DiffRhythm开源歌曲生成模型
新的开源歌曲生成模型DiffRhythm看起来非常疯狂,它可以在短短10秒内生成长达4分钟的完整歌曲,包括人声。

尽管GROK-3和GPT-4.5之间的最佳模型之战仍在继续,一个新的开源歌曲生成模型DiffRhythm已经推出,并看起来非常疯狂。它可以在短短10秒内生成长达4分钟的完整歌曲,包括人声。
永别了音乐产业
1、什么是DiffRhythm?
DiffRhythm是一个开创性的歌曲生成模型,能够合成完整的歌曲,包括人声和伴奏。它是第一个基于潜在扩散的模型,能够在仅仅10秒内生成长达4分钟45秒的完整歌曲。
专为简单性、可扩展性和效率设计,DiffRhythm解决了音乐生成中的关键挑战,如:
将人声和伴奏无缝结合
维持长期音乐连贯性
实现快速推理速度
2、DiffRhythm如何工作
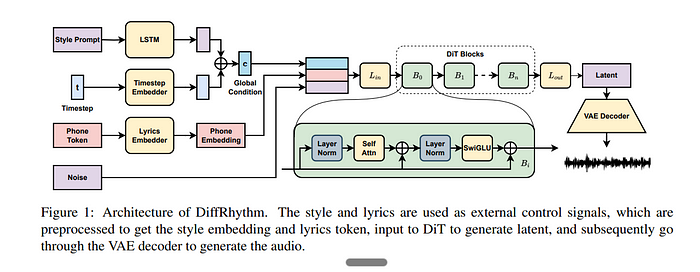
DiffRhythm通过两阶段过程运作,利用 变分自编码器(VAE)和扩散变压器(DiT) 高效地生成高质量音乐。
2.1 变分自编码器(VAE)
VAE将原始音频压缩到一个紧凑的潜在空间,同时保持感知质量,减少建模长音频序列时的计算复杂度。
VAE的关键方面:
优化用于频谱重建和对抗训练以增强音频保真度
训练处理MP3压缩伪影,允许从有损输入中进行高质量重建
与Stable Audio VAE共享相同的潜在空间,确保与现有潜在扩散框架兼容
2.2 扩散Transformer(DiT)
DiT通过逐步去噪潜在表示来生成歌曲,这些表示是根据歌词和风格提示进行条件化的。
什么是扩散Transformer?
扩散Transformer(DiT)是一种生成数据(如图像、音频或文本)的模型,通过逐步将噪声精炼成有意义的输出。它通过多次重复去除随机噪声,由条件(如文本或风格提示)引导。DiTs因其结合了扩散模型的迭代精炼和Transformer的灵活性和可扩展性而强大,使其适用于复杂的任务,如歌曲或图像生成。
DiT的关键方面:
- 条件化于三个输入:
风格提示(控制歌曲类型/风格)
时间步(指示当前扩散步骤)
歌词(指导人声生成)
- 使用LLaMA解码层优化自然语言处理
- 采用FlashAttention2和梯度检查点以提高效率
2.3 歌词到潜在对齐
为了确保人声准确地与歌词对齐,DiffRhythm引入了一个句子级别的对齐机制,减少了对广泛监督的需求,并提高了歌词和稀疏人声段之间的连贯性。
3、DiffRhythm的关键特性
- 端到端歌曲生成
在仅10秒内生成长达4分45秒的完整歌曲,保持音乐性和可理解性。
- 简单且可扩展的架构
消除了复杂多阶段级联管道的需求,使其更容易扩展和部署。
- 极速推理
由于其非自回归设计,DiffRhythm优于传统的自回归模型,后者在生成长篇内容时往往较慢。
- 对MP3压缩的鲁棒性
由于VAE是在MP3伪影上训练的,即使是从有损输入中,它也能重建高质量音频——非常适合现实世界的应用。
- 歌词到人声对齐
使用句子级别的对齐机制确保人声准确匹配歌词,即使在人声稀疏的情况下也是如此。
- 开放且可访问
DiffRhythm的训练代码、预训练模型和数据处理管道都是公开可用的,促进了AI驱动的音乐生成中的可重复性和研究。
4、如何使用DiffRhythm?
该应用已免费部署在HuggingFace上,模型权重在这里提供。
5、结束语
DiffRhythm是AI驱动的音乐生成领域的一个变革者,证明了全长度、高质量的人声歌曲可以在短短几秒钟内生成。凭借其基于潜在扩散的方法、快速推理速度和开放源代码的可访问性,该模型为AI音乐生成设定了新的基准。
无论你是艺术家、制作人还是只是对AI对音乐的影响感兴趣的人,DiffRhythm都为你提供了未来的一瞥——在这里,创作音乐就像生成文本一样简单。随着AI生成的内容不断推动创意边界,有一件事是肯定的:音乐产业将永远改变。
想自己试试吗?在Hugging Face上查看它,并亲身体验AI歌曲生成的未来。
原文链接:DiffRhythm: Full-length AI song Generation (4 min) with vocals
汇智网翻译整理,转载请标明出处
