用AI设计REST API

自 2022 年 11 月推出 ChatGPT 以来,人工智能 (AI) 工具一直在科技界掀起波澜。这些工具的形式和功能差异很大,但其中有一个不变的点,那就是它们旨在改善用户的工作流程和效率。
但是,如果不了解这些工具的工作原理以及如何最好地与它们交互,那么有效使用这些工具可能会很困难。大多数这些工具——尤其是基于 OpenAI 的生成式预训练转换器 (GPT) 模型的工具。这些是大型语言模型 (LLM),其工作方式基本上是接受输入提示并根据训练过的数据预测哪些文本最有可能遵循该提示。
OpenAI 的模型已经接受了大量数据的训练,包括软件工程、编码和系统设计信息。因此,使用这些模型构建的 AI 可以回答您在这些领域和许多其他领域中的问题。
基于 OpenAI Codex 模型的 GitHub Copilot 和 ChatGPT 等 AI 工具被开发人员广泛用于帮助他们编写代码和解决技术问题。然而,由于上下文限制,这些工具在处理更大的软件设计挑战时存在局限性。
这正是 smol developer 等前沿工具发挥作用的地方。Smol developer 是一款基于 GPT-3.5 和 GPT-4 的工具,旨在将 AI 增强的工作流程带入更高级别的软件设计,让你能够根据给定的提示生成整个代码库。
这是开发人员一直在等待的灵丹妙药吗?在本文中,你将亲眼看到。你将学习如何使用 smol developer 迭代地为简单的 RESTful CRUD API 创建规范,AI 将使用该 API 生成代码库。你将能够看到这种方法的优势和局限性,并了解在将这种 AI 纳入你的工作流程之前应该注意的任何陷阱。
1、如何使用 AI 进行 API 设计
在开始本教程之前,需要注意一些事项。
你可以在此 GitHub 存储库中找到此项目的源代码。如果你浏览存储库上的 README,会发现可以通过两种方式运行它。默认方式使用 Modal 来获取按需计算资源。但是,本教程将使用非 Modal 版本,你可以在机器上本地运行 Python 脚本。这意味着你需要遵循的唯一依赖项是:
你还需要确保你的 OpenAI 帐户有一些信用额度或配置了付款方式。每次调用 AI 时,都会向你的 OpenAI 帐户收费。每次运行的成本相当低。例如,编写和调试本文所需的所有运行成本约为 1 英镑 (GBP)。
2、项目设置
安装先决条件后,您可以设置项目。在终端中运行以下命令,将 smol developer 克隆到计算机上,并进入其目录:
bash
git clone https://github.com/smol-ai/developer
cd developer
接下来,运行以下命令使用 pip 安装 Python 依赖项:
bash
pip install -r requirements.txt
此命令运行完成后,你需要将 OpenAI API 密钥导出为终端环境变量,以便脚本可以访问它。通过运行以下命令执行此操作,并替换你的 API 密钥:
bash export OPENAI_API_KEY=<YOUR API KEY>注意:如果你使用的是 Modal,则有一个 ENV 文件包含你的 API 密钥,但如果你在本地运行该工具,代码似乎未设置为从此文件读取。在这种情况下,你需要手动导出 API 密钥。
导出 API 密钥后,可以通过运行以下命令来测试一切是否按预期运行:
bash
python3 main_no_modal.py "a simple hello world application written in nodejs"
注意:根据你的操作系统和 Python 的安装方式,你的可执行文件可能被称为 python3 或 python。本教程中的代码块使用 python3,因此可能需要根据你的设置进行调整。
运行此命令将调用 smol 开发人员工具,该工具将获取你的提示并运行一些初步步骤,为 AI 编写更高级的提示。此工具的工作原理是使用你的提示首先生成 AI 认为创建项目所需的文件列表。
接下来,将这些文件名中的每一个与原始提示一起提供给 AI,此时指示它生成该给定文件的假定内容。对 AI 建议的所有文件重复此过程,如果一切顺利,最终将产生完整的代码库。从之前的输入中,你应该看到一些这样的输出:
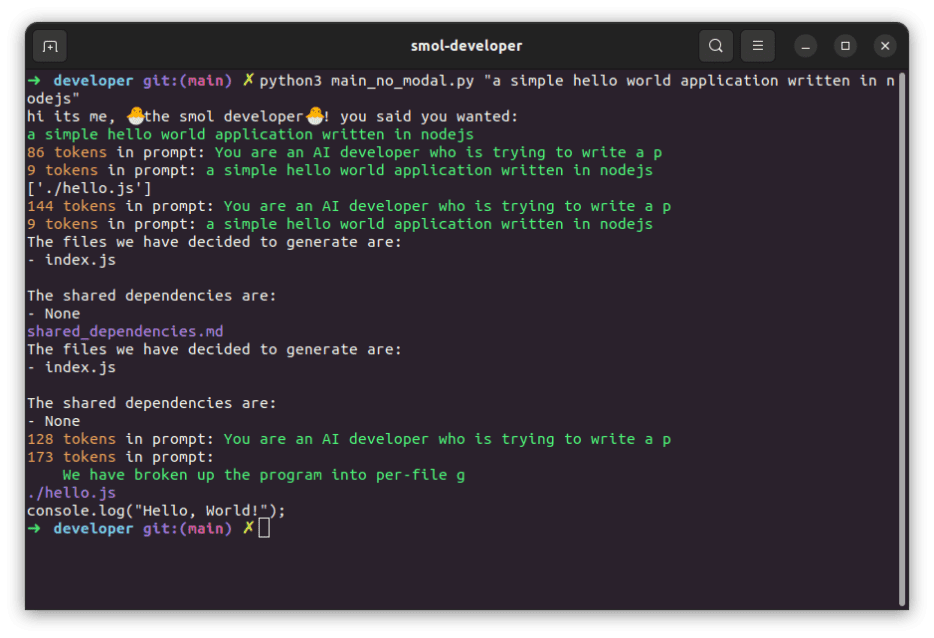
在这种情况下,因为提示非常简单,你可以看到AI已经决定只生成单个文件 index.js,并且文件内容是一个简单的“Hello, World!”控制台日志语句。但是,这可以验证该工具是否正常工作,并且所有内容都已正确连接并准备好用于更高级的用例。
3、定义 API
在要求 AI 构建应用程序之前,你需要对自己想要的东西有一个很好的了解。你很快就会发现,这在使用 AI 驱动的工具时非常重要。AI 可以填补规范中的任何空白,这很快就会导致意外的输出。
试图一次性完全指定所有内容也是不明智的。更温和的方法是迭代构建规范,并在每次添加和修改后通过 AI 运行它,以查看你的更改是否具有预期的效果。
作为基础,你需要知道你正在构建什么。在这种情况下,你要求 AI 构建一个为 Node.js 编写的简单 RESTful API。该 API 是票务管理系统的简单模型,其架构如下所示:
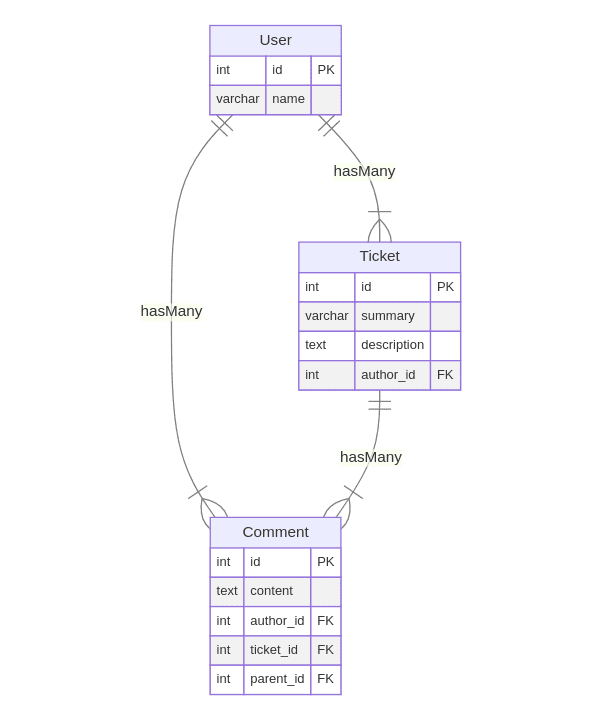
4、构建 API
要开始构建 API,你需要在存储库中创建一个新的 Markdown 文件来保存你的规范。虽然你可以像上一个示例一样直接在命令行中提供提示,但该工具还接受 Markdown 文件,随着规范的大小和复杂性的增加,这些文件更易于使用。
迭代 1
在 repo 的根目录中创建一个名为 my-prompt.md 的文件,并为其提供以下内容:
md
"""
Create a RESTful CRUD API using express.js.
## Resources
The API has the following resources and fields:
### User
- id
- name
### Ticket
- id
- summary
- description
- author_id
### Comment
- id
- content
- author_id
- ticket_id
- parent_id
"""注意:第一行和最后一行的 ””” 通常是必需的,因为如果没有它们,脚本往往会间歇性崩溃,具体取决于 AI 生成的输出。添加这些引号似乎可以缓解这个问题。这段代码是我们可以使用的尽可能少的代码,同时涵盖了您希望 AI 构建的关键细节。要让 AI 执行此规范,请运行以下命令:
bash
python3 main_no_modal.py my-prompt.md
此命令会打印大量输出,指示 AI 当前正在做什么,但它遵循与上一个示例相同的一般步骤。最初,它决定需要哪些文件和依赖项,然后逐个创建文件。
如果你继续操作,为你生成的代码很可能与此处显示的代码不同。这表明了此类 AI 驱动工具的一个问题。具体而言,它们不是确定性的,并且不能保证每次对于给定的输入都获得相同的输出。这将在下一节中展开,但现在,请注意,此处显示的代码将与你生成的代码不同,尽管迭代的总体过程应该非常相似。
代码生成完成后,你可以查看存储库中的 generated/ 目录以查看 AI 创建了什么。在这种情况下,它生成了这些文件:
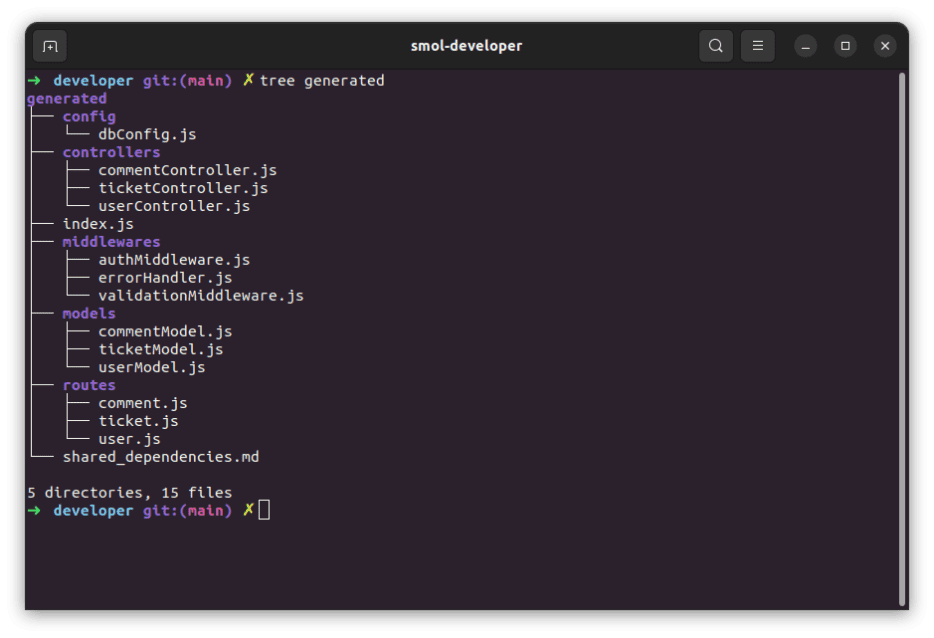
你将看到几个看似与原始提示无关的文件,例如身份验证和验证中间件以及数据库配置文件。对于 index.js 文件,生成了以下内容:
js
// Importing required modules
const express = require('express');
const bodyParser = require('body-parser');
const mongoose = require('mongoose');
const cors = require('cors');
const config = require('config');
// Importing routes
const userRoutes = require('./routes/user');
const ticketRoutes = require('./routes/ticket');
const commentRoutes = require('./routes/comment');
// Initializing the app
const app = express();
// Middleware
app.use(bodyParser.json());
app.use(cors());
// Routes
app.use('/api/users', userRoutes);
app.use('/api/tickets', ticketRoutes);
app.use('/api/comments', commentRoutes);
// Database connection
mongoose.connect(config.get('dbConfig.url'), {
useNewUrlParser: true,
useUnifiedTopology: true,
useCreateIndex: true,
useFindAndModify: false,
})
.then(() => console.log('Connected to database'))
.catch((err) => console.log(`Error connecting to database: ${err}`));
// Starting the server
const port = process.env.PORT || 5000;
app.listen(port, () => console.log(`Server started on port ${port}`));
AI 似乎已决定使用 Mongoose 连接到假定的 MongoDB 实例。有趣的是,从文件树中看不到此处使用验证中间件的迹象。查看 validationMiddleware.js 文件,生成了以下内容:
js
//middlewares/validationMiddleware.js
const { body, validationResult } = require('express-validator');
const validateUser = () => {
return [
body('name').notEmpty().withMessage('Name is required'),
];
};
const validateTicket = () => {
return [
body('summary').notEmpty().withMessage('Summary is required'),
body('description').notEmpty().withMessage('Description is required'),
body('author_id').notEmpty().withMessage('Author ID is required'),
];
};
const validateComment = () => {
return [
body('content').notEmpty().withMessage('Content is required'),
body('author_id').notEmpty().withMessage('Author ID is required'),
body('ticket_id').notEmpty().withMessage('Ticket ID is required'),
body('parent_id').optional(),
];
};
const validationMiddleware = (req, res, next) => {
const errors = validationResult(req);
if (errors.isEmpty()) {
return next();
}
const extractedErrors = [];
errors.array().map((err) => extractedErrors.push({ [err.param]: err.msg }));
return res.status(422).json({
errors: extractedErrors,
});
};
module.exports = {
validateUser,
validateTicket,
validateComment,
validationMiddleware,
};
乍一看,这段代码相当合理。但是,在生成的代码中搜索这些函数中的任何一个都会发现它们在任何地方都没有使用过。这表明这种工具的第二个问题:上下文有限。由于每个文件都是单独生成的,因此 AI 生成从未使用过的函数或生成函数然后通过提供不正确或不匹配的参数来滥用它们的情况并不少见。下一节将对此进行详细介绍。
目前,最好的做法是向规范添加更多细节,然后重试。
迭代 2
此迭代中要解决的主要问题是删除不需要的验证和数据库代码。通过按如下方式更新规范来执行此操作,并添加“调整”部分以包含 AI 的额外指令:
md
"""
Create a RESTful CRUD API using express.js.
## Resources
The API has the following resources and fields:
### User
- id
- name
### Ticket
- id
- summary
- description
- author_id
### Comment
- id
- content
- author_id
- ticket_id
- parent_id
## Adjustments
- Do not validate requests or responses
- Do not use a database, just use an array as a datastore for now
"""
通过 AI 运行此提示后,将生成以下文件:
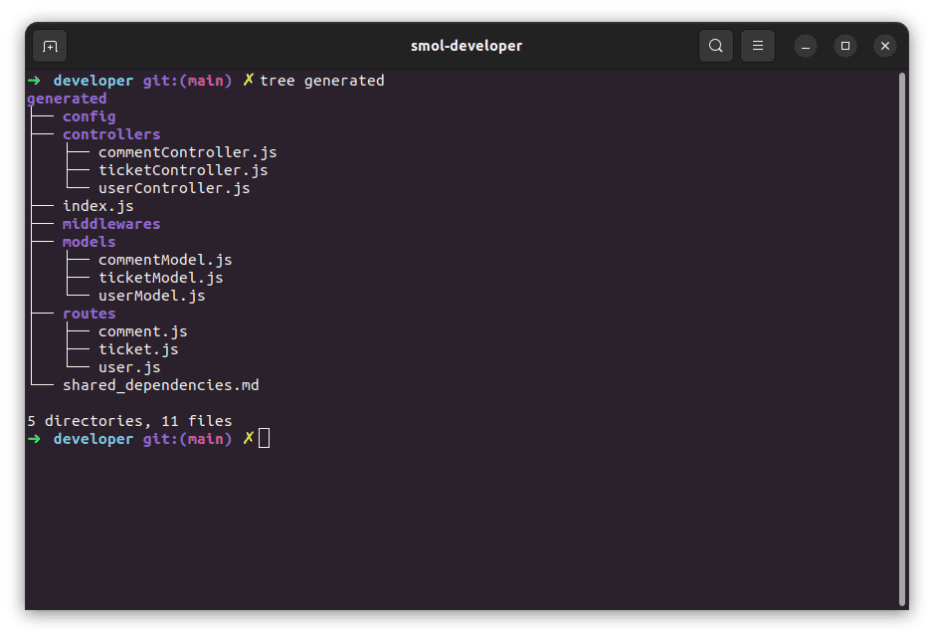
注意:每次运行该工具时,它都会从生成的/目录中删除所有现有文件,但不会删除目录本身。你看到的任何空目录都只是以前运行的残留物。
这看起来符合新规范。同样,对于 index.js,已生成以下代码:
js
const express = require('express');
const bodyParser = require('body-parser');
const uuid = require('uuid');
const userRoutes = require('./routes/user');
const ticketRoutes = require('./routes/ticket');
const commentRoutes = require('./routes/comment');
const userController = require('./controllers/userController');
const ticketController = require('./controllers/ticketController');
const commentController = require('./controllers/commentController');
const userModel = require('./models/userModel');
const ticketModel = require('./models/ticketModel');
const commentModel = require('./models/commentModel');
const app = express();
const PORT = process.env.PORT || 3000;
app.use(bodyParser.json());
// User routes
app.get('/users', userRoutes.getAllUsers);
app.get('/users/:id', userRoutes.getUserById);
app.post('/users', userRoutes.createUser);
app.put('/users/:id', userRoutes.updateUser);
app.delete('/users/:id', userRoutes.deleteUser);
// Ticket routes
app.get('/tickets', ticketRoutes.getAllTickets);
app.get('/tickets/:id', ticketRoutes.getTicketById);
app.post('/tickets', ticketRoutes.createTicket);
app.put('/tickets/:id', ticketRoutes.updateTicket);
app.delete('/tickets/:id', ticketRoutes.deleteTicket);
// Comment routes
app.get('/comments', commentRoutes.getAllComments);
app.get('/comments/:id', commentRoutes.getCommentById);
app.post('/comments', commentRoutes.createComment);
app.put('/comments/:id', commentRoutes.updateComment);
app.delete('/comments/:id', commentRoutes.deleteComment);
app.listen(PORT, () => {
console.log(`Server running on port ${PORT}`);
});乍一看,这个看起来更好,因为它不包含不需要的中间件。但是,如果没有编辑器为您突出显示它,很难分辨,但此文件包含几个未使用的导入,具体如下:
- uuid
- userController
- ticketController
- commentController
- userModel
- ticketModel
- commentModel
此外,路由声明似乎有些不对劲,因为它们引用的函数在悬停时不会推断任何函数签名。当你打开其中一个路由文件(例如 routes/user.js)时,问题就很明显了:
js
// Import necessary modules
const express = require('express');
const router = express.Router();
// Import user controller
const userController = require('../controllers/userController');
// Define routes for user resource
router.get('/users', userController.getAllUsers);
router.get('/users/:id', userController.getUserById);
router.post('/users', userController.createUser);
router.put('/users/:id', userController.updateUser);
router.delete('/users/:id', userController.deleteUser);
// Export router
module.exports = router;
路由文件不导出 index.js 代码尝试使用的函数(尽管控制器导出与这些名称匹配的函数)。实际上,此代码不会运行,因为文件之间使用的模式不匹配。应该可以通过在规范中更具体来解决这个问题。
迭代 3
要向规范添加更多细节以获得更一致的输出,请在 ### Comment 标题之后和 ## Adjustments 标题之前将以下部分添加到你的规范中:
md
## Module structure
Each module (users, tickets, and comments) should use the following structure. "User" is used as an example, and the name should be changed appropriately for each given module.
- modules
- users
- userRoutes.js
- userController.js
- userService.js
### userRoutes.js
This file should be used in the `index.js` like so:
// index.js
app.use('/users', userRoutes);
The file itself should contain mappings between a given endpoint and the controller method that serves it, like this:
// modules/users/userRoutes.js
router.get('/', userController.getAllUsers);
router.get('/:id', userController.getUserById);
router.post('/', userController.createUser);
router.put('/:id', userController.updateUser);
router.delete('/:id', userController.deleteUser);
### userController.js
This file should serve as an HTTP adapter, and should invoke business logic from the `userService`. This file should declare the following functions:
- getAllUsers
- getUserById
- createUser
- updateUser
- deleteUser
Each of these functions should invoke the function of the same name from the corresponding service.
### userService.js
This file should house the business logic for the module. This file will declare the following functions:
- getAllUsers
- getUserById
- createUser
- updateUser
- deleteUser添加有关模块结构的详细信息后,再次运行 AI。这次,生成了以下文件:
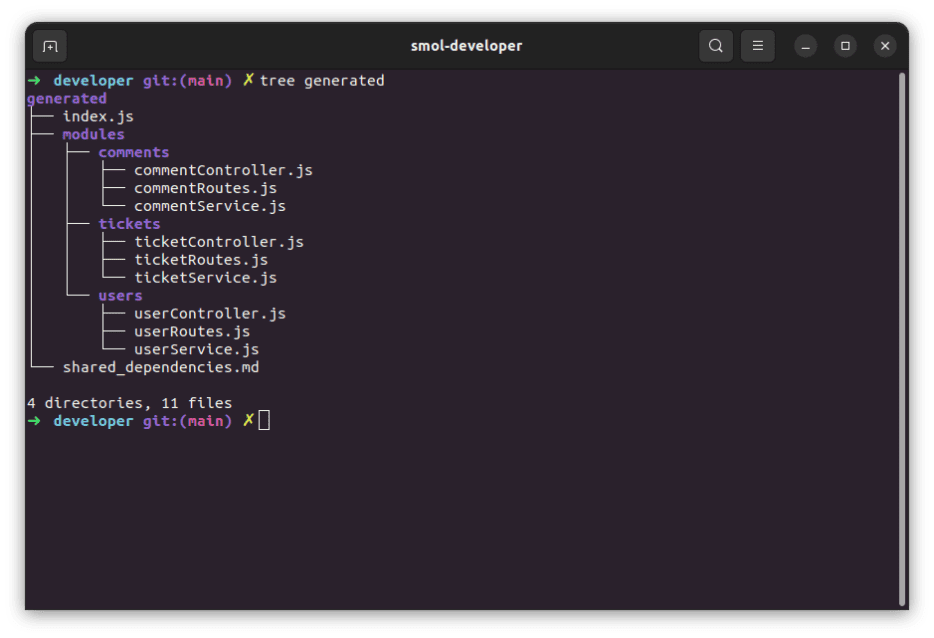
这与提示中指定的内容相匹配,这是一个好的开始。检查 index.js,看起来所需的更改已实现:
js
const express = require('express');
const app = express();
const userRoutes = require('./modules/users/userRoutes');
const ticketRoutes = require('./modules/tickets/ticketRoutes');
const commentRoutes = require('./modules/comments/commentRoutes');
app.use(express.json());
app.use('/users', userRoutes);
app.use('/tickets', ticketRoutes);
app.use('/comments', commentRoutes);
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => console.log(`Server running on port ${PORT}`));不幸的是,此迭代有两个主要问题。 _Ticket_ 模块似乎基本正确,遵循了每个文件中应定义哪些函数的规范。但是, _User_ 和 _Comment_ 模块并非如此,它们在其 _routes_ 和 _controllers_ 中调用 Express router,如下所示:
js
// modules/users/userRoutes.js
const express = require('express');
const router = express.Router();
const userController = require('./userController');
router.get('/', userController.getAllUsers);
router.get('/:id', userController.getUserById);
router.post('/', userController.createUser);
router.put('/:id', userController.updateUser);
router.delete('/:id', userController.deleteUser);
module.exports = router;js
// modules/users/userController.js
const express = require('express');
const router = express.Router();
const userService = require('./userService');
router.get('/', (req, res) => {
const users = userService.getAllUsers();
res.send(users);
});
router.get('/:id', (req, res) => {
const user = userService.getUserById(req.params.id);
res.send(user);
});
router.post('/', (req, res) => {
const user = req.body;
userService.createUser(user);
res.send('User created successfully');
});
router.put('/:id', (req, res) => {
const user = req.body;
userService.updateUser(req.params.id, user);
res.send('User updated successfully');
});
router.delete('/:id', (req, res) => {
userService.deleteUser(req.params.id);
res.send('User deleted successfully');
});
module.exports = router;这意味着这些模块不起作用,运行时会导致应用程序崩溃。奇怪的是 _Tickets_ 模块的结构符合规范。这可能与 AI 的上下文限制有关,但无法确定。
5、进一步的步骤
这个过程可能会持续很长时间,才能产生完全正确且能够运行的东西。在测试期间,即使是最有希望的生成输出仍然有一些需要手动修复的问题。
如果你一直在关注,请尝试进一步优化提示,看看是否可以获得更符合您预期的输出。但是,请注意,这可能非常快、很慢或介于两者之间。
下一节将研究从这个过程中获得的一些经验,以确定像这样的 AI 驱动工具在这个早期阶段有多有用。
6、发现和观察
Smol developer是一个令人印象深刻的工具,超越了其他 AI 编码工具目前提供的功能。大多数其他工具(例如 Copilot)仅限于生成单行或代码块,而不是整个代码库。但是,由于它还很年轻,因此从生产力和效率的角度来看,需要解决一些问题:
- 非确定性
使用基于 LLM 的 AI 工具面临的最大挑战之一是缺乏严格的确定性。对于像 Copilot 这样的工具来说,这通常不是问题,因为您可以一次生成小段代码,开发人员有责任负责任地整合它们。
但是,在生成整个代码库时,这更是一个问题。非确定性意味着生成的代码可能永远不会以相同的方式生成,当你需要反复更改规范并重新生成代码时,这尤其具有挑战性。
这也使规范的价值和作用受到质疑。正如你所见,AI 仍然会犯错误,即使是关于规范中明确提到的事情。再加上从给定规范生成的输出可能会发生变化,规范更像是一个建议,而不是真相来源。
- 缺乏上下文
一般来说,AI 工具往往存在上下文问题。这些工具不知道业务领域或大多数周围的代码。因此,像 Copilot 这样的工具经常会给出一些不合理的建议,你必须小心接受哪些建议。
相比之下,smol developer是从头开始创建代码库的,因此,你可以理所当然地认为它可以访问整个上下文。然而,smol developer仍然一次只生成一个文件,因此很容易犯类似的错误。例如,即使在迭代 3 中,服务函数上定义的函数签名与调用函数的位置也不匹配:
js
// modules/tickets/ticketService.js
function createTicket(ticket) { // 1 argument
const newTicket = { id: tickets.length + 1, ...ticket };
tickets.push(newTicket);
return newTicket;
}
// modules/tickets/ticketController.js
const createTicket = (req, res) => {
const { summary, description, author_id } = req.body;
const ticket = ticketService.createTicket(summary, description, author_id); // 3 arguments
res.send(ticket);
};如果你无法在规范中解决此问题,则此类问题可能会导致代码需要大量手动返工。
Smol developer可以使用 GPT-3.5-turbo 或 GPT-4 运行。不幸的是,在撰写本文时,GPT-4 仍处于封闭测试阶段,而 GPT-3.5-turbo 可用。与 GPT-4 相比,GPT-3.5-turbo 通常更难保持上下文。 smol developer的作者指出,使用 GPT-4 时,这方面的性能会更好,因此如果你可以访问它,则应该使用它。
- 一致性
与上下文问题类似,一致性问题也并不少见。具体来说,在迭代 3 中,尽管在概述每个模块结构的规范中,_tickets_ 模块是按规定生成的,而其他两个模块则不是。这使得问题特别难以调试。这不仅仅是规范不足的情况,因为其中一个模块是按规定生成的。这个可重复一致性的问题可能与下一点有关。
- 标准化
与依赖严格定义的标准和语法的传统编码不同,LLM AI 接受不受约束的文本输入。没有标准化的描述语言可以用来向 AI 传达你的绝对意图。你获得的输出完全取决于 AI 对你的单词的不确定解释。这使得它成为构建应用程序的困难基础,并且你获得的代码的质量在某种程度上取决于您的规范,同样也取决于运气。
7、结束语
本文展示了如何利用 LLM AI 工具来帮助 API 设计和开发过程。在这里,你已经看到了像 smol developer 这样的前沿工具如何根据你提供的规范快速创建大量代码,并且你已经看到了如何迭代调整这些规范以使输出朝着你期望的结果移动。AI 工具已经在许多开发人员的工具集中站稳了脚跟,并且不太可能很快消失。
但是,承诺为你创建整个代码库的工具在适合生产使用之前还有很长的路要走。当前这一代 AI 开发人员工具缺乏构建稳定产品所需的一些关键基础,例如确定性、一致性以及指导他们构建什么的标准化方式。这些方面可能会随着时间的推移而继续改进,因此虽然这样的工具可能还没有准备好用于黄金时段,但从技术角度来看它们仍然非常令人印象深刻,值得关注。本文的所有提示和生成的代码都可以在这个公共 GitHub 存储库中找到。
汇智网翻译整理,转载请标明出处
