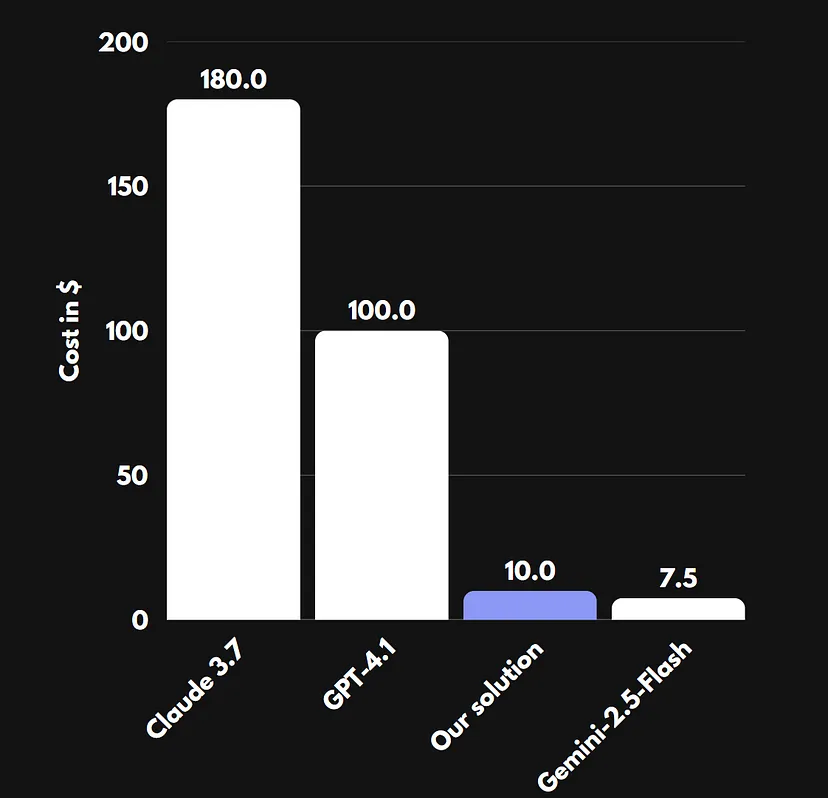
这使得我们的解决方案不仅完全安全,而且在成本效益方面也是最佳选择之一。
使用开源模型打开了微调的大门,这比任何通用LLM都能更大幅度地提高性能。
3、结束语
在这篇文章中,我们介绍了部署AI功能以解析发票或报告等文档的过程。我们使用了Qwen-2.5-VL结合vLLM直接从图像预测结构化输出。无需任何训练或数据收集!
该功能通过Docker和uv容器化后,在AWS Batch上部署用于批量推理,并通过Terraform展示了如何使用EC2编排来利用GPU。
此外,我们发现开发自己的功能在现有LLM提供商中是最便宜的解决方案。即使没有进行任何推理或部署优化,例如量化或利用更好的资源(Spot实例或更强大的GPU实例)。
汇智网翻译整理,转载请标明出处
