Triton推理服务器YOLO部署教程
Triton Inference Server 由 NVIDIA 开发,是一个开源平台,旨在简化生产中 AI 和深度学习模型的部署、扩展和优化。

triton Inference Server 由 NVIDIA 开发,是一个开源平台,旨在简化生产中 AI 和深度学习模型的部署、扩展和优化。
1、 转换yolo模型
要在 Triton Inference Server 上部署我们的 YOLO 模型 (best.pt),第一步是将其转换为 Triton 支持的格式。我们将重点介绍将其转换为 ONNX 或 TensorRT,因为 Triton 可以无缝地与这些格式配合使用以优化推理。
注意:YOLO 模型必须先转换为 ONNX 格式,然后才能转换为 TensorRT。
from ultralytics import YOLO
model = YOLO("model.pt")
onnx_file = model.export(format="onnx", dynamic=True)我们稍后将讨论为什么 TensorRT 是本例中的首选。
2、模型存储库
第一步是设置存储库, model_repository 是 Triton 读取模型以及与每个模型相关的元数据(配置、版本文件等)的方式。这些模型存储库可以位于本地或网络附加文件系统中,也可以位于 AWS S3、Azure Blob Storage 或 Google Cloud Storage 等云对象存储中。
model_repository/
├── model1
│ ├── 1
│ │ └── model.plan
│ └── config.pbtxt
└── model2
├── 1
│ └── model.plan
└── config.pbtxt3、模型配置
接下来我们需要查看的是 config.pbtxt 模型配置文件:
name: "rock_detection"
platform: "tensorrt_plan"
version_policy {
latest {
num_versions: 1
}
}
max_batch_size: 8
input {
name: "images"
data_type: TYPE_FP32
dims: 3
dims: 640
dims: 640
}
output {
name: "output0"
data_type: TYPE_FP32
dims: 5
dims: 8400
}
instance_group {
count: 1
kind: KIND_GPU
}
default_model_filename: "model.plan"
dynamic_batching {
preferred_batch_size: 1
preferred_batch_size: 2
preferred_batch_size: 4
preferred_batch_size: 8
max_queue_delay_microseconds: 500
}
optimization {
input_pinned_memory {
enable: true
}
output_pinned_memory {
enable: true
}
}
backend: "tensorrt"
- name: "name" is an optional field, the value of which should match the name of the directory of the model.
- backend: This field indicates which backend is being used to run the model. Triton supports a wide variety of backends like TensorFlow, PyTorch, Python, ONNX and more..
- max_batch_size: As the name implies, this field defines the maximum batch size that the model can support.
- input and output: The input and output sections specify the name, shape, datatype, and more, while providing operations like reshaping and support for ragged batches.4、启动服务器
创建存储库并配置模型后,我们就可以启动服务器了。虽然 Triton 推理服务器可以从源代码构建,但强烈建议在本示例中使用 NGC 免费提供的预构建 Docker 容器。
# Replace the yy.mm in the image name with the release year and month
# of the Triton version needed, eg. 22.08
docker run --gpus=all -it --shm-size=256m --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $(pwd)/model_repository:/models nvcr.io/nvidia/tritonserver:<yy.mm>-py3
# Once Triton Inference Server has been built or once inside the container, it can be launched with the command:
tritonserver --model-repository=/models现在我们的 Triton 服务器已启动,我们可以开始向它发送消息。有三种方式可以与 Triton 推理服务器交互:
- HTTP(S) API
- gRPC API
- Native C API
提高资源利用率的方法包括:
- 动态批处理。参考 Triton 推理服务器,是指允许将一个或多个推理请求组合成单个批处理(必须动态创建)以最大化吞吐量的功能。
- 并发模型执行。Triton 推理服务器可以启动同一模型的多个实例,这些实例可以并行处理查询。Triton 可以根据用户的规范在同一设备(GPU)或同一节点的不同设备上生成实例。这种可定制性在考虑具有不同吞吐量模型的集合时特别有用。可以在单独的 GPU 上生成较重模型的多个副本,以允许更多并行处理。这可以通过在模型配置中使用实例组选项来启用。
5、优化 Triton 配置
模型分析器是一种 CLI 工具,通过扫描配置设置并生成总结性能的报告,帮助更好地了解 Triton 推理服务器模型的计算和内存需求。
使用模型分析器,用户可以:
- 运行可自定义的配置扫描,以确定预期工作负载和硬件的最佳配置。
- 总结有关延迟、吞吐量、GPU 资源利用率、功耗等的发现,并提供详细的报告、指标和图表,这些报告有助于比较不同设置配置之间的性能。
- 定制模型部署以满足用户的服务质量要求,例如特定的 p99 延迟限制、GPU 内存利用率和最小吞吐量!
运行模型分析器:
model-analyzer profile --model-repository /path/to/model/repository生成两种类型的报告:
- 摘要
- 详细报告

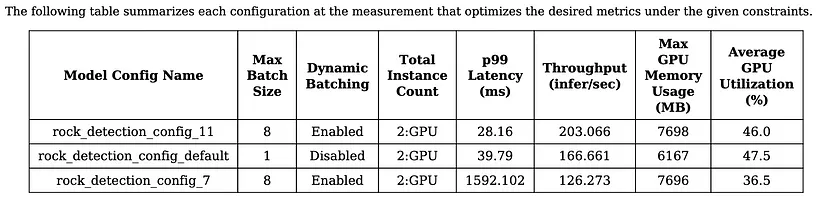
摘要包含所有最佳配置的总体结果。 它包含有关正在使用的硬件、吞吐量与延迟曲线、GPU 内存与延迟曲线的信息以及包含性能数字和其他关键信息的表格。 默认情况下,扫描空间仅限于一定数量的流行功能,例如动态批处理和多个模型实例,但用户可以使用模型配置参数将空间扩展到可以在 Triton 的配置文件中指定的任何功能。
6、加速推理
模型加速是一个复杂而微妙的话题。模型的图形优化、修剪、知识提炼、量化等技术的可行性高度依赖于模型的结构。这些主题中的每一个都是巨大的研究领域,构建自定义工具需要大量的工程投资。
Triton 后端是执行模型的实现。后端可以是深度学习框架的包装器,如 PyTorch、TensorFlow、TensorRT 或 ONNX Runtime。或者后端可以是执行任何操作(例如,图像预处理)的自定义 C/C++ 逻辑。
TensorRT 是优化和加速深度学习模型的最强大工具之一,尤其是在 NVIDIA GPU 上。它通过几个关键策略实现加速:
- 提高吞吐量:每秒执行更多推理,同时减少延迟。
- 降低内存要求:适用于在资源受限的设备上部署模型。
- 可扩展性:轻松从边缘设备扩展到大规模云部署。
- 兼容性:与 Triton Inference Server 无缝集成,实现大规模部署管道。
用户可以使用三种途径将其模型转换为 TensorRT:C++ API、Python API 和 trtexec/polygraphy(TensorRT 的命令行工具)。请参阅这个指南以获取示例。
也就是说,需要两个主要步骤。首先,将模型转换为 TensorRT Engine。建议使用 TensorRT Container 运行命令:
trtexec --onnx=model.onnx \
--saveEngine=model.plan \
--explicitBatch转换后,将模型放入模型存储库中的 model.plan 中(如第 2 和第 3 部分所述),并在 config.pbtxt 中使用 tensorrt 作为后端。
原文链接:Triton Inference Server: yolo deployment
汇智网翻译整理,转载请标明出处
